
上周我们讲了 Databricks 和 Snowflake 同周掏出 AI 编程代理,数据岗位在被迫升级。
发布会开完了,PPT 也都刷屏了。但每次这种时候我都忍不住想问一句——这些东西,到底在谁家真的跑起来了?
这一周恰好看到几篇海外大厂的实战复盘,结论有点意外:跑起来了,但跑得很”土”。真正在生产里发挥作用的,都不是 PPT 上画满箭头的 Agent 编排架构,而是几个死磕具体问题的小工程。
这篇不讲理论,只讲谁真的做成了什么。
行业动态:Agent 真正落地的样子
Meta:50 个 Agent 组队啃 4100 个文件的老管道
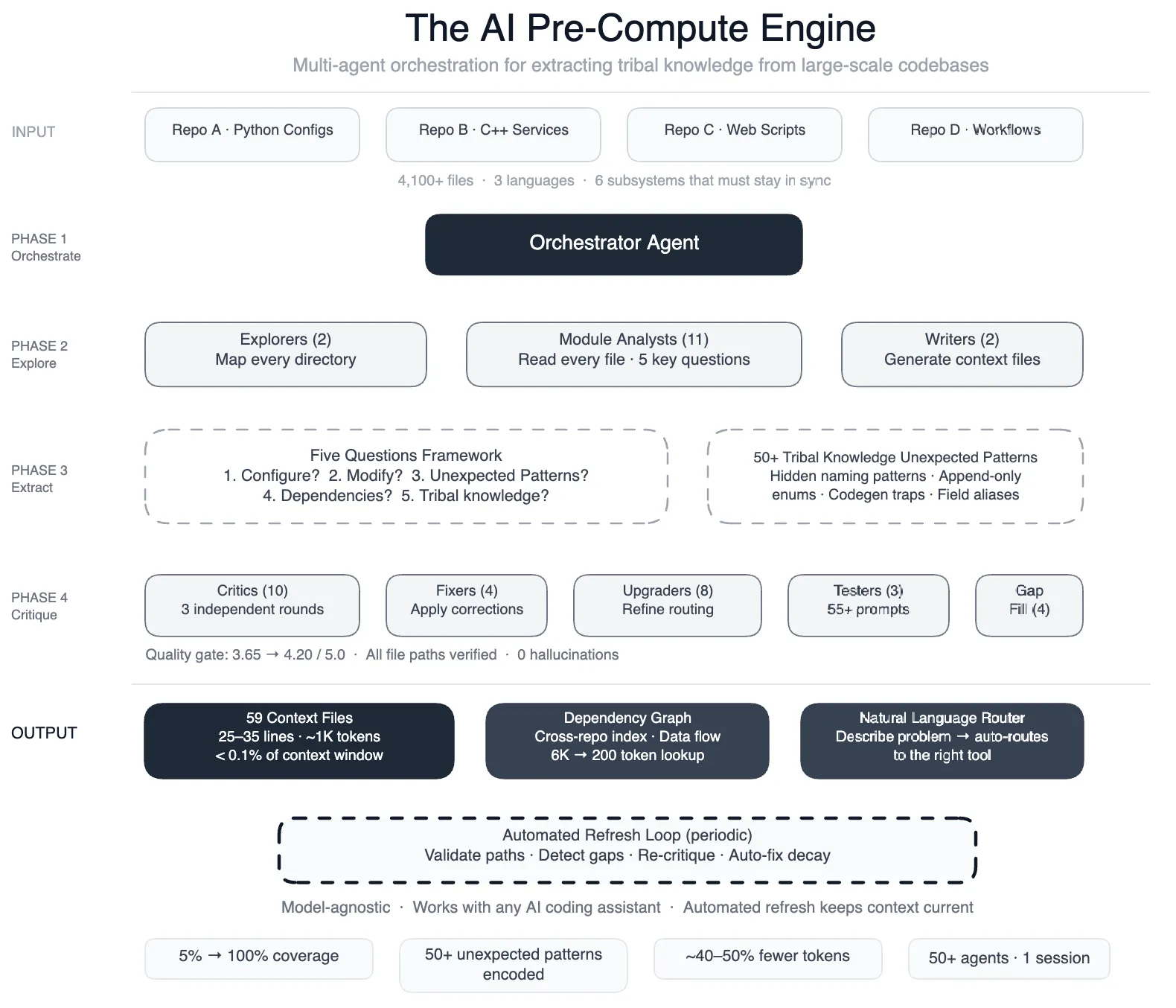
Meta 数据工程团队放出一篇文章,讲他们怎么用 AI 解决一个所有大厂都有的老病——老数据管道的”部落知识”问题。
具体场景:一个跑了几年的数据管道,4100 个代码文件,原作者早就离职。新工程师接手要改一个字段,得先花 2 天时间读代码、问人、跑测试,才能搞清楚这个字段从哪儿来到哪儿去。
他们的解法不是搞一个大 Agent,而是50 个专门化的小 Agent 组成一个群组,每个 Agent 只负责一个窄任务(解析某种文件、提取某种依赖、识别某种模式),然后把结果汇总成一份”上下文文档”。
调研时间从 2 天压到 30 分钟。
原文:How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines · Meta Engineering
拾穗视角:这个方案对国内团队的启发不是”我也得上 50 个 Agent”,而是**“不要试图让一个 Agent 做完所有事”**。国内很多团队现在做 AI 项目,上来就想搞一个通用的”数据助手”,结果每一步都做不好。Meta 这套思路更像流水线——把大问题切成窄任务,每个 Agent 负责一个细小的动作。这和十几年前 Unix 哲学是同一回事:“做一件事,做好。”
顺便,如果你们公司也有”原作者离职、没人敢动”的老管道,这是个可以直接抄作业的场景。
Netflix:用缓存把重复查询成本降三分之一
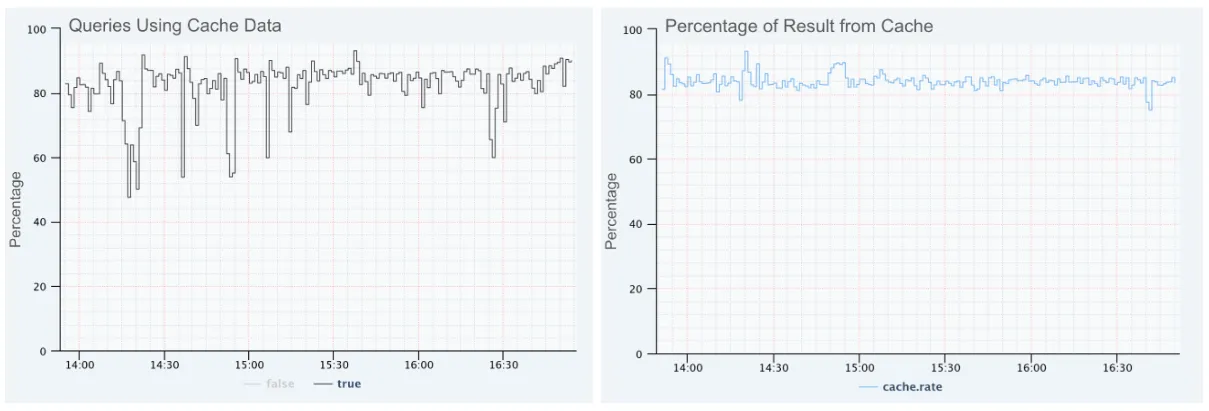
Netflix 讲了他们怎么优化 Druid 上的滚动窗口查询。过去 1 小时、过去 24 小时这种查询,每次触发都要把完整窗口重算一遍,哪怕只有最新一分钟的数据是新的。
他们做了个缓存代理,把窗口拆成分钟桶,只重算最新的那一桶,其余从缓存拿。命中率 82%,查询量降了 33%。
原文:Interval-Aware Caching for Druid at Netflix Scale · Netflix Tech Blog
拾穗视角:这种工程优化没什么”创新”,但这种东西恰恰是国内很多数据团队缺的——不愿意花时间做的”脏活”。一个缓存代理,没什么论文发,但能帮公司省实打实的算力钱。Netflix 的数据工程师一直比较”老派”,讲究把基础设施打磨得贼顺手。这一点值得国内团队学。
Databricks:Spark 4.1 Real-Time Mode,毫秒级
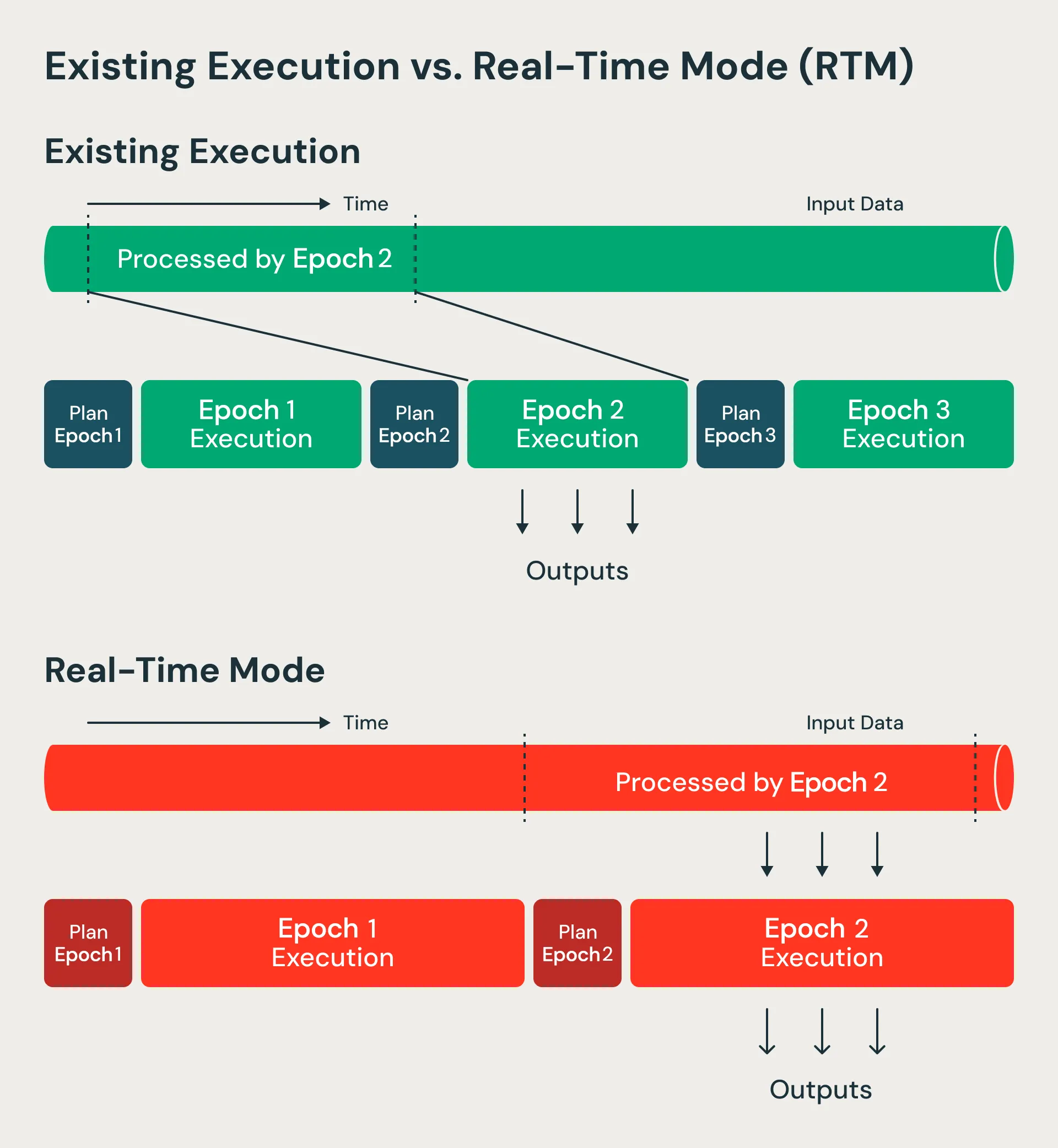
Databricks 上个月底发布了 Spark 4.1 的 Real-Time Mode,把延迟从秒级降到 100ms 以下。核心改动是用更长的 epoch、并发阶段和非阻塞算子,统一了吞吐和低延迟两种诉求。
原文:Breaking the Microbatch Barrier · Databricks
拾穗视角:过去 Spark 和 Flink 的分工很明确——Spark 批、Flink 流。Spark Streaming 只是 microbatch,做不了真流。这次 Real-Time Mode 的意思是 Databricks 想把 Flink 的饭也抢过来。国内做实时数仓的团队可以观察一下:如果 Spark 真能做到 100ms,之前为了实时专门引入 Flink 的技术栈负担,可能真的会减轻。但这一天还没到——Flink 在真正的事件驱动场景仍然更成熟。
职业与观察:Data Scientist 为什么在 AI 时代反而更值钱
Hamel Husain:数据科学家的复仇
Hamel Husain(老牌 ML 工程师,前 GitHub、Airbnb)写了一篇爆款博客,标题叫 “The Revenge of the Data Scientist”。
他的论点是:过去两年大家都在讨论 AI 工程师,觉得 Data Scientist 要被时代抛弃。但实际生产里,AI 产品的瓶颈不在会不会写 prompt,而在会不会做 eval、会不会设计实验、会不会分析生产 trace——这些恰恰是传统数据科学家的核心技能。
他举了一个具体例子:某 AI 产品团队一开始用”AI 工程师”写 prompt,上线后错误率 30%,不知道怎么降。后来加进一个数据科学家,做了一周的 eval 体系和 trace 分析,找到 3 个可以系统性优化的点,错误率降到 8%。
原文:The Revenge of the Data Scientist · Hamel Husain
拾穗视角:这和我们上周说的”数据岗被迫升级”正好是两面——升级不是让数据人变成 AI 工程师,而是让数据人把自己的老本行用到 AI 产品上。国内很多公司现在招”AI 产品工程师”,但干到后面发现真正能把 AI 产品质量做起来的,都是那些懂实验设计、懂数据分析的老派数据科学家。
如果你是数据人,不用焦虑 AI 抢饭碗。你该学的是怎么把你原来做 AB test、做 causal inference 的本事,搬到 AI 产品上。
BlaBlaCar:让 PM 用 AI 自助取数,错误率从 32% 降到 15%
法国拼车公司 BlaBlaCar 做了个面向 PM 的 AI 取数工具。关键不是用了多牛的模型,而是做了一份结构化的 schema 文档 + few-shot 示例库。
PM 问”上季度巴黎到里昂的用户留存是多少”,AI 生成的 SQL 一开始错误率 32%。加上结构化 schema 文档后降到 15%。PM 的取数需求从”提工单给数据组”变成”自己搞定”。
SQL 错误率:初始 32% → 加 schema 文档 + few-shot 后 15% 角色变化:PM 从”等数据组排期”到”自助查询” 关键不是模型:用的就是通用大模型,赢在 schema 文档的打磨
原文:How BlaBlaCar PMs use AI to self-serve data · BlaBlaCar Engineering
拾穗视角:这里面有一个国内团队常常忽略的点——“让 AI 会写 SQL”和”让 AI 写出你公司业务口径的 SQL”是两件事。你司的表里叫 user_id 其实是 device_id,字段注释十年没更新,这种情况下任何大模型都会瞎猜。
真正让 Text-to-SQL 可用的,从来不是模型强弱,而是你有没有花时间把 schema 文档整理清楚。这是个苦工,但做完之后收益长期存在。
观点辩论:MCP 到底行不行?
这周海外圈子围绕 MCP(Model Context Protocol)吵了一架。一边是 Pinterest 晒战绩,另一边是一个前 AWS 的老工程师泼冷水。
Pinterest:MCP 月调用 66k 次,节省 7000 工时
Pinterest 讲他们构建了一整套 MCP Agent 服务器生态,配了 JWT + SPIFFE 的安全机制。月调用量 66000 次,累计帮工程师节省了 7000 小时。
Julien Simon:MCP 在企业级还差关键件
前 AWS 主力布道者 Julien Simon 同一周发了一篇 “Still Missing Critical Pieces”,几乎是逐条反驳。
他的核心论点:MCP 在企业级场景下有三个硬伤——
- Token 开销:每次 Agent 调用都要把大量上下文塞进 prompt,成本高
- 黏性路由:多 Agent 协作时 session 状态不好管
- 治理缺失:没有细粒度权限、审计、版本管理
他的观察是:真正跑在生产上的企业级 AI 系统,反而更倾向直接调 API + 代码生成,而不是用 MCP。
拾穗视角:这两边我看都是对的。Pinterest 那种场景——内部工具调用、单租户、工程师自己用——MCP 跑得很好。Julien 说的场景——多租户、强治理、审计合规——MCP 还没到。
国内团队如果现在要做 Agent 体系,可以这么想:
- 如果是工程师内部工具(调代码、查日志、跑任务),用 MCP 完全 OK,甚至推荐
- 如果是面向业务的 Agent 产品(涉及客户数据、需要权限隔离),老老实实用 REST API + 自己写 orchestration
别被”MCP 是未来”这种话忽悠住,选型永远是看你的场景,不是看哪个标准最时髦。
一个反直觉的故事:Markdown 文件如何干翻 5000 万美元的向量库
这是本期我最喜欢的一篇。
一个独立开发者 Michael Lanham 发了篇帖子,标题直接挑衅:“The Markdown File That Beat a $50M Vector Database”。
事情是这样的:他在做一个单线程的 Agent 工作流,一开始用了某家估值 50M 美元的托管向量数据库,每月账单高得离谱。后来他试了一把把所有文档塞进一个大 Markdown 文件,配上开源的 sqlite-vec,跑在本地一个 SQLite 文件里。
结果:
- Token 成本降到托管向量库的 1/10
- 延迟下降(本地查询 vs 网络调用)
- 查询准确率没有下降
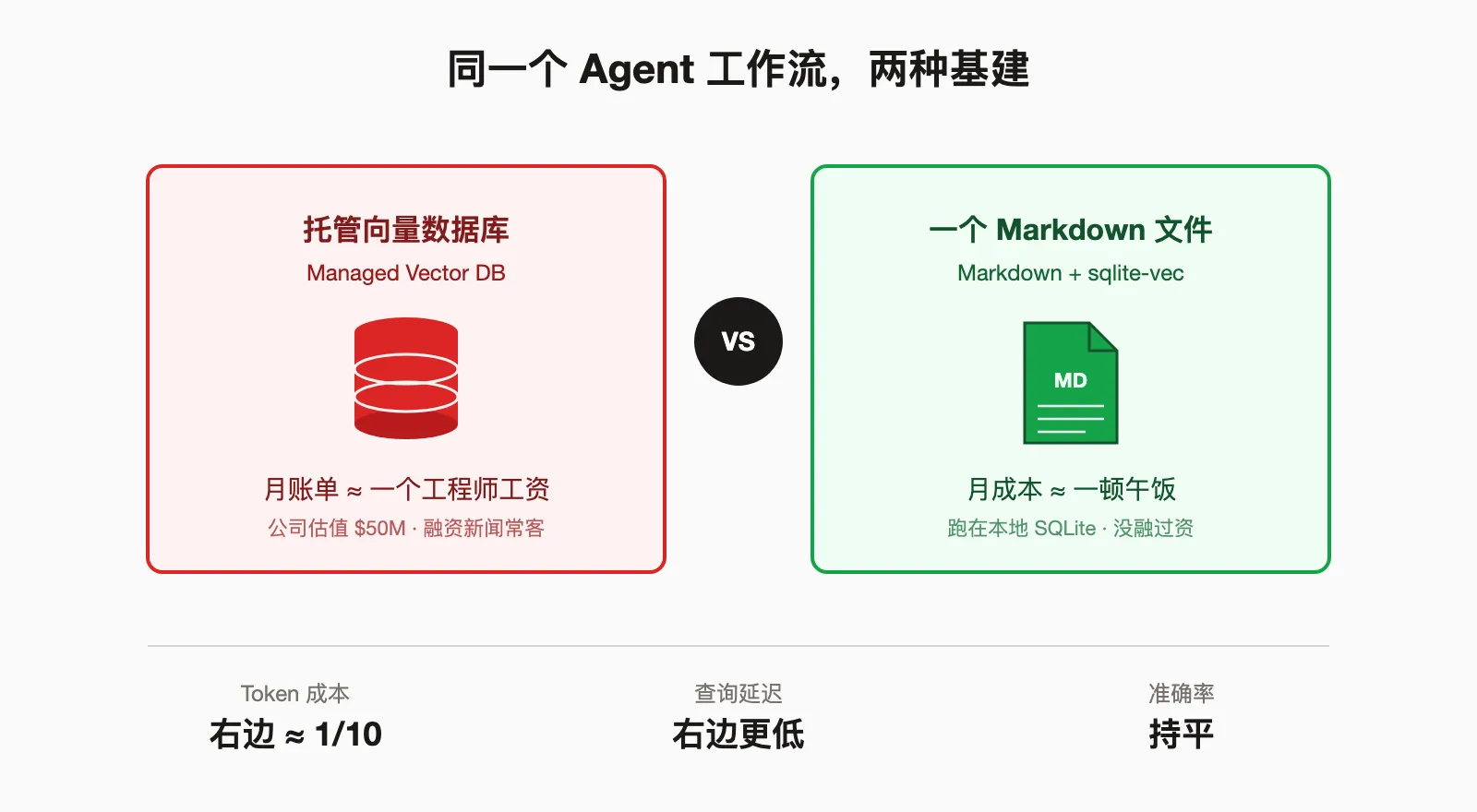
他的结论是:对大多数 Agent 场景,你根本不需要”向量数据库”。你需要的是”结构化的上下文 + 一点 embedding search”。
拾穗视角:去年一整年,向量数据库公司融了多少钱?Pinecone、Weaviate、Chroma、Milvus、Zilliz,随便一家都是几千万美元估值。但现在越来越多的实战反馈是——对中小 Agent 项目,向量数据库是过度工程。
这个故事的真正启发是:技术选型要看实际负载,不要被融资新闻带偏。你的 Agent 每天处理 1000 个查询,用 SQLite + sqlite-vec 就够了;非要上 Pinecone,账单一个月能烧掉一个工程师的工资。
国内同理——如果你们公司正在评估向量数据库,先问自己:“我们的 QPS 真的到那个量级了吗?“没到就别上,老老实实用 PostgreSQL 的 pgvector 扩展,能省一大笔。
拾穗判断:跑得下去的 Agent,长得没什么气势
写完这一周的内容,我顺手把几篇文章甩给一个老朋友。他在一家中型银行带数据团队,去年立项了一个”数据智能体平台”,目标是”一个入口解决所有数据问题”。投了七八个人、干了大半年,还没上线。他读完 Meta 和 BlaBlaCar 那两篇,回我一句:“所以我们方向一开始就错了。”
其实错的不只是他们这一家。是这两年整个行业都默认一件事——做 AI 要做得”大”,要有”平台感”,要能”覆盖所有场景”。但翻完这一周的海外复盘才发现,真正跑下来的 Agent 全是反过来的:窄、小、专一,拒绝万能。Meta 用 50 个小 Agent 拼出一份上下文文档;Pinterest 把 MCP 拆成一个个服务器,只给工程师内部用;BlaBlaCar 的 AI 只解决 PM 自助取数这一件事。没有一个是”公司级助手”。
这里面有一个挺朴素的道理——能长期跑起来的系统,长得往往都不气派。就像我老家小区门口修了二十年的自行车摊,摊子看起来毫无章法,但什么车都能修。而那些 PPT 上画得满满当当、箭头飞来飞去的”AI 中台架构图”,经常是做给领导看的,不是做给工程师用的。
另一件让我感慨的,是 Hamel 那篇”Data Scientist 的复仇”。过去两年,身边不少数据分析师、数据科学家都在焦虑——是不是该转 AI 工程师了?要不要学 LangChain?要不要刷大模型证书?但真正把 AI 产品质量撑起来的人,往往还是那些会做 eval、会设计实验、会盯 trace 的老派数据人。你原先在 AB 测试里较过的真、在因果推断里想过的事,到了 AI 产品时代反而比任何时候都值钱。这不叫”风口回来了”,这叫”基本功没过期”。
最后一件事是关于钱。2023 年我陪一位朋友的公司做技术选型,他们坚持要上 Pinecone,理由是”大厂都在用”。那时候每月账单能顶一个中级工程师的工资。到了今年,这位独立开发者用 Markdown + sqlite-vec 把类似的活儿干了,成本降到 1/10,准确率没掉。很多事情都是这样的——风潮过去之后你才会发现,当初跟着跑的那群人,连方向都是别人指的。
如果让我给这一期做一个收束,大概就是一句话:Agent 时代最稀缺的不是新技术,是敢把事情做小的勇气。
📬 如果你在往下想这件事……
本期我自己最想再往下挖的,是 Meta 那个 50 个 Agent 群组——搬到 50 到 200 人的国内数据团队,到底要怎么切分?需要几个人?几个月?预算大概多少?
这不是随手能回答的问题。得攒几个真实案例,把成本账本算清楚,才值得写。
如果你们团队正在考虑类似的事,或者只是好奇国内能不能抄,欢迎直接加我微信聊聊(微信号:shisuidata,加的时候麻烦备注一下”数据周刊”)。攒够几位读者我就专门做一期深度拆解,讲落地路径 + 预算账本。
这类深度稿往后可能会作为拾穗 Pro 的专享内容,但现阶段拾穗所有内容都免费,我只是先收集”真在乎这事的人”。
本周其他值得看的
- Beyond ETL - The Case for Context:Airbyte 创始人提出 Context Store 概念,认为 Agent 时代的数据基建核心从”数据搬运”转为”上下文管理”
- Medallion Architecture Isn’t As New As You Think:一篇辩论文章,说 Bronze/Silver/Gold 就是分阶段建模的马甲
- State of Context Engineering in 2026:管理 LLM 上下文极限的 5 种模式,很系统
- Zapier outbox pattern at scale:基于 SQLite 的 outbox 模式,稳定支撑 15000 event/s,极简工程美学
- Taming S3 Shuffle at Scale:S3 shuffle 成本降 95%,Spark 性能工程的一次硬核复盘
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些观察——我觉得值得说出来的那部分。
《数据周刊》每周更新一期,挑数据行业值得看的动态,附拾穗的判断。拾穗数据|https://ss-data.cc


