
本文来源于数据从业者全栈知识库,更多体系化内容请访问知识库。
Agentic Analytics:分析师角色的终局推演
写在前面这不是一篇安慰你的文章。如果你现在的工作是”接需求、写 SQL、导出表格、发邮件”,这篇文章会让你不舒服。但不舒服,比继续睡着要好。
2026 年,Snowflake Cortex Analyst 和 Databricks AI/BI Genie 相继对外宣称 Text-to-SQL 准确率达到 90%。主流媒体的标题是:“数据分析师要失业了吗?”
这个问题问错了。
正确的问题是:哪种数据分析师要失业,哪种数据分析师会因此受益?
这两个群体,今天坐在同一间办公室,做着表面相似的工作,但三年后的命运会完全不同。
一、终局推演:同一批人的三种命运
从今天起的三年,当前这批数据分析师会分化成四个方向。分化不是因为智商差异,而是因为选择做出的时间节点不同。
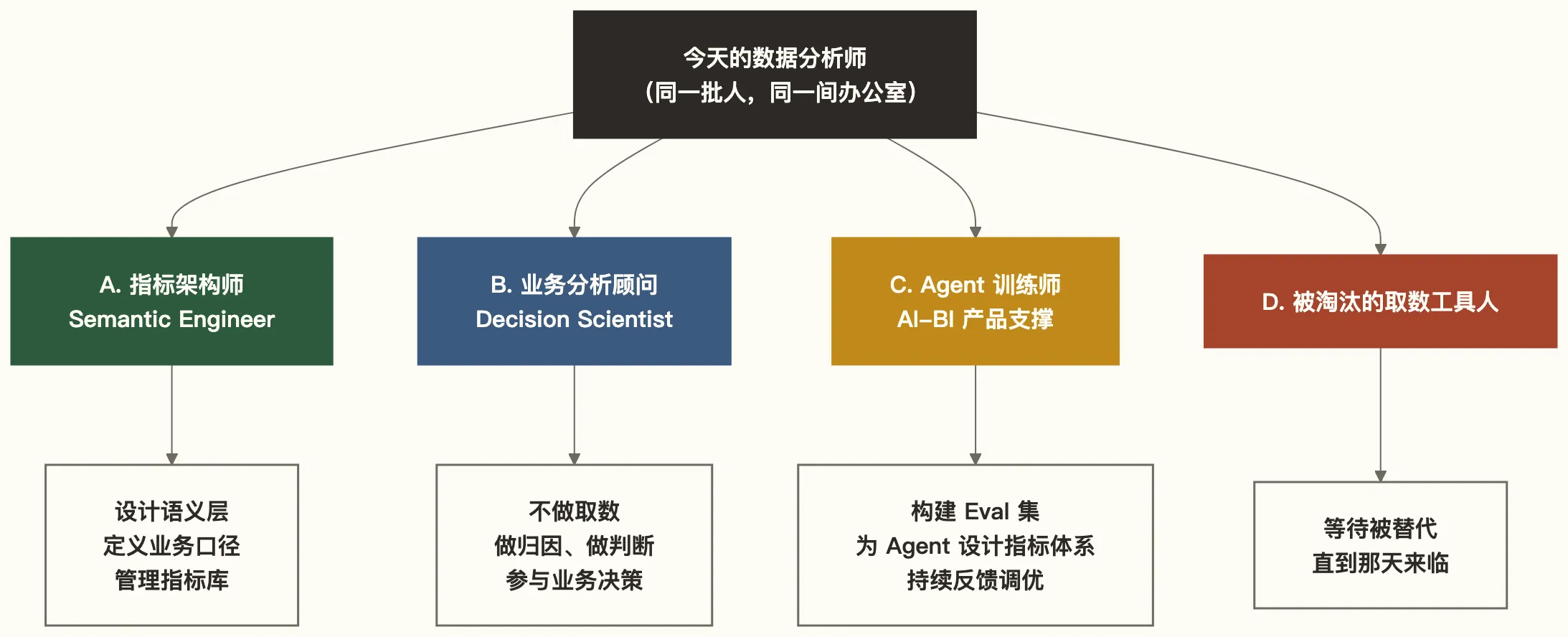
方向 A:指标架构师 / Semantic Engineer
这条路向上走。核心工作是设计语义层——把业务概念翻译成机器可理解的结构。当 AI Agent 在回答”上周的 GMV 为什么下降了”之前,它需要知道:GMV 怎么算?退款算不算?哪个口径的 GMV?这些定义,需要人来写、来维护、来治理。
方向 B:业务分析顾问 / Decision Scientist
这条路向业务走。AI 能出数,但出了数之后怎么解读、怎么决策,这是人的工作。这类分析师不再花时间取数,而是花时间在会议室里讲清楚一件事:为什么用户留存率这个月掉了 3 个点,下一步我们该怎么做。
方向 C:Agent 训练师
这条路向 AI 走。为 Text-to-SQL 系统构建评估集,持续测试 Agent 的输出质量,设计指标体系让 AI 能够自主触发分析。这个角色正在从零创造,薪资溢价在 30%-50%,但进入门槛需要同时理解业务和 AI 系统。
方向 D:被淘汰的取数工具人
这是最大的群体,也是最危险的位置。不是能力差,而是没有意识到自己在做的事已经可以被 AI 批量替代。等到公司开始裁员,才发现自己没有足够的筹码谈判。
如果你现在就在 D 的位置,这不是坏消息说”最大的群体是被淘汰的那部分”不是要吓唬谁。事实是:D 类现在的存量,大部分人三年前选这条路的时候并不知道它会变。行业变了,不是你选错了。
给现在还在 D 位置的分析师三条过渡建议:
- 先别慌,别急着离职转型。你手上做的”取数工作”短期内还在,但价值曲线在下行。用这段缓冲期——大概 12-24 个月——主动靠近 A、B、C 三个方向中的一个。
- 挑离你业务最近的那个方向。做电商/增长的分析师向 B(Decision Scientist)迁移最快;做 BI 看板的向 A(指标架构师)最自然;对 AI 有兴趣又懂一点工程的可以试 C。
- 每周抠出 5 小时做”新能力”的积累——搭一个最小 Text-to-SQL、写一次指标定义文档、给一个 Agent 建 Eval 集。不用多,坚持做,6 个月后你的简历就不一样了。
这个时代淘汰的是工种,不是人。工种可以换,人不用放弃自己。
二、90% 准确率为什么还不够
Text-to-SQL 工具的准确率数字,在实验室里看起来很吓人。但那剩下的 10%,是整个分析工作的核心价值所在。
案例一:指标歧义陷阱
某电商公司的 AI 分析工具被问到:“最近 30 天的活跃用户数是多少?”
AI 给了一个数。业务负责人把这个数拿去汇报了。
问题在于,这家公司有三个”活跃用户”定义:运营口径(7 天有登录)、产品口径(30 天有下单)、财务口径(当期有付款)。AI 用了数据库里最近一次被查询的口径,没有任何预警。
这个错误,有经验的分析师不会犯,因为他知道在哪个场合该用哪个数。
案例二:数据陷阱
另一家公司的分析 Agent 被问:“哪些城市的用户 LTV 最高?”
AI 返回了正确的 SQL,查询结果也准确无误。但结果显示,某四线城市 LTV 排名第三。
实际情况是,那个城市有一批企业账户,订单金额极高,严重拉高了均值。AI 不知道这件事,因为这个背景信息从来没有被录入任何系统。
有经验的分析师会在看到这个数字的第一秒钟说”这不对,让我看一下分布”。这种本能,来自对业务的长期浸泡,不是 SQL 能解决的。
案例三:时间序列中的假相关
某平台分析师让 AI 分析”广告投放和次日留存的相关性”,AI 给出了一个正相关系数 0.73,结论是”增加广告投放可以提升留存”。
实际上,那段时间恰好同时发生了产品改版。广告投放和产品改版都在同步上升,留存提升来自产品,跟广告的相关性是虚假的。
AI 没有办法知道在这段时间里还发生了什么。它只能看到数字之间的关系,看不见数字背后的故事。
10% 的价值这 10% 的误差,发生在歧义判断、业务背景、因果推断这三个领域。它们恰好是分析工作中最高价值的部分。AI 不是在跟分析师竞争,它是在把低价值的部分清场,把高价值的部分留给真正能处理的人。
三、分析师”不可被 Agent 替代”的五项能力
1. 业务语境理解
知道一个指标的 SQL 怎么写,和知道这个指标在特定业务场景下意味着什么,是两种完全不同的能力。前者 AI 已经超过大多数人,后者需要花时间在真实业务里打滚。
用户留存率从 40% 掉到 37%,这三个点背后是什么?是新用户质量变差,是产品某个功能崩了,还是竞品做了大促?这个判断,需要的不是 SQL,而是对这门生意的理解。
2. 异常归因
AI 能发现异常——“这周的数字比上周低了 12%“。但它不能解释为什么。
归因需要的是组织知识:上周有没有搞活动?这个功能最近是不是改版了?运营团队上周把资源投在哪里?这些信息分散在会议记录、钉钉消息、老员工的记忆里,不在数据库里。
会归因的分析师,是把数字和组织现实连接在一起的节点。这个节点,AI 无法替代。
3. 指标设计与口径治理
语义层的供应者,是分析师转型最重要的方向之一。
指标不是自然存在的,它是被定义出来的。“用户活跃”的定义,会影响整个公司的运营策略。谁来定这个定义?谁来在不同部门争论这个定义时主持公道?谁来管理这个定义随时间的演变?
这是分析师的工作,不是 AI 的工作。
参考:语义层工程实践 详细介绍了语义层的技术实现,分析师需要能够参与这个设计过程,而不仅仅是使用它。
4. Eval 与反馈闭环
Text-to-SQL 系统给出了一个答案,这个答案对不对?
90% 的准确率意味着 10% 是错的。在生产环境中,需要有人持续检查 AI 的输出,建立评估集,设计测试用例,当 AI 出错时能够识别并纠正。
这个角色,需要懂业务才能判断”这个 SQL 结果是不是合理的”。它天然是分析师的工作。
5. 跨部门沟通与商业判断
数据最终是为决策服务的。把一份分析结果变成一个被接受、被执行的决策,需要的是沟通、说服、政治智慧,和对商业逻辑的判断。
讽刺的是,这些”软技能”在 AI 时代变得更值钱,因为 AI 无法做这些事,而这些事变得更加必要——当取数被 AI 承包后,分析师能贡献的价值就集中在这里。
四、“被替代”的五类工作(直白说)
不要绕弯子。下面这些工作,在三年内会大规模被 AI 承包:
-
日常提数 — “帮我拉一下上周各渠道的新增用户数”,AI 比人快,比人便宜,比人少犯拼写错误。
-
简单的看板维护 — 每天跑一遍固定指标,更新数字,发邮件。这是典型的重复劳动,自动化程度极高。
-
基础的同比环比分析 — “本月 GMV 同比上月增长了多少”,这类问题 AI 可以直接回答,不需要人在中间。
-
标准化的 SQL 查询 — 如果一个查询需求可以用自然语言描述清楚,Text-to-SQL 就能处理。能描述清楚的,通常都是规范化需求。
-
描述性统计报表 — 每月的运营月报、数据汇总表、各维度拆解,AI 生成的质量正在逼近人工。
不是吓你如果你现在 80% 的工作时间花在上面五类事情上,你需要非常认真地思考接下来的十二个月怎么过。这不是未来的问题,这是当下的问题。
五、三种角色的详细画像
A. 指标架构师 / Semantic Engineer
一天的工作是什么样的
早上开一个与产品经理和财务的三方会议,讨论”复购率”的定义要不要把同一天的两次购买算成复购。下午用 dbt 更新语义层的 Metric 定义,写文档解释这个口径变更的业务背景。傍晚 review 其他分析师提交的指标变更 PR,打回了两个定义不清晰的。
核心技能
- 精通 dbt、Looker Semantic Layer 或 Cube.dev 等语义层工具
- 能够主导多部门的指标治理讨论,有足够的业务深度参与争论
- 理解 LLM 如何解析用户意图,知道如何写好 Metric 描述让 AI 更准确
薪资参考
国内大厂对标高级分析师到数据产品经理段位,30-50K/月,部分公司在创建此类岗位时会有额外溢价。
B. 业务分析顾问 / Decision Scientist
和传统分析师的核心差异
传统数据分析师:业务方提需求 → 我写 SQL → 我出图 → 我发报告。
Decision Scientist:AI 出数 → 我判断这个数说明了什么 → 我给出建议 → 我参与决策落地 → 我跟踪效果。
核心差异在于离决策的距离。传统分析师在决策上游,Decision Scientist 在决策现场。
不适合这条路的人
不喜欢开会,不擅长在不确定信息下做判断,习惯用数字说话而不习惯在模糊中讲故事,就不适合走这条路。
C. Agent 训练师 / Prompt 工程师
怎么入行
目前没有成熟的招聘渠道,多数是从内部转岗。最常见的路径是:在公司引入 AI-BI 工具时,主动承担”负责人”角色,积累 Eval 设计和系统调优的经验,再对外包装成这个方向的能力。
需要什么背景
比其他两条路更需要技术基础。要能写 Python,要理解 Embedding 和 RAG 的基本原理,要能设计测试集和评估指标。但不需要成为 AI 工程师,理解原理、能够沟通、能够判断输出质量,比会自己训练模型更重要。
参考路径:Agentic Data Engineering 方法论 是理解这个方向技术背景的必读文档。
六、12 个月转型路线图
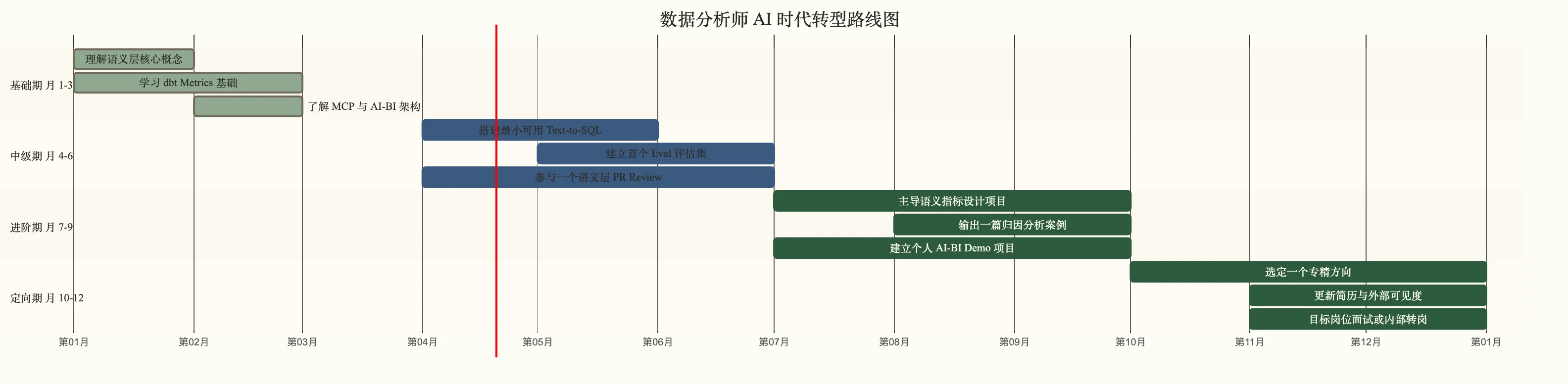
月 1-3:建立认知基础
重点是建立对新技术栈的认知,不是精通。读懂 语义层工程实践 和 Text-to-SQL 实战 这两份文档,理解技术架构,而不是学会编程实现。同时,开始有意识地在日常工作中记录 AI 的输出质量问题。
具体行动:
- 在公司找一个 AI-BI 工具试用,记录五个出错案例
- 阅读 dbt Semantic Layer 文档,理解 Metric 定义语法
- 参加一次公司内部的数据治理讨论,观察指标口径如何被争论
月 4-6:动手搭第一个原型
用开源工具搭一个最小可用的 Text-to-SQL 系统(推荐从 Vanna.ai 或 SQLChat 开始,门槛低),然后为它建立一个 Eval 集:设计 30-50 个标准问题,记录 AI 的回答和正确答案,计算准确率。
这个过程会让你真正理解 90% 准确率是怎么来的,以及为什么剩下的 10% 那么难。
- 本地部署一个 Text-to-SQL 工具,接入公司的测试数据
- 建立包含 50 个测试用例的 Eval 集
- 完成一篇关于”AI 在哪些场景失败了”的内部分析报告
月 7-9:参与一个真实项目
主动争取参与公司的 AI-BI 产品设计,或者找一个开源项目贡献 Semantic 设计。重点是让外部可见——在 GitHub 有记录,在内部有 credit,在简历上有案例。
同时,做一个完整的业务归因分析案例,文档化从发现异常到提出建议的全过程。这是 Decision Scientist 方向的核心能力展示。
月 10-12:选定方向,对外包装
三个方向里选一个,集中精力完善这个方向的技能,更新简历,增加外部可见度(掘金、知乎、公众号写一篇技术复盘)。
参考 2026 数据人必学 TOP10 校准技能选择,确保学的东西在市场上有需求。
七、给三类分析师的具体建议
大厂数据分析师(资源多、工具新)
你的优势是能第一时间接触到新工具,公司可能已经在内测 AI-BI 产品。
策略:主动争取 AI 项目的负责人角色。
不要等公司安排培训。当团队开始讨论”要不要引入 AI-BI 工具”的时候,举手说”我来负责”。这个角色一开始可能是打杂的(写测试用例、整理文档),但它会给你积累真实的转型经验,而不是只在旁边看。
大厂有一个特有的风险:资源太多导致不着急。身边的人都还在用传统方式,看起来一切正常。这种环境会让你失去转型的紧迫感。主动找有危机意识的人组成小团队,互相推动。
中小公司分析师(资源少、要自己搞)
你的资源没有大厂多,但你有一个优势:更容易接触到真实的业务决策。
策略:用开源方案积累,把局限变成案例。
开源社区里有足够多的 Text-to-SQL 工具可以试用,不需要公司采购。用下班时间搭一个 Demo,接上公司的脱敏数据,做出来之后在公司内部展示。这个 Demo 本身的价值不大,但它能给你带来内部可见度和转岗谈判筹码。
中小公司的风险是另一个方向:一个人做所有事,没有时间投入转型。如果现在的工作强度让你没有任何余力,这本身就是一个需要解决的问题。
业务方向分析师(不写很多 SQL 的)
这类分析师在用户研究、增长分析、市场分析方向,日常工作里 SQL 本来就不多,更多是理解数据、解读结论、给出建议。
你可能是这三类人里最不危险的。
因为你的核心工作——跟业务对话、解读数字、参与决策——恰好是 AI 最难替代的部分。你需要做的是主动补上技术认知(理解 AI 的能力边界在哪里),而不是技术能力本身。
参考 数据分析与数据运营导览 梳理一下自己的能力版图,确认哪些地方需要更新。
八、反模式:转型中的五个陷阱
陷阱 1:以为”学个 Prompt Engineering”就够了
Prompt Engineering 是入门,不是护城河。会写 Prompt 的人,在六个月内会从稀缺变成普通。
真正的壁垒在于:能够用 Prompt 的能力解决特定业务问题,并且能够建立评估和迭代的机制。光会写 Prompt 的人,和会使用计算器的人一样,没有专业优势。
陷阱 2:逃到技术深水区
看到 AI 威胁,去学机器学习,以为往”更技术”的方向逃就安全了。
这是一个误判。数据分析师学机器学习,往往是在和专业的算法工程师竞争,而你的优势(业务理解、沟通、判断)在这个方向没有用武之地。
你的业务知识是真正的壁垒,跑掉等于放弃了最大的优势。
陷阱 3:否认 AI 威胁,假装一切如常
“我们公司的数据很乱,AI 根本用不起来。”
“Text-to-SQL 看起来准确率高,但实际上错误太多,没法用。”
这些判断在今天可能是对的。问题是,一年后还是对的吗?两年后呢?等到 AI 工具真的可以用了,你的准备时间已经归零。
陷阱 4:完全依赖公司培训,不主动搭私域项目
公司的培训是给公司设计的,不是给你设计的。它会教你用公司选定的工具,完成公司需要的任务。
真正让你在市场上有竞争力的,是你自己主动搭的那个 Demo,写的那篇技术文章,在 GitHub 上的那个项目。这些东西,属于你,不属于公司。
陷阱 5:忽视”软技能”在 AI 时代的价值
很多分析师在 AI 浪潮里的本能反应是学更多技术。
但现实是:当 AI 把取数、出报告的成本降到接近零,人的时间会更集中在决策和沟通上。能够把分析结论讲清楚、能够在会议室里说服一个怀疑你数据的业务 VP,这些能力的价值在上升,不在下降。
参考 数据分析师求职导览 评估自己的完整能力图谱,不要只看技术维度。
九、结尾
分析师这个岗位不会消失。
但”取数工具人”这个职能会消失,和历史上许多被技术替代的职能一样,不是突然消失,而是慢慢找不到买家。
这一轮洗牌有一个不那么显而易见的好消息:当 AI 把低价值的工作承包出去,高价值工作的单价会上升。公司愿意为一个真正能够判断”这个数字背后发生了什么”的分析师付更多钱,因为这样的分析师变得稀缺了。
稀缺的原因不是因为这种能力难以习得,而是因为大多数人正在做的是等待,而不是转型。
引用“危机这个词,在中文里拆开来是危险和机会。这不是鸡汤,这是描述。同一件事,对不同准备程度的人,意味着完全不同的结局。”
接下来该做什么,你心里有数。
延伸阅读
- 数据分析与数据运营导览
- Text-to-SQL 自然语言查询实战
- 语义层工程实践
- Agentic Data Engineering 方法论
- 2026 数据人必学 TOP10
- 数据分析师求职全攻略导览


