
AI 写 SQL 越快,数据人越容易背锅。
这句话有点难听。
可是我最近越来越觉得,它不是一句反 AI 的气话,而是很多数据团队马上会遇到的日常。
想象一个很普通的周三下午。会议室里空调有点冷,屏幕上投着一张渠道复盘表。老板问:“为什么上周新客转化率掉了 8 个点?”
数据同学打开 AI 问数工具,输入一句话:
看一下上周各渠道新客转化率,和前一周对比。
十几秒后,SQL 出来了,表也出来了,图也出来了。所有人都松了一口气。工具真好,速度真快,比以前翻口径、找表、复制老 SQL 省事多了。
然后运营同学盯着屏幕看了半分钟,说:“不对啊,这个渠道上周明明有一批未转化用户,怎么分母里没了?”
会议室里会安静一下。
因为 SQL 没报错,图也很漂亮。问题只是藏在一个很小的地方:模型把原来应该保留未匹配用户的 LEFT JOIN,写成了更顺眼的 INNER JOIN。
这时最尴尬的人,不是 AI。
是坐在旁边的数据同学。

可怕的不是写错,是错得很像对
以前 SQL 写错,很多时候会报错。
字段不存在、表名写错、括号少了一个,数据库会直接给你一串红字。红字虽然难看,但它很诚实,像一个在门口摔了一跤的人,至少大家知道他没进屋。
AI 写 SQL 最麻烦的地方在于,它经常不摔跤。
它走得很稳。
缩进整齐,别名规范,字段名看着也对,甚至还会附上一段解释:“本查询统计了各渠道新客转化率,并按周环比计算变化。”
这段话一出来,很多人会本能地相信它。因为它不像临时写出来的,它像一个懂行的人写的。
可是数据工作里,很多坑并不在语法里。
它们藏在这些地方:
- 新客按注册算,还是按首单算;
- 渠道归因用首次来源,还是最近一次来源;
- 未转化用户要不要保留在分母里;
- 退款订单、测试账号、内部账号怎么排除;
- 活动周期跨周时,时间窗口怎么切。
这些问题不属于 SQL 语法题。
它们属于公司内部的业务约定。
模型如果不知道这些约定,就只能猜。猜对的时候,大家觉得它很聪明。猜错的时候,结果也不一定离谱,只是悄悄偏了。
这就是 AI 问数最危险的地方:它把“还需要判断”的东西,包装成了“已经算完”的答案。
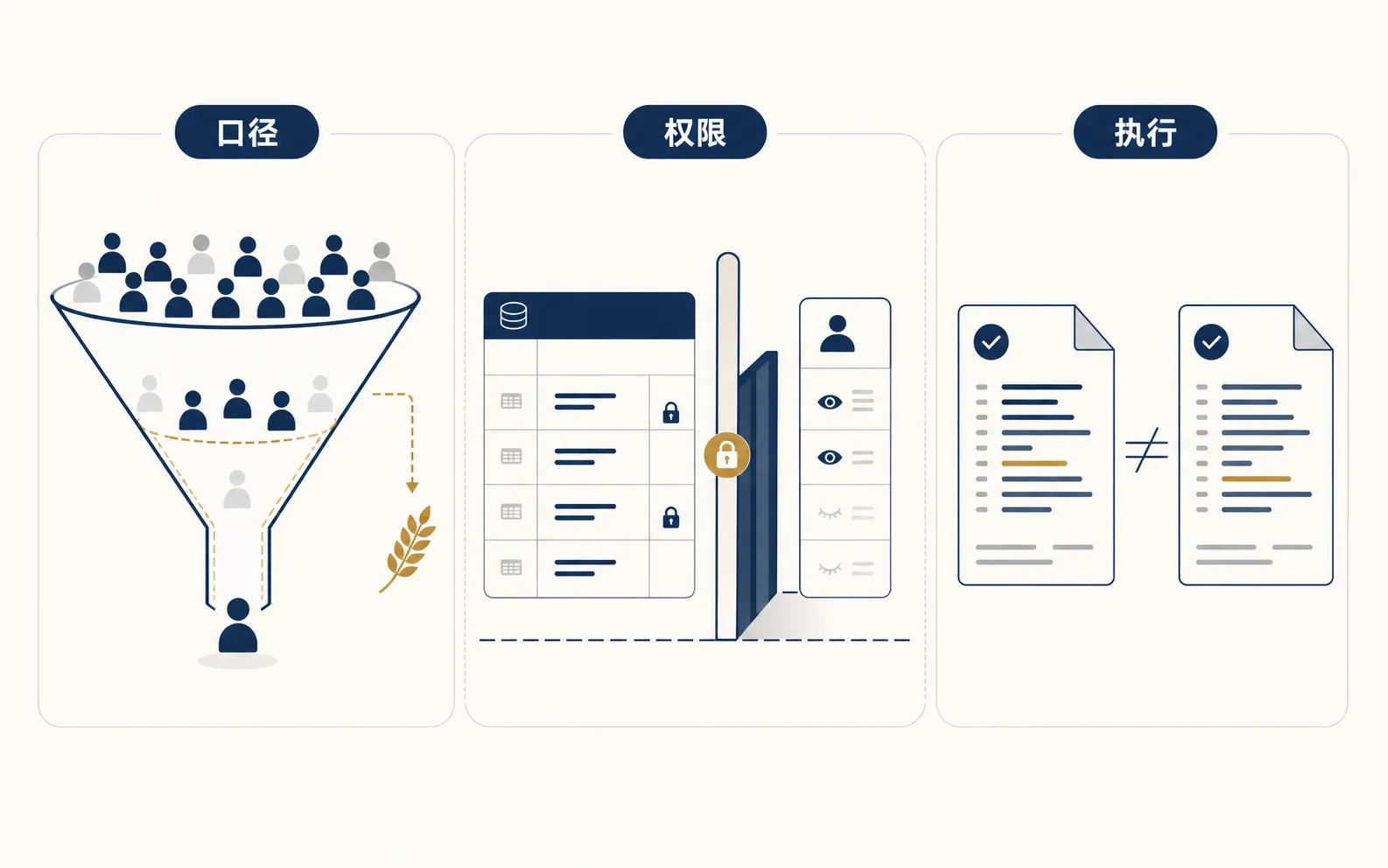
第一口锅:模型替你改了口径
很多人以为 AI 写 SQL 的风险是“它不会写复杂查询”。
我倒觉得,复杂查询反而没那么可怕。
复杂 SQL 一出来,数据同学通常会谨慎一点,多看几眼,多跑几个样例。真正容易让人放松的是那些看起来很简单的问题。
比如:
看一下本月新客转化率。
这句话短得像一句家常话。
可它背后至少有四个选择:
- 新客是谁;
- 转化是什么;
- 分母保留谁;
- 统计窗口从哪一天到哪一天。
如果公司里没有统一指标定义,模型会自己补齐这些选择。它可能把“注册用户”当新客,也可能把“首单用户”当新客;它可能把未转化用户保留在分母里,也可能在 join 的过程中把他们过滤掉。
最后 SQL 跑出来了。
老板看到的是一个数字。
业务看到的是一个结论。
数据同学看到的是一段看似正常的 SQL。
等到复盘翻车,大家不会去找模型开会。模型也不会坐在会议室里解释:“我当时根据字段名推断了一下。”
最后要解释的人,还是数据团队。
所以第一口锅,不是技术锅。
是口径锅。
AI 只是让这口锅来得更快。
这口锅具体长什么样?
可以看一个很小的例子。
假设业务要看“各渠道新客转化率”。正确的思路通常是:先从新客人群出发,把所有新客放进分母;再去关联订单、转化或行为表,看其中有多少人完成了转化。
也就是说,未转化的人也必须保留。
如果模型写成这样:
select u.channel, count(distinct o.user_id) * 1.0 / count(distinct u.user_id) as conversion_ratefrom new_users ujoin orders o on u.user_id = o.user_idwhere u.register_date between '2026-06-01' and '2026-06-07'group by u.channel;看起来没有大问题。
可是这个 join 已经把没有订单的新客过滤掉了。分母被悄悄缩小,转化率自然变漂亮。
更稳的写法应该先保留全部新客:
select u.channel, count(distinct case when o.user_id is not null then u.user_id end) * 1.0 / count(distinct u.user_id) as conversion_ratefrom new_users uleft join orders o on u.user_id = o.user_id and o.pay_date between '2026-06-01' and '2026-06-07'where u.register_date between '2026-06-01' and '2026-06-07'group by u.channel;这不是为了教你背 SQL。
而是为了说明:AI 写出来的 SQL,审核时不能只看语法。你要先问 3 个更笨的问题:
- 这条 SQL 的分母从哪张表开始;
- 没有匹配到下游记录的人,会不会被保留;
- 过滤条件是放在
where里,还是放在join on里。
这 3 个问题问完,很多“看起来很顺”的 SQL 会露出马脚。
第二口锅:模型替你越过了边界
AI 问数还有一个更隐蔽的问题:它可能拿到了不该拿的数据。
公司里的数据表不是平等的。
有些表是正式宽表,有些是临时加工表;有些字段能看,有些字段只能特定角色看;有些明细可以给运营,有些只能出聚合结果。
人写 SQL 的时候,很多边界靠经验记住。
比如某张表已经废弃,某个字段只用于历史回填,某个明细涉及个人信息,某个客户标签不能直接暴露给一线团队。
这些经验平时不显眼。
可是模型没有这种“心里有数”。如果你把 schema、字段说明、样例数据都丢给它,它就会努力完成任务。用户问什么,它就找能回答的表。
问题是,能回答,不代表该回答。
一个很常见的场景是:业务问“哪些客户最近可能流失?”
模型可能去找订单表、客服记录、行为日志、客户标签。它很努力,甚至很全面。可是其中一些字段可能涉及敏感信息,另一些字段可能只是算法中间产物,并不该直接给业务看。
这时如果系统没有权限边界,没有字段级控制,没有回答降级规则,数据同学也会被推到前面。
业务会说:“工具里出来的。”
老板会问:“这个数据能不能用?”
合规会问:“这个字段为什么被调出来?”
你会发现,AI 问数不是把 SQL 写快这么简单。
它把数据团队过去靠经验、流程和默契守住的边界,一次性放到了系统设计里。
以前边界在人的脑子里。
现在边界必须进系统。
第三口锅:用户审核的不是最终执行的那条 SQL
还有一类问题,听起来很工程,但非常要命。
用户看到的 SQL,和最终执行的 SQL,是不是同一份?
很多 AI 问数系统里,模型先生成一版 SQL,前端展示给用户。用户看了一眼,觉得没问题,点执行。
可是执行前,系统可能还会做改写。
比如补权限条件,补时间分区,替换表名,加 limit,做性能优化,甚至重新规划 join 顺序。
改写本身不一定错。
问题是,用户审核的是 A,系统执行的是 B。出了问题以后,大家拿着 A 复盘,实际跑出去的是 B。
这就像你签了一份合同,盖章前有人“顺手优化”了几行字。
字还是那些字,意思可能已经变了。
生产系统里最怕的不是复杂。
是不可追踪。
如果 AI 问数要进入真实业务,就必须能回答:
- 用户原始问题是什么;
- 模型理解成了什么指标;
- 召回了哪些表和字段;
- 中间结构是什么;
- 用户审核了哪份 SQL;
- 最终执行了哪份 SQL;
- 结果被谁用于什么场景。
这些东西听起来麻烦。
可是数据团队真正的安全感,就是从这些麻烦里长出来的。
上线前,先拿这 10 项过一遍
如果你现在就在公司里参与 AI 问数,不管它叫 Text-to-SQL、智能 BI、数据 Agent,还是老板口中的“那个能直接问数的东西”,我建议你先准备一张检查表。
不用写得很漂亮。
能在评审会上逐项问出来就行。
第一,问题池有没有收敛。
先覆盖 20 个高频问题,不要一上来承诺全库自然语言问数。
第二,指标有没有机器可读的定义。
每个核心指标至少写清楚:名称、分子、分母、时间窗口、过滤条件、适用场景、负责人。
第三,表有没有白名单和黑名单。
正式表、临时表、废弃表、敏感表要分开,不要让模型在全库里自由散步。
第四,字段有没有权限等级。
客户明细、手机号、身份证、合同金额、薪酬、个人行为日志,这些字段不能因为模型能读就默认能答。
第五,join 关系有没有约束。
哪些表可以关联,按什么键关联,哪些关联会改变分母,这些规则应该写出来。
第六,时间窗口有没有默认规则。
“本周”“最近 7 天”“上个月”在不同团队里可能不是一回事。别让模型自己理解自然语言里的时间。
第七,审核 SQL 和执行 SQL 是否一致。
如果系统执行前会改写 SQL,就必须留下改写记录,不能让用户审 A、系统跑 B。
第八,有没有回归样例。
挑 20 个老问题,保存历史 SQL 和人工确认结果。每次模型、提示词、语义层更新后,都跑一遍。
第九,日志能不能复盘。
至少要保留原始问题、识别指标、使用表字段、生成 SQL、执行 SQL、结果版本和提问人。
第十,谁有最后解释权。
AI 可以给答案,但经营会、预算会、考核会里,必须有人能解释这个数为什么可信,或者为什么不能用。
这 10 项不是为了把项目卡死。
恰恰相反,它是为了让 AI 问数能真的走进生产,而不是永远停在 Demo 视频里。
数据同学不是要拒绝 AI,而是要重新定义自己的位置
我不赞成把 AI 写 SQL 当成洪水猛兽。
说实话,它确实有用。
很多临时取数、探索分析、字段查询、SQL 草稿,以后都会被 AI 大幅压缩时间。以前一个新人要翻半小时表,现在可能 30 秒就能拿到第一版查询。
这不是坏事。
坏的是另一种想法:既然 AI 会写 SQL,数据同学就只需要点一下确认。
这就把数据工作看得太薄了。
数据同学真正值钱的地方,从来不只是会写 SELECT。而是知道一个数能不能被相信,什么时候不能比较,哪些字段不能乱用,哪个口径会让业务误判,哪张表只是看起来像真相。
AI 让 SQL 变便宜以后,这些判断会变得更贵。
以前你写得快,别人觉得你厉害。
以后 AI 也写得快,甚至比你更快。那你还能靠什么站住?
靠审核。
靠口径。
靠边界。
靠把“这个数到底能不能用”说清楚。
这不是一句漂亮话。
它会变成一类新工作:把过去写在脑子里、藏在群聊里、散在老 SQL 里的判断,整理成系统能识别、同事能审核、出了问题能复盘的东西。
以前这些事常常被叫作“经验”。
以后它们会变成数据团队的生产资料。
AI 不是把这些经验抹掉。
它只是逼你把它们说清楚。
这周如果只做一件事,先别急着全员开放
很多公司做 AI 问数,最容易犯的错,是一开始就想做大。
“让所有业务都能自然语言问数。”
这句话听起来很诱人,也很适合写进汇报 PPT。
可是生产里更稳的做法,是先挑 20 个高频问题。
不要选最炫的。
选最常被问的。
从过去一个月的群聊、周报、经营会、临时取数记录里找:
- 哪些问题被反复问;
- 哪些 SQL 被反复复制;
- 哪些指标每次都要解释;
- 哪些看板总被截图问“这个数准不准”;
- 哪些取数需求最后总会变成争议。
你可以直接建一个很简单的表,别一开始就上复杂平台:
| 字段 | 记录什么 |
|---|---|
| 原始问题 | 业务当时怎么问的,尽量保留原话 |
| 使用场景 | 经营会、日报、活动复盘、渠道投放、老板临时追问 |
| 指标口径 | 分子、分母、时间窗口、过滤条件 |
| 涉及数据 | 表、字段、权限等级、是否有敏感信息 |
| 历史 SQL | 过去人工确认过的 SQL 或看板链接 |
| 风险点 | 容易错在哪里:分母、join、时间、退款、权限、口径变更 |
这张表不用一次填完。
先把反复出现的 20 个问题填进去。填的过程中,你会很快发现:所谓 AI 问数上线,最缺的不是模型,而是这些问题背后的口径资产。
把这 20 个问题做稳,比一开始宣称“全库问数”靠谱得多。
因为它们已经证明了两件事:业务真的需要,数据团队也真的被重复消耗。
先把这些问题的指标定义、权限边界、SQL 审核链路补上。再考虑让更多人用。
这件事不酷。
但生产系统里,很多真正有用的东西都不酷。
它们像会议室里那杯放凉的茶,没人拍照发朋友圈,但没有它,你撑不到下半场。
AI 会继续写 SQL。
而且会越写越快。
数据同学要做的,不是和它比赛谁敲键盘更快。
是把它写出来的东西,放进一套能追问、能审核、能复盘的工作流里。
否则,速度会先变成掌声。
再变成锅。

如果你也在公司里试 AI 问数,可以在评论里说说:你最担心的是 SQL 写错,还是业务口径被模型猜错?
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些教训——我觉得值得说出来的那部分。


