一个做数据开发的朋友,最近给我发了一张截图。
截图不是报错日志,也不是 SQL 执行计划,而是他的浏览器收藏夹。里面有提示词教程、Agent 框架、RAG 实战、向量数据库、AI 工作流平台、Text-to-SQL、企业知识库,还有几个“数据人转 AI”的训练营页面。
他说:“我不是不学。我是越学越不知道自己到底要学到哪一步。”
这句话很真实。
现在很多数据从业者学习 AI,像在一个灯火通明的夜市里走路。每个摊位都很热闹,每个摊主都说自己这里是入口。你站在中间,手里拿着十几个链接,最后反而不知道第一步该往哪儿迈。
问题不在于资料太少。
问题在于我们习惯把 AI 能力理解成工具清单:会不会写提示词,会不会调 API,会不会搭一个 RAG Demo,会不会用某个 Agent 框架。
这些当然有用,但它们只是外层。
对数据从业者来说,AI 能力真正该长成一张地图。它不是从 SQL 一步跳到大模型,也不是从报表一步跳到“AI 工程师”。它更像一条从公司日常数据工作里长出来的路:先能把数据说清楚,再能让 AI 帮自己做事,然后参与智能应用建设,最后负责这个应用的可靠性、边界和结果。
换句话说,数据从业者的 AI 升级,不是换一个更时髦的岗位名字。
它是从“我能把数取出来”,走向“我能让数据进入智能系统,并且让这个系统可控、可信、可用”。
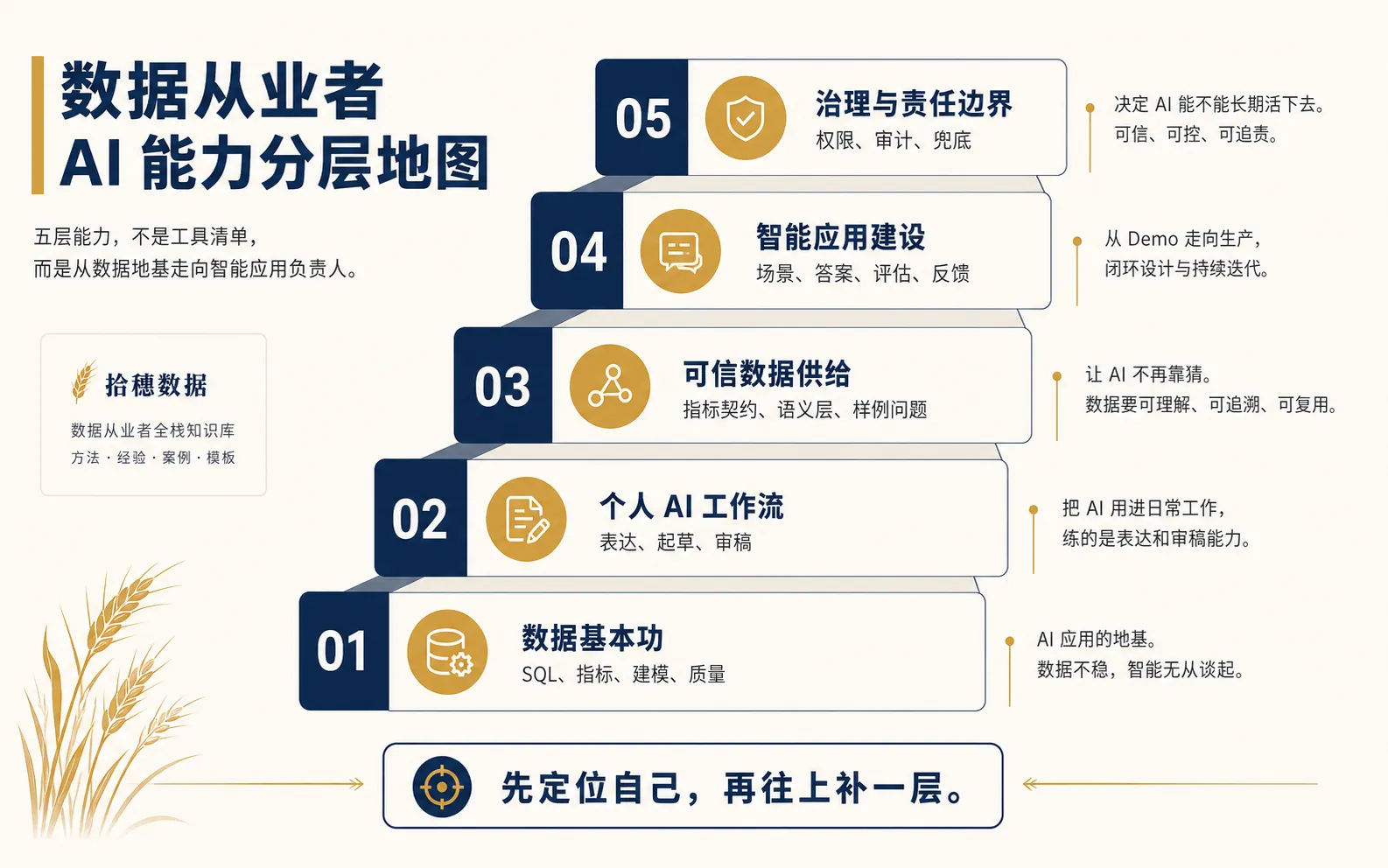
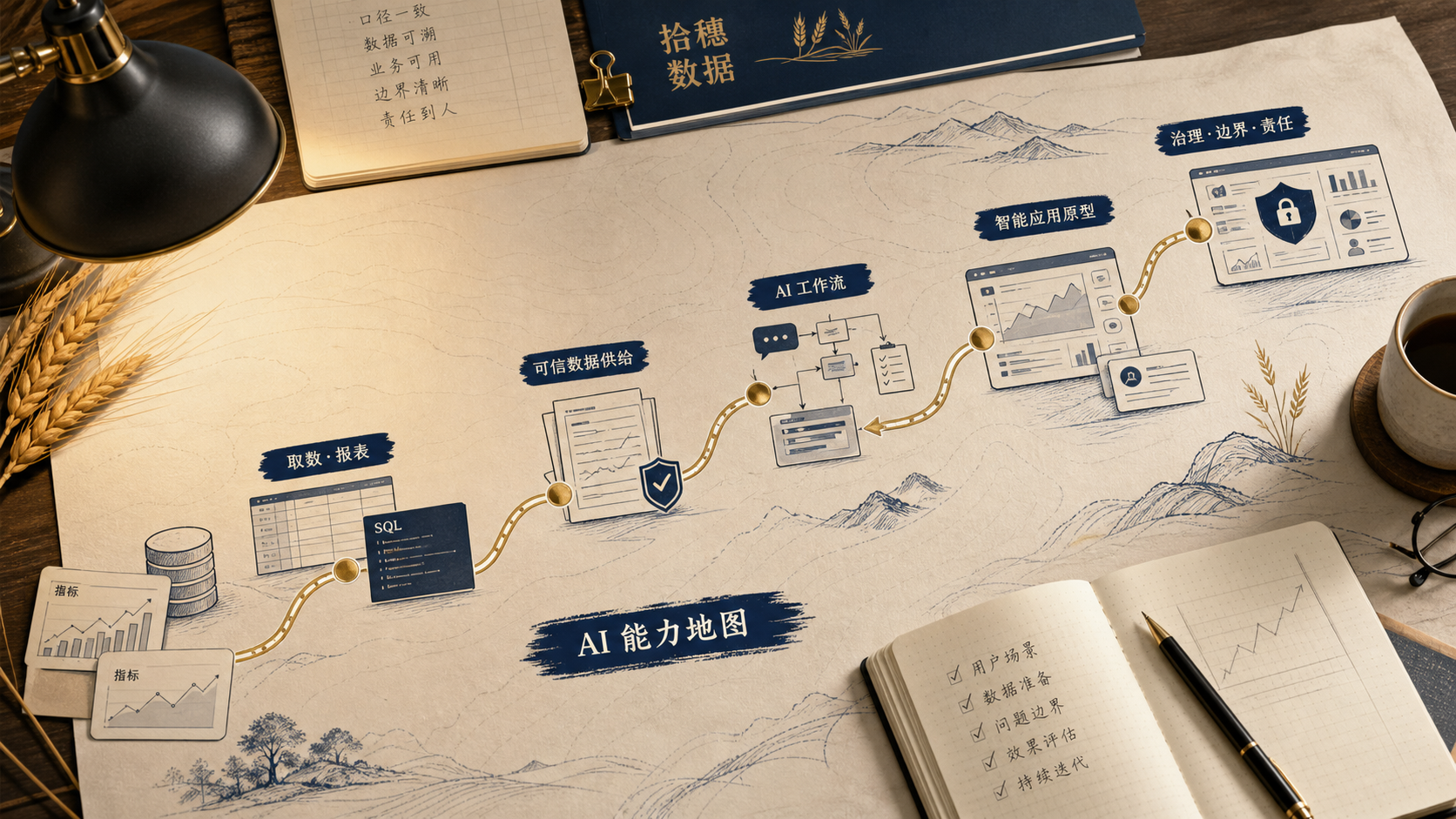
先把地图画出来:五层能力,不是一堆工具
如果只用一句话概括这张地图,我会这么说:
数据从业者的 AI 能力,可以分成五层。
第一层,数据基本功。包括 SQL、指标口径、数据建模、任务调度、质量监控、权限和血缘。这些东西听起来不新,但 AI 进入企业后,最先暴露的往往就是这些旧账。
第二层,个人 AI 工作流。把 AI 用进自己的日常工作,比如辅助写 SQL、拆需求、整理访谈、检查文档、生成分析初稿。目标不是炫技,而是把重复动作降下来,把注意力留给判断。
第三层,可信数据供给。把原来只给人看的数据,整理成 AI 也能使用的供给:指标契约、语义层、数据说明、样例问题、可追溯来源和质量边界。
第四层,智能应用建设。参与 AI 问数、经营助手、知识检索、异常归因、客服辅助、风控提示这类应用的设计。你不一定要从零训练模型,但要懂场景、数据、检索、查询、答案生成、人工反馈和效果评估之间的关系。
第五层,治理与责任边界。AI 应用一旦进入真实业务,就会遇到权限、审计、解释、监控、错误纠正和责任归属。越到后面,这一层越决定系统能不能长期活下去。
这五层里,越往上越接近业务结果,越往下越接近数据地基。
很多人的焦虑,是跳层造成的。
数据底座还没理清,就急着学 Agent 编排;个人工作流还没用顺,就急着做企业应用;问数 Demo 还没评估,就急着接生产库。这样学,当然会乱。
一张地图的价值,不在于让你一次走完,而在于告诉你:你现在在哪一层,下一层是什么,以及哪些路暂时不用走。
第一层:数据基本功不是旧能力,而是 AI 的地基
很多人一提 AI,就觉得 SQL、数仓、指标、权限这些东西“旧了”。
我反而觉得,这些旧能力正在重新变贵。
原因很简单:AI 应用一旦进入企业,就不是在互联网上随便聊天,而是在公司的真实数据里回答问题、生成建议、触发动作。它要查的是订单、客户、库存、合同、客服记录、营销活动、财务口径、经营指标。
这些东西如果本来就乱,AI 只会更快地把混乱展示出来。
一个 AI 问数系统回答错了,不一定是模型不聪明,可能是“有效订单”本来就有两套口径。一个经营助手给出错误建议,不一定是提示词写得差,可能是数据延迟了两个小时。一个客服知识库答非所问,不一定是 RAG 架构不行,可能是知识源没人负责、版本没人更新。
所以第一层能力,不是“低级能力”。
它是所有智能应用的地基。
这一层至少要能回答六个问题:
- 核心指标从哪些表来?
- 指标口径是谁确认的?
- 数据更新频率和延迟是多少?
- 哪些字段有质量风险?
- 哪些人可以访问哪些数据?
- 答案出错后能不能追到来源?
如果这六个问题答不清,先别急着说自己要转 AI。
你真正该做的是把当前业务里最常用的 5 个指标、3 张核心表、10 个高频问题整理出来。它们比你收藏 20 个 Agent 框架更值钱。
第二层:个人 AI 工作流,练的是表达和审稿
第二层,是把 AI 用进自己的工作。
这一层很适合个人先练,不用等公司立项,也不用等老板批准。
你可以让 AI 帮你做很多事:
- 把一句模糊需求拆成澄清问题;
- 根据表结构生成 SQL 初稿;
- 解释一段旧 SQL 的业务含义;
- 把需求访谈整理成字段清单;
- 给分析报告补一版结构;
- 检查指标口径说明里哪些地方容易误解;
- 把一次项目复盘改成能放进简历的表达。
但这里有个很重要的边界:AI 可以帮你起草,不能替你判断。
很多人用了 AI 以后,工作流只是变成“复制需求,粘贴给模型,复制输出,发给别人”。这不是升级,只是换了一种偷懒方式。短期看很爽,长期看会削弱自己的判断肌肉。
个人 AI 工作流真正训练的,不是“会不会写提示词”。
它训练的是两种能力。
第一,表达能力。你能不能把问题说清楚:背景是什么,数据范围是什么,字段含义是什么,输出格式是什么,判断标准是什么。
第二,审稿能力。AI 给你一段 SQL、一份报告、一组建议,你能不能看出哪里是事实、哪里是假设、哪里缺证据、哪里可能误导业务。
表达和审稿,才是这一层的核心。
你可以给自己定一个小规则:每次让 AI 参与数据工作,都留下两份东西。
一份是你的输入,看看自己有没有把问题讲清楚。
一份是你对 AI 输出的修改记录,看看你到底在哪些地方比模型更懂业务。
这两份东西积累多了,你会发现自己的 AI 能力不是“会用工具”,而是“能让工具在正确边界内帮你”。
第三层:可信数据供给,让 AI 不再靠猜
很多公司做 AI 问数,第一反应是“把数据库接上”。
这一步听起来很自然,实际非常危险。
数据库里有表,不代表 AI 能理解业务。表名叫 dwd_order_detail,字段叫 pay_amt,人类老员工可能知道它的坑:预售尾款怎么算,退款什么时候扣,异常订单是否排除,历史分区有没有回刷。但模型不知道。


