
有些团队做高质量数据集,最后做成了一个共享文件夹。
里面有很多 Excel、CSV、截图、标注文件和说明文档。刚建好的时候,大家都觉得很充实。
过了两个月,问题开始出现。
文件哪个是最新版?字段为什么变了?这批样本能不能给 AI 用?谁改过标签?哪些数据有敏感信息?业务发现错误以后要反馈给谁?算法团队能不能直接拿去训练?数据团队要不要为结果负责?
如果这些问题答不上来,文件再多也不叫可复用供给。
它只是一个文件夹。
高质量数据集的关键,不是“整理了一批数据”,而是“让一批数据在明确边界内被稳定、可控、可追溯地重复使用”。
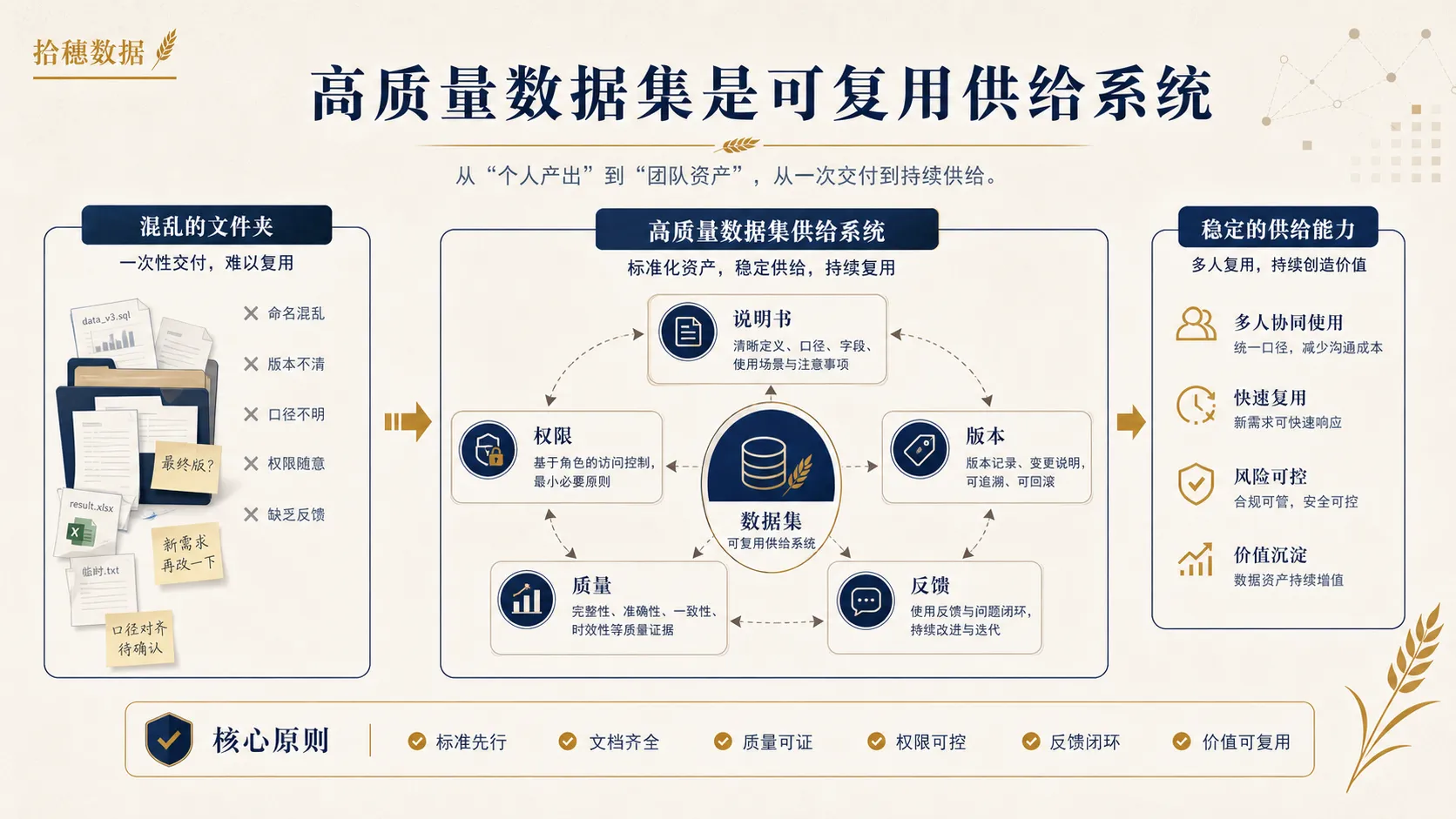
从文件夹思维到供给思维
文件夹思维关注的是“放在哪里”。
供给思维关注的是“怎么被稳定使用”。
这两个差别很大。
一个文件夹可以很快建起来。找个共享盘,按日期建目录,把样本、表格、文档放进去,再写一个 README,看起来就像有了数据集。
但供给能力要回答更多问题。
它服务哪个业务场景?谁是主要使用者?数据从哪里来?字段含义是否稳定?标签规则谁确认?版本如何演进?权限怎么控制?质量如何验收?被谁调用过?调用后发现问题怎么反馈?
只要这些问题没有机制,数据集就会很快失控。
文件还在,信任没了。
高质量数据集真正要交付的,不是一堆文件,而是一套可使用、可解释、可维护、可追责的供给关系。
先定义使用场景,而不是先收集数据
很多数据集项目失败,是因为第一步就错了。
团队一上来就开始收集数据:把历史工单导出来,把客服对话导出来,把产品日志导出来,把业务文档导出来,把行业资料抓下来。
看起来很勤奋,但如果没有使用场景,很快会变成垃圾堆。
高质量数据集要先回答:它到底服务什么场景。
是给 AI 客服做知识问答?给风控模型做样本训练?给经营分析做标准指标集?给销售助手做客户画像?给数据资产入表做资源证明?不同场景对数据集的要求完全不同。
AI 客服更关注知识准确性、更新频率、敏感信息过滤和答案可追溯。
模型训练更关注样本代表性、标签一致性、训练/验证划分和偏差控制。
经营分析更关注指标口径、时间范围、维度层级和数据刷新稳定性。
数据资产管理更关注来源权属、质量证据、使用记录和成本归集。
所以,数据集说明书第一行不应该写“文件路径”。
应该写“这个数据集服务什么决策或应用”。
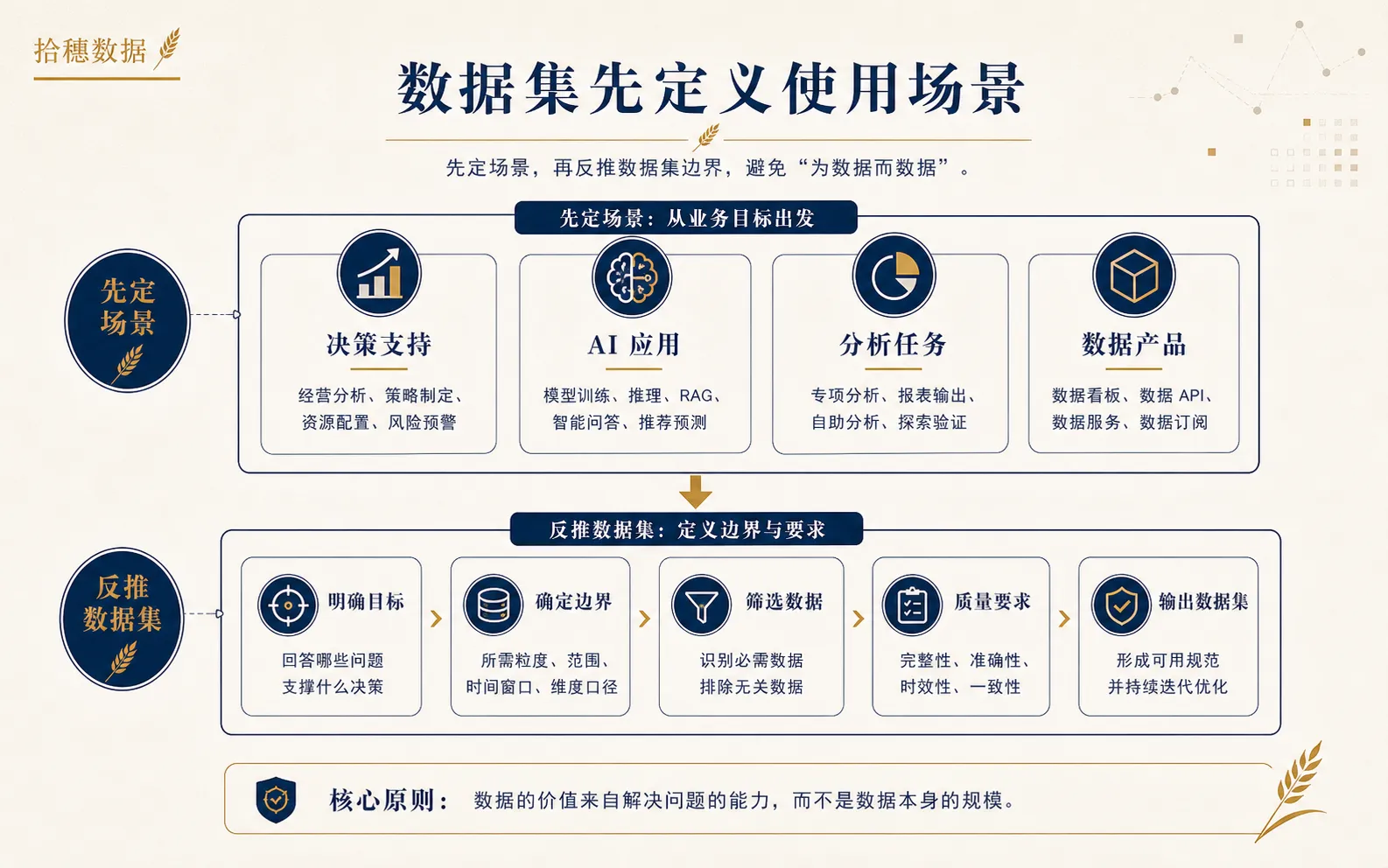
一份数据集说明书应该写什么
可复用的数据集,必须有说明书。
说明书不是形式主义。
它是让后续使用者知道“这批数据能怎么用、不能怎么用、出了问题找谁”的入口。
一份够用的数据集说明书,建议至少包含这些内容。


