
周五下午,会议室的投影还亮着。
一个业务负责人把 AI 问数 Demo 演示完,屏幕上跳出一段挺像样的分析:最近三个月 GMV 下滑,原因可能来自新客减少、渠道转化下降、老客复购不足。旁边还配了一张折线图,看上去比很多人工周报都整齐。
屋子里安静了几秒。
然后老板问了一句:“那以后还需要数据团队吗?”
这句话不一定带恶意。很多时候,老板只是看见了一个会说话、会画图、会写 SQL 的新工具,顺手问出了一个管理者都会问的问题:既然一部分动作能自动完成,原来做这些动作的人还要站在哪里?
我理解这种问题为什么刺耳。
过去很多数据岗位的安全感,来自熟练动作:取数快、报表稳、SQL 写得漂亮、分析报告交得及时。现在 AI 把这些动作的一部分搬到了按钮后面。按钮一多,人就容易怀疑自己是不是也变成了按钮的一部分。
但我不太认同“数据岗位会被 AI 整体替代”这个说法。
更准确的说法是:AI 不会先替代一个岗位,它会先重定价岗位里的任务。低上下文、规则明确、输入输出清楚的动作会变便宜;高上下文、牵涉责任、需要组织判断的工作会变贵。
真正变化的不是岗位名字,而是岗位边界。
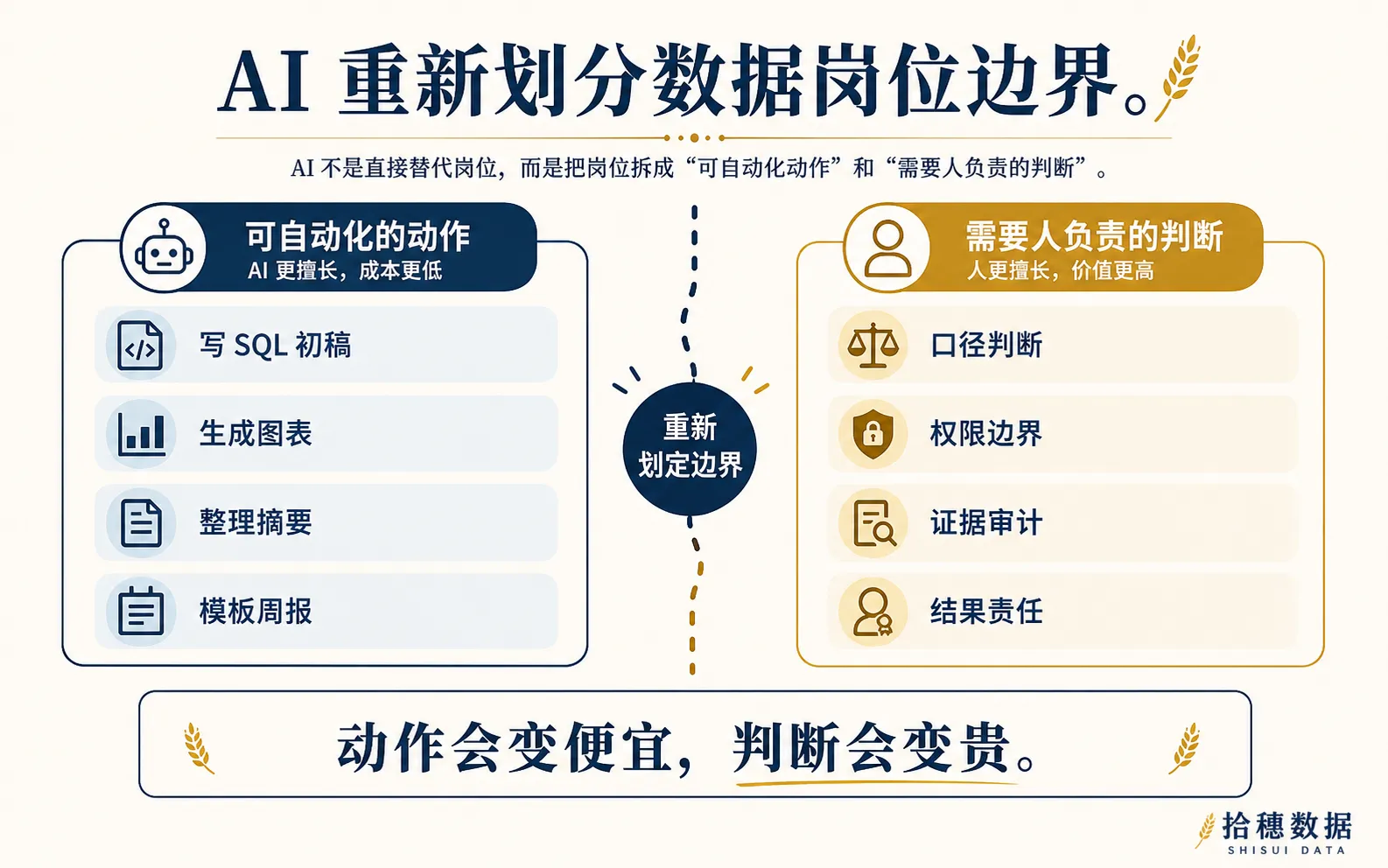
先别问岗位会不会消失,要问任务被拆到哪里
“数据分析师会不会被替代”“数据开发会不会被替代”,这类问题听起来很直接,实际有点粗。
一个岗位不是一块铁板。
一个数据分析师的一天里,可能有四类事情:帮业务取一批数,解释一个指标为什么变了,写一页经营分析,和产品一起讨论下个月应该改哪个策略。一个数据开发的一天里,也可能有四类事情:补一条调度任务,排查一张表为什么延迟,改一个数据模型,和风控团队确认一批字段能不能开放。
这些事情都叫“数据工作”,但它们的上下文完全不同。
让 AI 根据自然语言生成一段 SQL 初稿,这是一类任务。让 AI 判断“有效订单”到底该不该扣掉退款和取消单,是另一类任务。前者输入清楚、结果可以快速验证;后者牵涉业务口径、财务口径、历史口径和组织里的责任分配。
同样是“分析 GMV 下滑”,让 AI 按模板拆渠道、拆地区、拆用户分层,这是一类任务。判断这次下滑到底是投放减少、库存不足、价格策略变化,还是某个埋点升级造成的假波动,是另一类任务。
把这两类任务混在一起讨论,就会得出很吓人的结论。
可是一旦拆开看,事情就清楚多了:AI 会吃掉大量“可描述、可重复、可验证”的动作;但它越进入真实业务,越需要有人提供上下文、校准边界、留下证据、承担结果。
Anthropic 在 2025 年发布 Economic Index 时,用的也是类似思路:不是只看职业名称,而是看具体任务。它们分析了大量匿名使用数据后发现,当时 AI 使用更偏向增强人的能力,而不是完全替人做完整任务。这个比例后来会继续变化,但任务视角本身很重要。
岗位焦虑最容易把人带进死胡同。任务视角才比较诚实。
会变便宜的,是低上下文动作
低上下文动作有几个特点。
第一,输入比较清楚。比如“帮我写一段 SQL,统计过去 30 天每个渠道的订单数”。
第二,输出比较标准。比如一张表、一段代码、一页摘要、一组图表。
第三,验收比较容易。SQL 能不能跑,图表有没有画出来,摘要有没有覆盖重点,稍微看一眼就能判断。
这类动作过去占了数据岗位不少时间。
很多分析师每天要做的,并不是“提出一个新的商业判断”,而是把业务发来的需求翻译成 SQL,把 SQL 跑出来,把 Excel 发出去,再把领导已经知道的事情写成一页更顺的文字。很多数据开发每天要做的,也不是重新设计系统,而是在旧链路上补字段、修任务、查日志、回工单。
这些事情并不低贱。公司离不开它们。
可是 AI 进入以后,它们的价格一定会下降。
以后业务同事会越来越习惯先让工具查一遍,产品经理会越来越习惯让 AI 生成分析初稿,数据同学自己也会越来越习惯用模型补 SQL、写文档、检查异常。原来需要半小时的动作,可能变成五分钟;原来需要一个人排队支持的需求,可能变成自助入口。
这时候,如果一个人的价值主要停在“我来帮你做动作”,他就会越来越累。
不是因为他没用。
而是因为组织会自然地追问:这类动作能不能自助化?能不能产品化?能不能让 AI 先做一版?能不能只在异常时找人?
低上下文动作不是突然消失,而是会从“人工服务”变成“系统能力”。
这件事对数据从业者有点残酷,但也是机会。因为被工具接走的那部分时间,原本就不该永远占着我们的大脑。

会变贵的,是上下文、边界和责任
如果只是写 SQL,AI 会越来越快。
但真实公司的数据问题,往往不是 SQL 问题。
它们更像一张旧桌子底下缠在一起的线:订单口径一根线,渠道归因一根线,权限审批一根线,财务对账一根线,老板上次在会上临时改过的规则又是一根线。你不蹲下来摸一摸,很难知道哪根线一拔会让整张桌子晃。
这就是人的价值开始变贵的地方。
第一类价值,是口径判断。
AI 可以帮你写“统计有效订单”的 SQL,但它不知道你们公司有效订单到底怎么算。是付款成功算,还是履约完成算?退款订单扣不扣?售后中的订单算不算?今年的新规则能不能回溯到去年?这些问题不只是技术定义,它们会影响经营会、销售奖金、渠道预算和财务对账。
第二类价值,是证据判断。
AI 可以生成一段“下降原因分析”,但它不知道这次波动是不是因为埋点改版,不知道某张宽表昨天夜里延迟了两个小时,也不知道业务刚刚把一批大客户迁到了新合同。真正的分析不是把所有维度都拆一遍,而是在一堆可能性里判断哪些证据可信,哪些只是碰巧相关。
第三类价值,是权限判断。
AI 问数系统看起来很方便,但谁能问哪些数据?模型能不能返回明细?销售能不能看到客户手机号?区域经理能不能看到全国毛利?这些问题如果不提前设计,工具越好用,风险越大。
第四类价值,是结果责任。
当一个答案被业务拿去做决策,出了问题不能只说“模型这么回答的”。组织最后会问:这个口径谁确认过?这个数据谁开放的?这个结论谁审核的?这个场景是不是本来就不该自动化?
这些问题,AI 不会替组织承担。
它可以帮你更快地生成候选答案,但不能替你决定什么答案可以被使用。
所以数据岗位未来真正保值的部分,不是“我比模型更快”,而是“我知道哪里不能让模型快”。
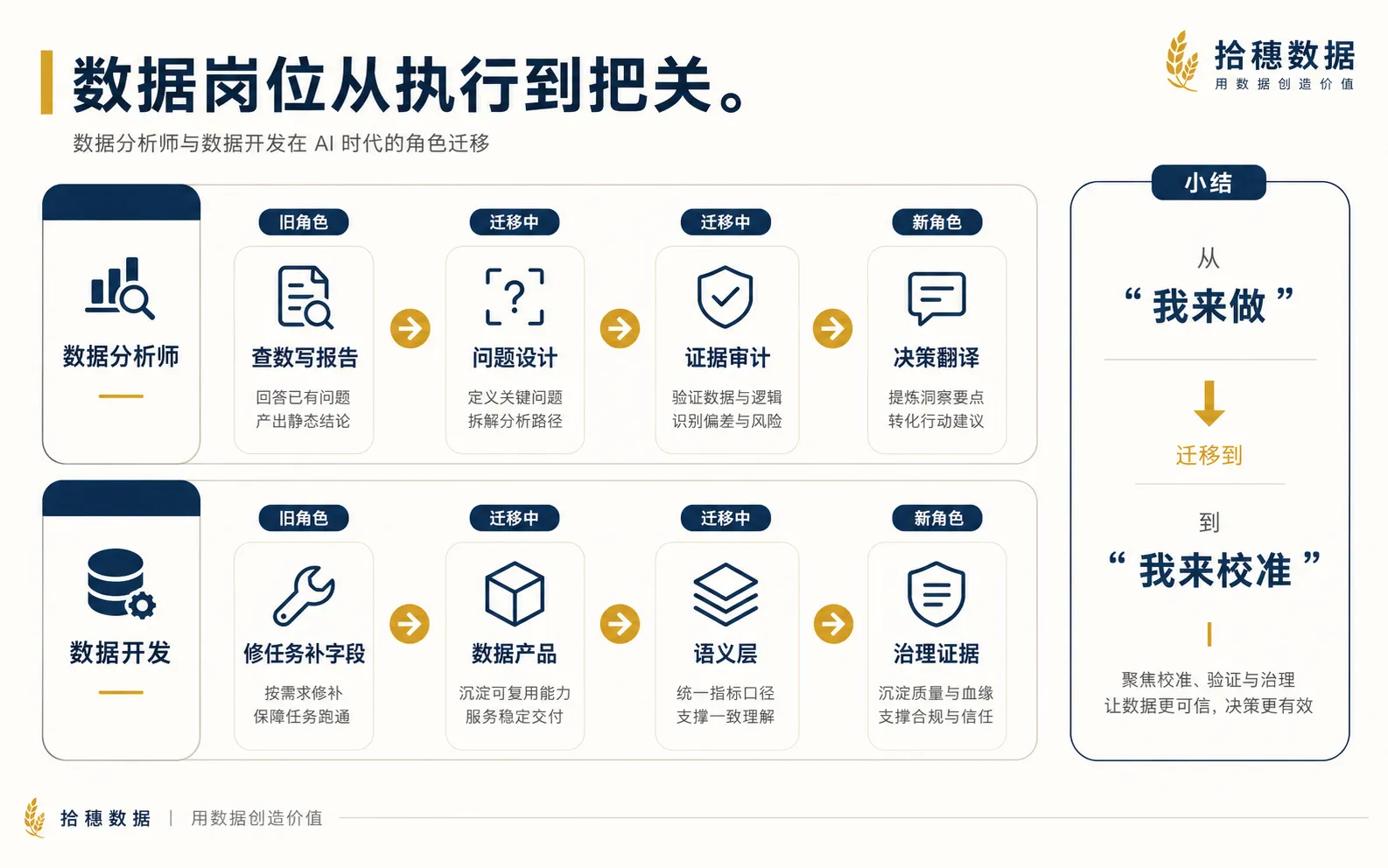
数据分析师会从写报告的人,变成问题和证据的设计者
对数据分析师来说,变化会很明显。
过去,一个分析师的价值经常被理解成三件事:查数、画图、写报告。AI 会让这三件事里的基础动作大幅提速。它可以帮你起草分析结构,生成图表,改写文字,甚至给出一些初步归因。
如果分析师只守着这些动作,确实会被挤压。
但分析师还有更重要的工作:判断问题有没有问对,证据够不够,结论能不能被业务使用。
老板问“为什么销售下降”,AI 可能立刻拆渠道、拆区域、拆品类。好的分析师会先停一下:下降是同比下降,还是环比下降?是销售额下降,还是毛利下降?预算有没有变?供给有没有变?有没有活动档期?有没有统计口径变化?
这不是抬杠。
这是把一个含糊问题变成可验证问题。
以后分析师更像三种角色的合体。
一是问题设计者。业务扔来一句模糊需求,你能把它拆成可查询、可比较、可解释的几个问题。
二是证据审计者。AI 给出一个答案,你能快速判断它引用了哪些数据,漏掉了哪些变量,哪些结论只是看起来顺口。
三是决策翻译者。你能把分析结果翻译成业务下一步能做的选择,而不是只交一页“现象描述”。
这些能力看起来没有写 SQL 那么硬,但更靠近组织里的真实价值。
AI 会让报告更容易生成,也会让烂报告更多。能把报告变成判断的人,反而会更重要。
数据开发会从修管道的人,变成可信数据供给的负责人
对数据开发来说,变化也不是“写代码没用了”。
恰恰相反,数据开发的责任会更靠前。
以前很多数据开发被迫扮演救火队。任务挂了,修;字段缺了,补;报表慢了,调;业务催了,先跑一版临时 SQL。工作很辛苦,但经常被组织看成后台支持。
AI 进入企业以后,数据开发的价值会被重新摆到台前。
因为 AI 应用吃的不是“数据表”三个字,而是可信的数据供给。
一个 AI 问数系统,要知道哪些指标是权威口径,哪些表已经废弃,哪些字段不能暴露,哪些查询需要走审批,哪些答案必须带来源。一个经营助手,要能拿到及时数据,也要知道数据延迟时该怎么提示。一个风控辅助应用,要能追踪答案来自哪些规则、哪些样本、哪些模型版本。
这些事情都离不开数据工程。
只是未来的数据工程不再只是“把表跑出来”。它更像在给智能系统修水管、装阀门、贴标签、留检修口。
水能流,但不能乱流。
数据开发要更主动地把三件事做成资产。
第一,数据产品。核心数据集不是一张没人解释的宽表,而是有口径、有负责人、有适用场景、有质量说明的供给物。
第二,语义层。让指标、维度、业务对象有机器也能理解的定义,而不是靠老员工口口相传。
第三,治理证据。权限、血缘、质量、变更、使用记录都要能查。不是为了写文档好看,而是为了出事时知道从哪里修。
Microsoft 在 2026 年的 Work Trend Index 相关文章里提到,AI 进入组织以后,约束不再只是个人能做什么,而是工作如何围绕 AI 重新设计;被调查的 AI 用户也把 AI 输出质量控制和批判性思考放在重要位置。对数据团队来说,这句话很现实:接入工具只是开始,能管理和校准工具产生的工作,才是长期位置。
不要把学习计划写成工具收藏夹
很多焦虑,最后会落到学习计划上。
一焦虑,就开始收藏工具。今天一个 Agent 框架,明天一个数据分析插件,后天一个自动报表平台。收藏夹越来越满,人越来越空。
工具当然要学。
但工具不是主线。
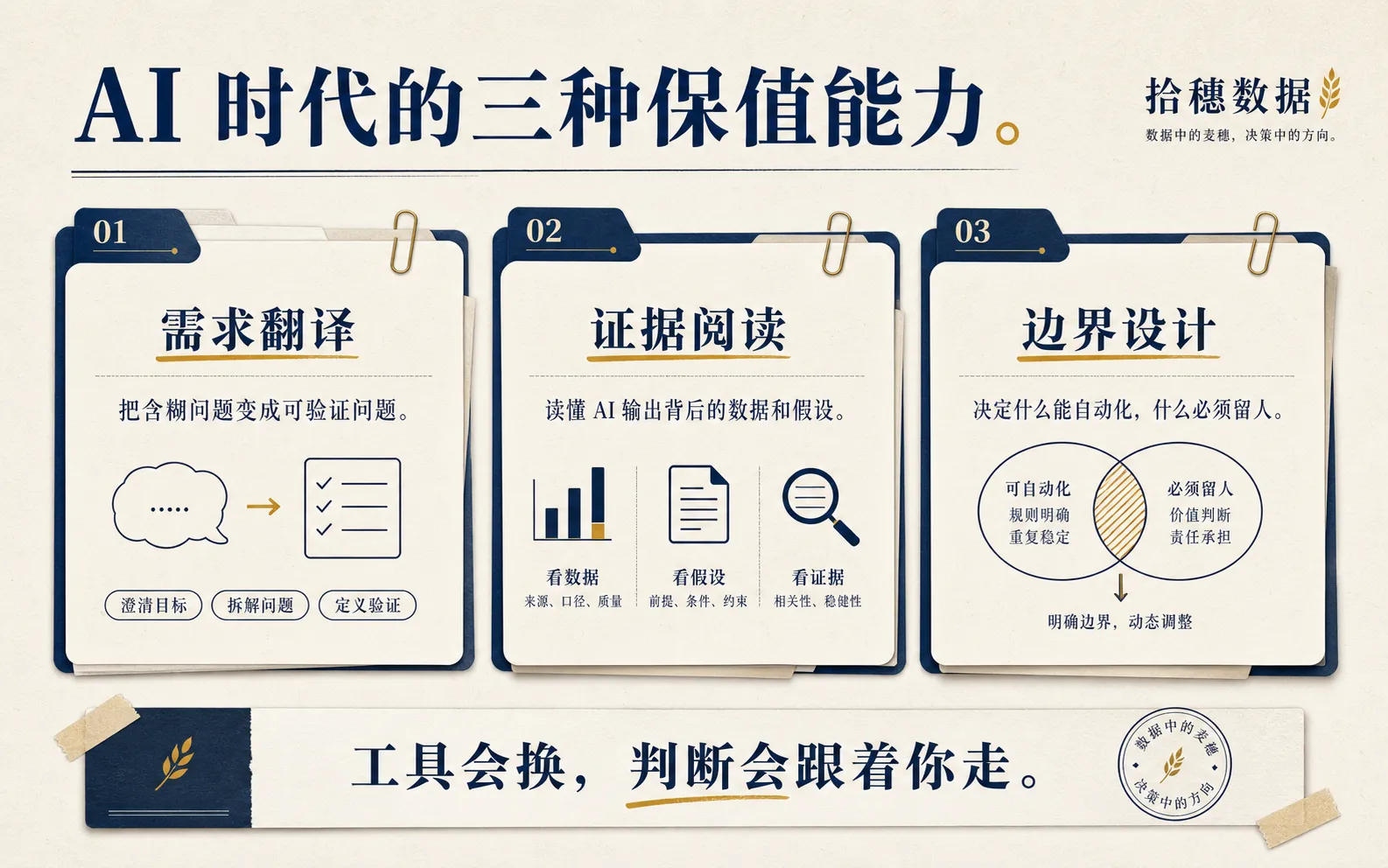
如果你想在 AI 时代保住数据岗位的长期价值,我更建议练三种能力。
第一,需求翻译能力。
你要能把“帮我看看用户情况”翻译成时间范围、用户分群、关键指标、对比口径和可行动问题。翻译得越清楚,AI 越能帮你;翻译不清楚,AI 只会把含糊放大。
第二,证据阅读能力。
以后 AI 输出会越来越多。你要能读它的 SQL,读它的分析,读它引用的数据来源,读它没说出来的假设。不是每个漂亮答案都可信。能读出问题的人,才有资格使用 AI。
第三,边界设计能力。
哪些场景可以自动化,哪些场景必须人工复核?哪些数据可以开放,哪些不能开放?哪些答案可以直接给业务,哪些只能作为参考?这些边界一开始不设计,后面就会变成事故。
这三种能力不是某个工具版本带来的。
它们会跟着你走。
你换公司、换平台、换模型,仍然有用。
下次老板问“还需要数据团队吗”,你可以这样回答
如果下次会议室里有人问:“AI 都能查数了,还需要数据团队吗?”
不要急着防御。
可以顺着这个问题往下问三句。
第一句:它查的是哪一套口径?
如果没有权威口径,AI 只是更快地制造口径冲突。
第二句:它能看到哪些数据?
如果没有权限边界,AI 只是把原来不容易犯的错变得更容易犯。
第三句:它答错了谁来改?
如果没有责任链路,AI 只是把问题从“没人做”变成“没人负责”。
这三句问完,大家通常会发现,数据团队不是没用了,而是角色变了。
以前数据团队常常被看成取数的人、做表的人、修管道的人。以后更应该成为组织里负责数据语义、证据质量、权限边界和结果可信的人。
这不是给自己贴一个更高级的标签。
这是把工作往真正不可替代的地方挪。
从今天开始,你也可以做一个小练习。
把自己本周做过的所有数据工作分成两列:一列叫“动作”,一列叫“判断”。
动作包括写 SQL、导数据、画图、改文档、生成周报。判断包括确认口径、识别异常、拒绝不合理需求、补充证据、设计权限、说明结论适用范围。
然后问自己:哪些动作应该让 AI 或系统接走?哪些判断我还没有留下证据?哪些判断如果我不做,别人就会默认它不存在?
这张表写出来,你会比单纯追工具踏实很多。
AI 不会温柔地等每个人准备好。
它会把便宜的动作变得更便宜,把模糊的责任暴露得更明显,把原来藏在老员工经验里的上下文重新摆到桌面上。
这时候,数据岗位不是简单消失。
它会分化。
只靠动作吃饭的人,会越来越焦虑。能把动作变成系统、把问题变成证据、把边界讲清楚的人,会越来越重要。
如果你问我“数据岗位会不会被 AI 替代”,我的答案是:一部分动作会,甚至会很快。
但真正懂数据、懂业务、懂责任边界的人,不会因为 AI 变得多余。
他们会从屏幕后面走到桌前。

如果你想系统补齐数据治理、AI 应用、指标体系和职业成长这些能力,可以继续看数据从业者全栈知识库。AI 会改变很多工具,但公司里真正难的,仍然是把数据变成可信、可用、可负责的工作方式。
我叫石头,在数据行业里摸爬滚打了十几年,越来越相信一件事:工具越会说话,人越要把边界想清楚。这里写的,就是这些教训——我觉得值得说出来的那部分。
参考资料:World Economic Forum《Future of Jobs Report 2025》 · Anthropic Economic Index · Microsoft 2026 Work Trend Index 相关说明


