本文来源于数据从业者全栈知识库,更多体系化内容请访问知识库。
2026 数据人必学 TOP 10
引用过去十年,数据行业赚的是”把数据变好”的钱。接下来十年,赚的是”把数据变成 Agent 能用的原料”的钱。中间隔着一整套新的基础设施、新的契约、以及一个新的工程师角色。
这份清单不是”赶时髦的十个热门词”。是我在看完 2025 年底到 2026 年 4 月这段时间 Databricks、Snowflake、Qlik、Cloudera、Atlan 一系列动作之后,筛掉了至少一倍的候选项,留下的最硬的十个。每一项后面都附了它的”为什么要学”和”通往知识库的入口”。
0. 先把心态调对:你不是在学十项新技能,你是在换一个职业定位
2026 年数据人最危险的状态,不是”不会 AI”,而是把 AI 当成一个插件——“我本来在写管道,现在加一个 LLM 调用就好了”。
不是的。真正在发生的事情是:
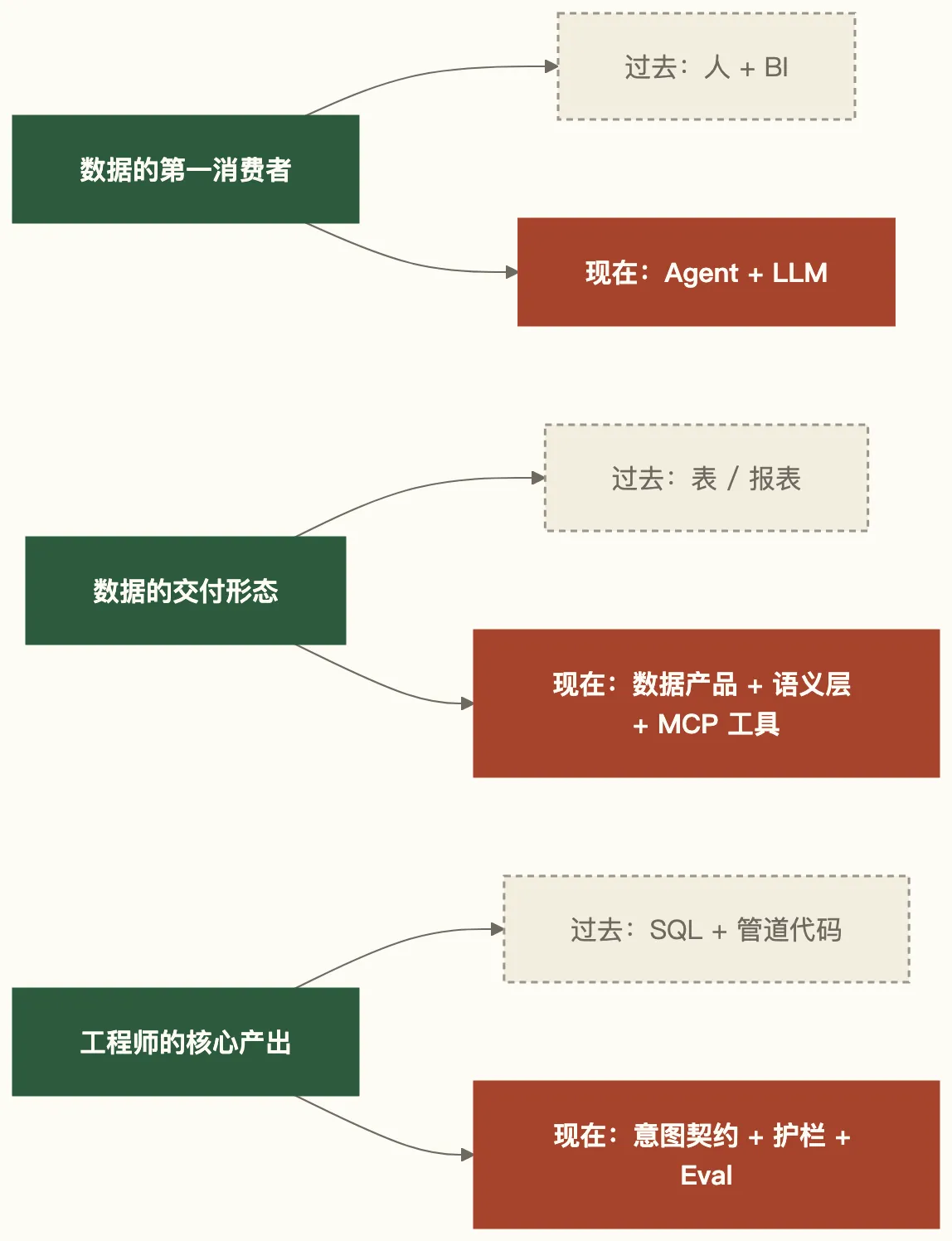
整条价值链在重构。下面这十项,就是这条新价值链上你迟早要掌握的基本功。
相关阅读:2026春季扩充路线图
1. MCP 协议:新时代的 REST
为什么排第一2015 年前后,一个不会 REST API 的后端工程师会被淘汰。2026 年,MCP 就是数据 + AI 世界的 REST。OpenAI、Google DeepMind、Microsoft 已经在十二个月内把它共同认定为事实标准。
MCP(Model Context Protocol)干的事情很直白:让 Agent 用统一的方式访问工具和数据。它替代了”给每个 LLM 重写一套 function call”的野蛮时代。
作为数据人,你要搞懂的是:
- 协议本身(Resource / Tool / Prompt 三件套)
- Server 怎么写(把你们公司的数据能力暴露给 Agent)
- Gateway 怎么部(企业级鉴权、审计、限流)
别停在”装个 MCP client 用用”这一层。你要能设计 MCP Server 的 schema,这是新的”API 设计”。
知识库入口:MCP 学习路线图、MCP 协议核心概念、MCP Gateway 与生产部署
2. Agent 编排框架:至少精通一个
LangChain 过时了吗?没有。但你如果只会 LangChain,2026 年你已经落后了。
新的现实是:场景决定框架。
| 场景 | 推荐框架 | 原因 |
|---|---|---|
| 企业级多 Agent 协作 | LangGraph | 状态机清晰、可观测性好 |
| 事件驱动的实时 Agent | Flink Agents(FLIP-531) | 用 Flink 的 checkpoint 保证 exactly-once |
| 快速搭产品原型 | Dify / Coze | 可视化、上线快 |
| 数据分析 Agent | Databricks Agent Bricks / Snowflake Cortex | 贴着数据平台走 |
不要贪多。挑一个你业务匹配度最高的,跑一个端到端项目,比你读十篇框架对比文都值。
知识库入口:AI Agent 智能体概述、AI Agent 开发框架实战、AI 多 Agent 协作系统
3. 语义层(Semantic Layer):Agent 时代的”度量衡”
这一项被严重低估。
你以为 Text-to-SQL 准确率上不去是 LLM 不够聪明?错了。是你们公司没有语义层。
Snowflake Cortex Analyst 敢对外宣称 90% 准确率,不是因为它 LLM 牛,是因为它强制用户建 Semantic View。Databricks AI/BI Genie 也一样。
语义层的本质是:把”业务术语 → 表字段”的映射一次定义、处处复用。“复购率”、“活跃用户”、“华北区”这些概念,必须有唯一的、被治理的定义。没有这一层,Agent 不会算错,是你根本不知道它算的是哪个”复购率”。
该学的工具至少挑一个:dbt Semantic Layer、Cube、LookML。底层逻辑都是一样的。
知识库入口:语义层工程实践、Text-to-SQL 自然语言查询实战
4. Iceberg V3 与开放表格式:存储层的第二次革命
2026 年 4 月 Dremio 官宣 Iceberg V3 云上可用,这个信号被很多人低估了。
V3 不只是版本号 +1。它是为 AI workload 重新设计的表格式:
- 更丰富的数据类型(为多模态准备)
- 更细粒度的 schema evolution(Agent 频繁改动 schema 是常态)
- 高并发低延迟优化(AI 查询不可预测)
这件事的战略含义是:数据湖仓从”给 BI 服务”正式过渡到”给 Agent 服务”。Delta、Paimon 也在跟进,但 Iceberg 生态目前最活跃,三大云厂商都在押注。
知识库入口:Iceberg V3 深度解析、数据存储架构
5. Embedding 管道:新时代的 ETL
心智模型转换过去 ETL 的终态是”表”。现在多了一个终态:向量。
Embedding 管道不是”调一下 OpenAI API”那么简单。生产环境要解决的问题包括:
- 分块策略(固定长度?语义分块?层级分块?)
- Embedding 模型选型与版本管理(换模型就要全量重算)
- 增量更新(源文档变了,哪些向量要重建)
- 多模态(图、音、视频的 embedding 怎么和文本对齐)
- 成本(每天跑多少 token 是一笔账)
这是数据工程师接下来最稳的增量工作之一——因为 RAG 不会消失,只会扩散。
知识库入口:RAG 检索增强生成实战、向量数据库与语义搜索、Embedding 工程
6. Agent Observability:可观测性的新战场
传统 APM(Datadog、New Relic)不够用了。Agent 的可观测性有三个新维度:
- Trace:一次 Agent 执行经过了哪些工具调用、哪些 LLM 调用、哪些数据查询,每一步的输入输出是什么
- Eval:每一步的输出是否符合预期(这是一套要自己建的评估集)
- Guardrail:护栏触发情况(PII 泄露、Prompt 注入、越权访问)
Atlan 在 2026 年初把”Agent Observability”列为和 DataOps 同级的新品类,不是营销,是事实。
这项技能对数据人的价值:你已经很熟悉数据血缘、数据质量、DataOps 这套东西了。Agent Observability 就是这套能力在 Agent 域的延伸。你是最适合切这块蛋糕的人。
知识库入口:Agent Observability 三件套、LLM 可观测性与监控
7. Context Engineering:Prompt Engineering 的继承者
Prompt Engineering 这个词正在贬值。不是因为它不重要,是因为它太窄了。
2026 年的共识词是 Context Engineering——你要设计的不是一句 Prompt,是整个上下文窗口:
- 系统 Prompt 是什么
- 从哪些知识源检索上下文(RAG)
- 历史对话怎么压缩、怎么摘要
- 工具定义怎么写(Tool Description 也是上下文)
- 例子怎么选(Few-shot 也是上下文)
- 什么时候清空、什么时候保留(Memory 管理)
把这当成一个系统工程问题,而不是”写句俏皮话”的艺术。
知识库入口:Prompt Engineering 提示工程
8. 非结构化数据处理:从 PDF 到结构化
2026 年 Databricks 和 Snowflake 前后脚推出 SQL 里直接解析 PDF 的能力。这不是奇技淫巧,是行业共识转向的标志:
企业里 80% 的数据是非结构化的,但过去我们只处理了那 20%。现在 AI 让前 80% 也能被处理了。
数据工程师的工作版图因此扩了一倍。你要学的东西包括:
- 文档解析(PDF、PPT、扫描件):Unstructured.io、LlamaParse、各种 OCR
- 多模态抽取(表格、图表、图像)
- 非结构化数据的元数据管理(这块以前几乎是空白)
- 非结构化数据的质量评估(字段完整率那一套不适用了)
知识库入口:非结构化数据管道
9. AI Lineage:血缘的第二次升级
数据血缘(Data Lineage)大家都知道。
AI Lineage 是它的 2.0:追踪一个 Agent 的输出,往回能追到哪个 Prompt 版本、哪个模型、哪段训练数据、哪张底层表、哪次 Embedding 重算。
这件事的驱动力有两个:
- 合规:欧盟 AI Act 全面生效后,谁也不敢让 Agent 在业务里跑没血缘的链路
- 调试:Agent 出错了,你要能 10 分钟内定位是 Prompt 的问题、模型的问题、还是数据的问题
Unity Catalog 已经在做 Model Lineage 和 Prompt Lineage 的融合。Open Catalog、Atlan 跟进。这是 2026-2027 年治理侧最大的机会。
知识库入口:AI Lineage、数据治理与数据管理
10. Token Economics:新的”成本意识”
一个被忽视的真相一个跑起来的 Agent 系统,成本结构和传统数据系统完全不同。Token 费用可以一夜之间翻十倍,只要换个模型或者改个 Prompt。
老的数据工程师算的是:集群多少核、存储多少 TB、query 跑多久。
新的数据工程师还要算:
- 每个 Agent 调用的平均 token 数
- 哪些步骤可以用小模型、哪些必须用大模型
- Prompt Cache 命中率
- KV Cache 能复用多少
- Batch API 能省多少钱
- Embedding 重算的触发策略
这项技能目前在市场上是稀缺的——因为懂 LLM 的不懂成本,懂成本的不懂 LLM。数据人恰好在交叉点上。
知识库入口:LLM 成本控制与优化
学习顺序建议
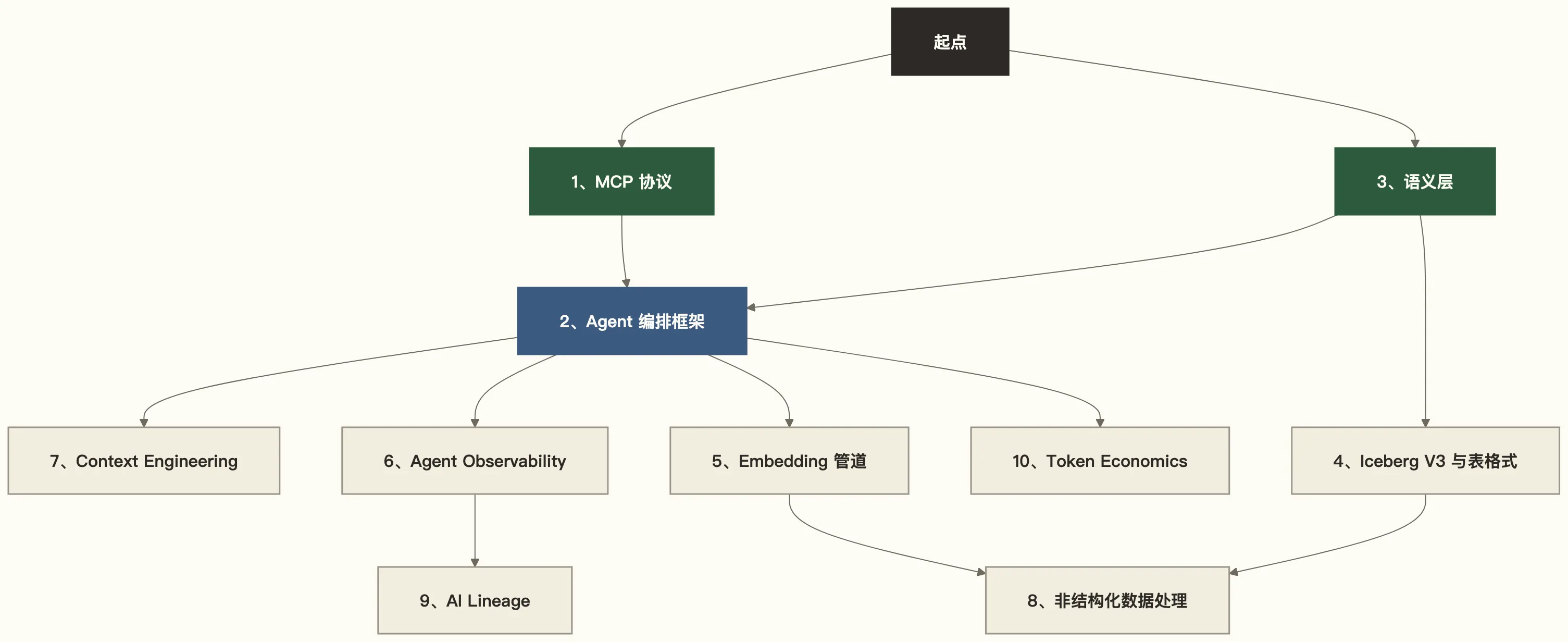
不要线性地 1 → 2 → 3 学下去。按问题驱动:
- 做 Agent 项目的:从 1、2、3 开始
- 管数据平台的:从 1、4、9 开始
- 做数据分析的:从 3、7 开始
- 搞治理合规的:从 6、9 开始
没进这份清单的东西
一些你可能以为会进来、但没进来的:
- Transformer 原理:知道就行,不用精通。2026 年调模型已经不是数据人的日常工作。
- 训练大模型:98% 的数据团队永远不会训自己的 foundation model。
- Fine-tuning:细分场景有用,但优先级低于 RAG 和 Context Engineering。详细决策框架见:什么时候才该 Fine-tune:2026 决策框架
- 向量数据库选型:工具层面,PGVector、Milvus、LanceDB 挑一个能跑就行,不值得花大量时间反复比较。
把精力留给上面那十项,它们是复利最高的。
最后一句
2026 年数据人最大的机会,是你站在数据和 AI 的交叉口。
AI 工程师懂模型不懂数据,数据工程师懂数据不懂模型,而 Agent 时代的整个价值链,恰好需要两边都懂的那个人。
这不是一个”焦虑内卷”的故事,是一个”地盘扩大”的故事。
配套资源
- 整体扩充计划:2026 春季扩充路线图
- AI 与大数据导航:AI 与大数据导航
- 技术趋势导览:技术趋势导览
- 求职就业专题:求职就业专题
写于 2026-04-19,会随行业变化更新。如果一年后回看这份清单,发现有五项以上已经过时,那说明行业在健康地前进。