
领导突然说要做高质量数据集时,会议室里通常会出现一种很熟悉的沉默。
业务同学先看产品,产品看算法,算法看数据,最后大家一起看向数据团队。
“我们是不是先整理一批样本?”
“要不要找人标注?”
“有没有现成的数据可以直接拿来训练?”
这些问题都没错。但如果第一步就从“找样本、做标注、建文件夹”开始,这个项目大概率会在后面反复返工。
因为高质量数据集的难点,往往不在标注那一刻,而在标注之前。
它到底服务什么业务场景?样本边界怎么定?字段口径谁说了算?质量好坏怎么验收?版本变化谁记录?哪些数据可以给 AI 用,哪些不能?上线以后错了谁响应?
这些问题不说清楚,数据集看起来会越来越厚,但真正接到业务和 AI 应用里时,大家还是不敢用。
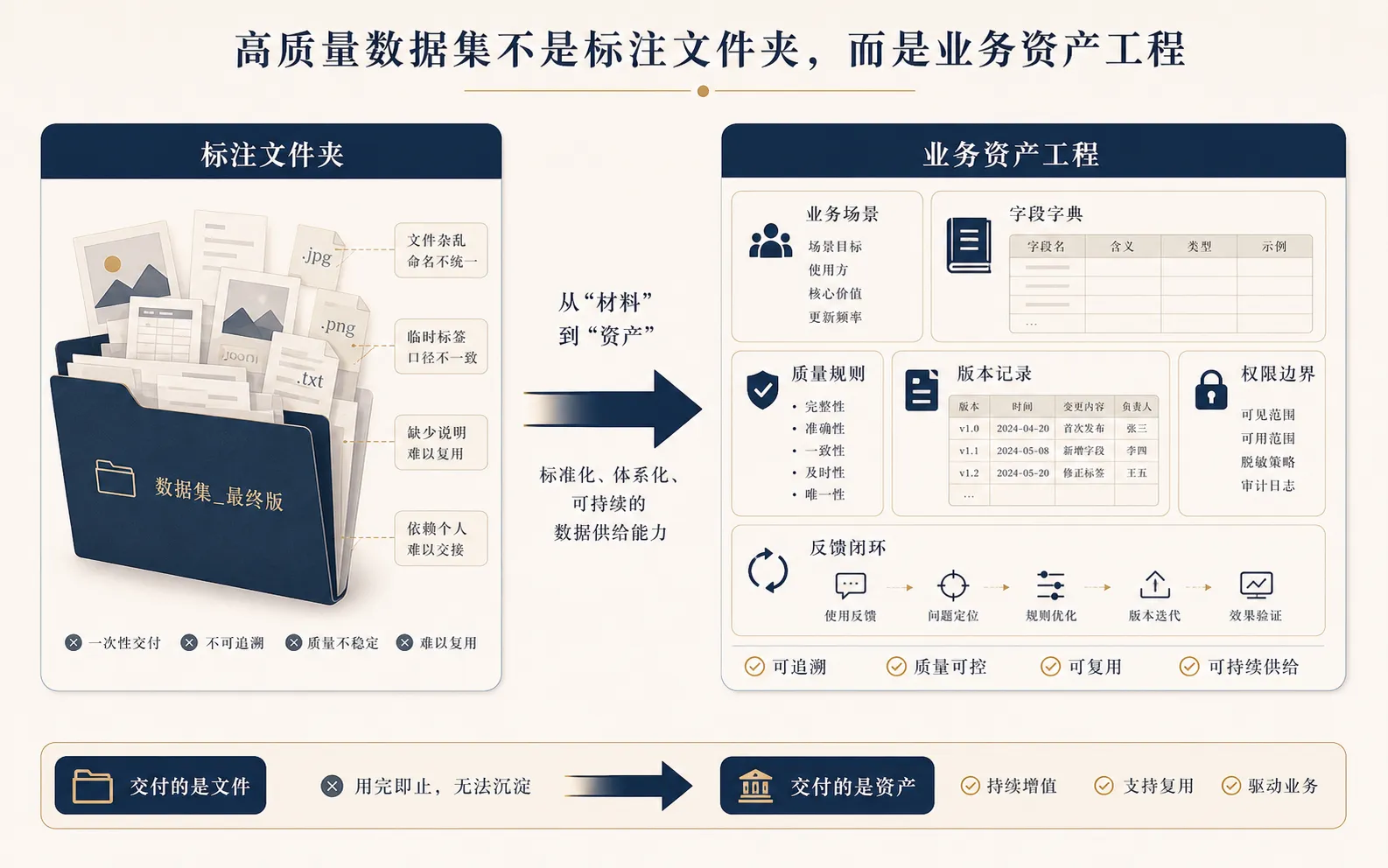
高质量数据集不是标注任务,而是把一个业务问题沉淀成可持续供给的数据资产工程。
先确认业务场景
“高质量”不是一个孤立指标。
没有场景,就没有质量。
同一批订单数据,如果用来做经营日报,最重要的是口径一致、更新及时、历史可比。如果用来训练异常检测模型,最重要的是异常样本是否足够、标签是否稳定、时间窗口是否合理。如果用来给 AI 问数系统回答问题,最重要的是指标定义、权限边界和可解释性。
所以领导说“做一批高质量数据集”时,数据团队第一句话不该是“我们有哪些数据”,而应该是:
这批数据集准备服务哪个业务动作?
是给模型训练用,给 AI 问数用,给经营分析用,给客服知识库用,还是给外部项目申报用?
不同场景下,高质量的定义完全不同。
比如,一个智能客服数据集,需要关注问题表达、标准答案、知识时效、敏感信息过滤。一个销售线索评分数据集,需要关注客户阶段、转化结果、时间窗口、渠道来源。一个设备故障预测数据集,需要关注采样频率、故障标签、维修记录和传感器缺失。
如果场景没有被写下来,后面所有工作都会变成猜。
数据团队猜业务想要什么,算法同学猜标签代表什么,产品经理猜上线后谁会用,领导最后猜这个项目有没有价值。
高质量数据集的第一份交付物,不是文件夹,而是一页场景说明。
这页说明至少回答四个问题:
第一,它服务哪个业务动作?
第二,谁会反复使用它?
第三,使用它之后希望改变什么结果?
第四,如果数据错了、旧了、漏了,会影响谁?
这四个问题写清楚,高质量才有落点。
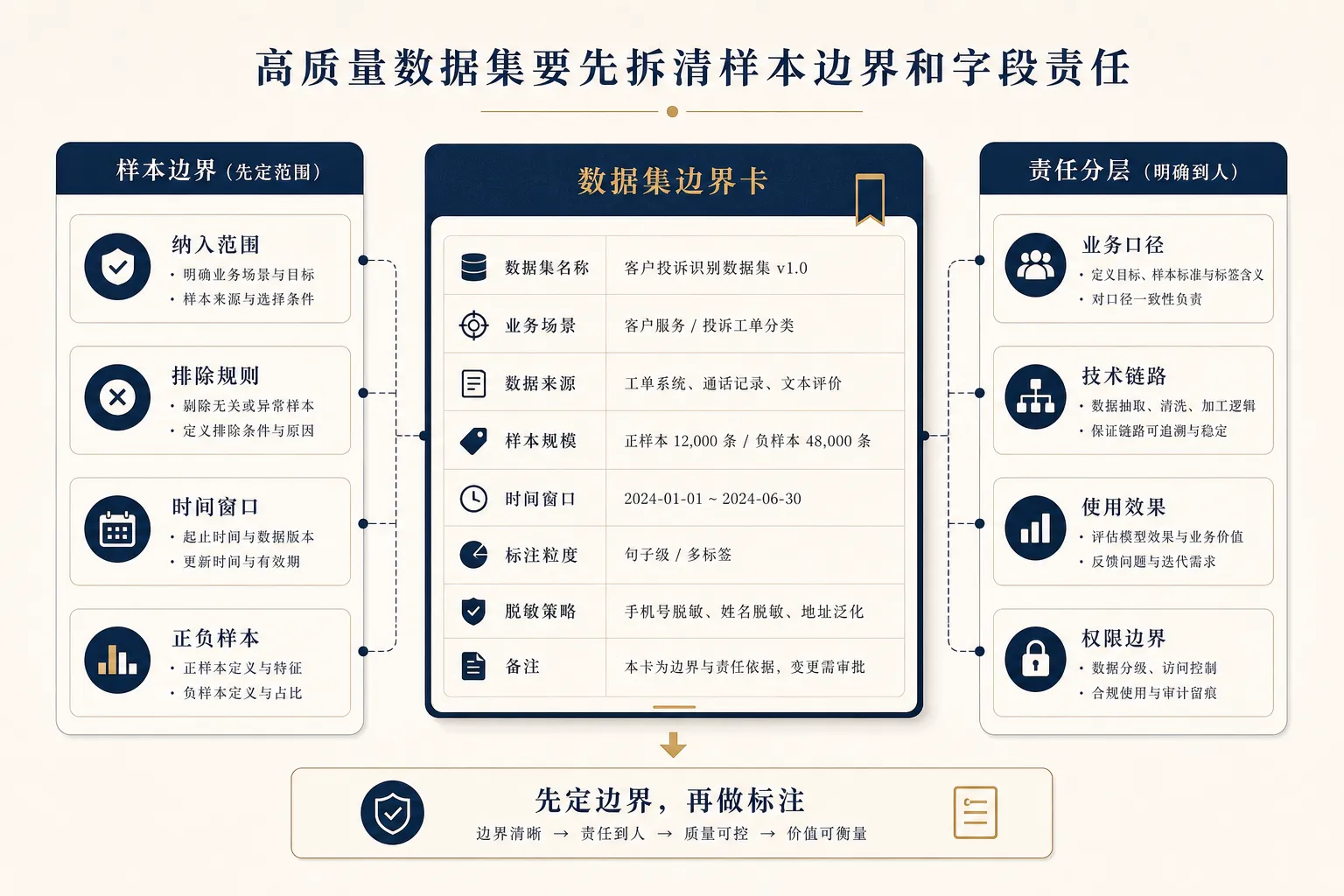
定义样本边界和字段责任
很多数据集项目会在样本边界上出问题。
看起来只是“多拿一点数据”,实际上会影响整个项目的判断。
比如做客户流失预测,到底哪些客户算流失?连续 30 天未登录算不算?没有续费但还在试用期算不算?主动取消和被动欠费要不要混在一起?大客户和小客户是否放在同一个样本里?
比如做工单分类,历史工单里的分类标签是不是人工随手选的?同一个问题在不同客服手里会不会被分到不同类别?“其他问题”占比太高时,要不要先重做分类体系?
比如做经营指标问答,成交金额、支付金额、确认收入、含税金额、退款后金额,是不是被混着用?
这些问题不是算法问题,也不是标注员能单独解决的问题。
它们是业务定义问题。
所以样本边界要在标注前确认,字段责任也要在标注前拆开。
一份可用的数据集,至少要有三层责任:
第一,业务口径责任。由业务或产品确认:这个样本代表什么业务含义,正负样本怎么区分,哪些情况要排除。
第二,技术链路责任。由数据开发确认:数据来自哪些系统,经过哪些加工,字段是否稳定,调度是否可追溯。
第三,使用效果责任。由模型、产品或业务负责人确认:数据集用来优化什么指标,效果如何验收,出现错误时怎么反馈。
如果所有责任都写成“数据团队负责”,项目后面一定会变形。
数据团队可以承担组织和交付,但不能替所有人定义业务含义,也不能替所有使用者背结果。
验收标准要早于标注
很多团队会把验收放到最后。
数据收集完了,标注做完了,文件夹整理好了,才开始问:这算不算高质量?


