
AI 写 SQL 最吓人的时候,不是报错。
报错反而好办。红字一出来,大家都知道它坏了。
真正麻烦的是,它写出一条看起来很顺的 SQL。缩进整齐,字段名对,表也找到了,跑起来还有结果。
直到有人发现,原来的 LEFT JOIN 被它改成了 INNER JOIN。
那一刻,会议室里会安静一下。
因为结果不是空的,也不是离谱的。它只是悄悄少了一批人:那些没有发生转化、没有匹配到下游记录、但正是业务最应该关心的人。

这类错误很难被肉眼第一时间抓住。
它错得很像对的。
直接让模型写 SQL,像让实习生蒙着眼找仓库
很多 AI 问数 Demo 都很漂亮。
你输入一句:“看一下上周各渠道新客转化率。”
系统返回 SQL、表格、图表,甚至还附一段解释。第一次看,会觉得未来已经到了。
可是做过数据工作的人都知道,真正的问题很少出在“会不会写 SELECT”。
问题通常出在这些地方:
- 新客到底按注册算,还是按首单算?
- 渠道归因用首次来源,还是最近一次来源?
- 未转化用户要不要保留在分母里?
- 退款订单要不要剔除?
- 测试账号、内部账号、异常订单在哪里排?
这些问题不在 SQL 语法里。
它们在公司的业务约定里。
如果模型不知道这些约定,它就只能靠字段名、表名和训练里的常识猜。猜对的时候很神奇,猜错的时候也很自然。
这就是直接 SQL 生成的危险:它看起来像自动化,其实很多时候是自动猜测。
第一类错误:生成错误
有些错误,是模型推理方向大体对了,但 SQL 写错了。
比如 LEFT JOIN 被写成 INNER JOIN。
比如 NOT IN 遇到 NULL 后出现静默错误。
比如排名、TopN、去重、窗口函数写法有细微问题。
这类错误很讨厌,因为它不一定会报错。数据库会认真执行,并且给你一个结果。
如果只是写日报,这个结果可能被复制进表格。如果是在经营会里,它可能会被拿来解释一个业务变化。如果是在投放场景里,它可能会影响预算。
AI 问数最需要防的,不是“它不会写 SQL”。
而是“它写了一条能跑、但业务含义变了的 SQL”。
这类问题不能只靠 prompt。
你当然可以在提示词里写:“请注意 LEFT JOIN,不要改成 INNER JOIN。”问题是,下一个场景可能是 NOT IN,再下一个场景可能是窗口边界,再下一个场景可能是分母被过滤。
靠提醒模型记住所有坑,本质上还是靠运气。
第二类错误:业务逻辑错误
还有一类更深的错误:SQL 没错,但业务逻辑错了。
比如用户问“复购率”,模型不知道分母是谁。
是所有首购用户?活动新客?支付成功用户?剔除退款后的用户?还是某个渠道带来的用户?
如果公司内部没有语义层,没有指标定义,没有口径说明,模型就会自己补。
它补得越流畅,越容易让人放松警惕。
很多企业做 AI 问数,第一反应是把更多表喂给模型。表越多,字段越多,文档越多,好像它就越聪明。
可是真正的问题不是材料不够,而是边界不清。
你把 200 张表扔给模型,如果没有告诉它哪些表能用、哪些指标怎么算、哪些字段有权限、哪些口径已经废弃,它只是多了一片更大的迷宫。
模型不怕迷宫。
怕的是你不知道它从哪条路走出来。
这里还有一个容易被忽略的事实:SQL 只是最后的表达。
在 SQL 出来之前,系统已经做过一连串判断。它召回了哪些表,理解了哪个指标,把哪个字段当成分母,把哪个条件放进过滤,把哪个 join 关系当成理所当然。
如果这些中间过程都不可见,数据同学最后看到的只是一段代码。你可以审语法,可以审字段,却很难审它为什么走到了这个答案。
这也是为什么“让模型解释一下”不够。解释也是生成出来的,它可能很像理由,但未必是真正的决策路径。
可信问数,不能只看回答像不像人话
一个 AI 问数系统是否可信,至少要回答 5 个问题。
第一,它知道哪些表可以用吗?
不是所有表都该被问。临时表、测试表、内部敏感表、过期表,都应该有边界。
第二,它知道指标定义吗?
GMV、复购率、活跃用户、留存、转化,这些词不能靠模型猜。
第三,它生成的中间过程能不能被约束?
如果模型直接吐 SQL,人只能事后审。更稳的方式,是让它先生成结构化的中间表示,再由确定性编译器翻译成 SQL。
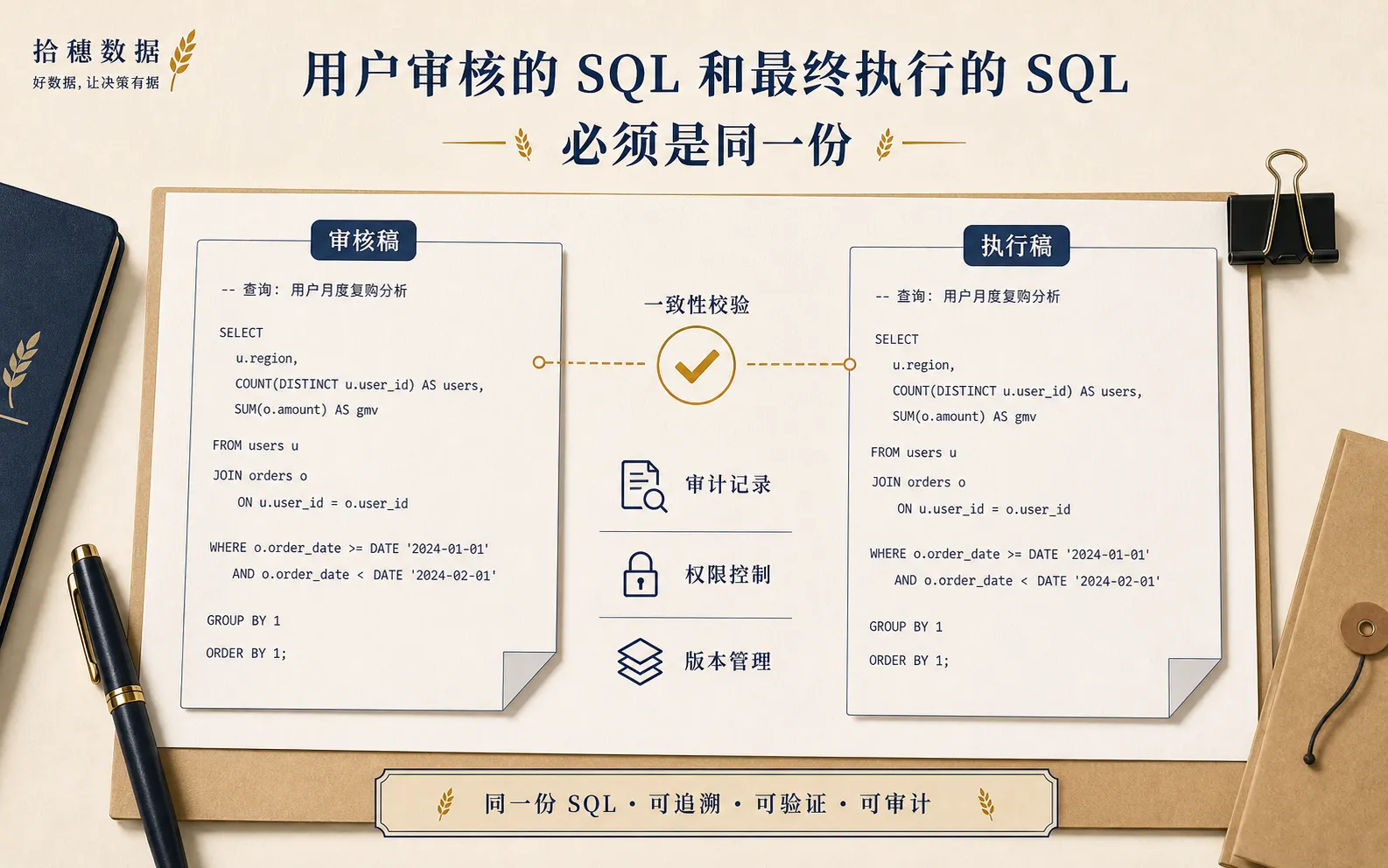
第四,用户审核的 SQL 和最终执行的 SQL 是不是同一份?
很多系统中间会做改写。改写不是不行,但用户要知道执行的到底是什么。
第五,错了以后能不能定位是哪一类错?
是表召回错、指标理解错、SQL 生成错、权限错,还是业务问题本身没说清?
如果这些问题答不上来,AI 问数就还停留在演示阶段。
能演示,不等于能生产。
为什么我做 Forge
我做 Forge,不是因为世界上缺一个聊天框。
聊天框太多了。
真正让我不舒服的是另一件事:很多 AI 问数产品演示时很顺,一到上线评审,就没人敢回答一个简单问题。
“它最后执行的 SQL,和我审核的 SQL 是同一条吗?”
还有一个更麻烦的问题:
“如果它把分母改了,我们怎么知道?”
这两个问题听起来不酷,但很致命。因为数据团队不是在玩 Demo。一个错误的 SQL,可能会进经营会、预算表和老板的判断里。
所以 Forge 做的不是“再写一个聊天框”。它更像一个给数据团队用的 AI 查询 Agent,目标很直接:让弱模型也能生成更可信的 SQL。
这个项目还在早期阶段,但它有一个清楚的判断:生成错误和业务逻辑错误,应该尽量被系统性消灭,而不是靠更好的 prompt 碰运气。
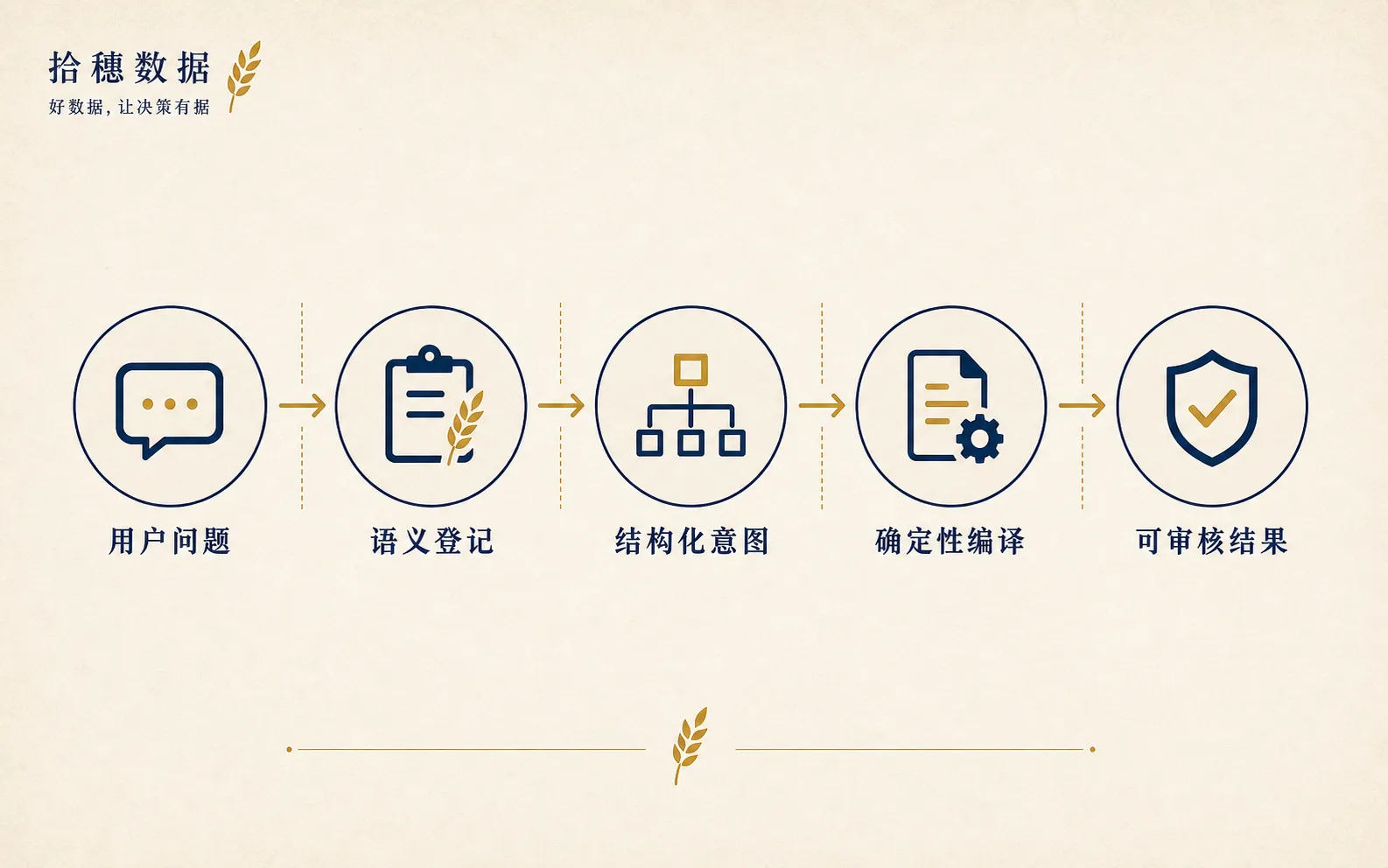
现在的核心思路是三段。
第一段,Registry。
它不只是存表结构,还要放语义层:指标定义、字段解释、歧义消解、权限边界。自然语言进来以后,先从 Registry 里找相关表和业务约定。
第二段,Forge JSON。
模型不直接写最终 SQL,而是生成一个有约束的中间表示。这个结构被 JSON Schema 约束,减少模型随手乱写的空间。
第三段,确定性编译器。
编译器把 Forge JSON 翻译成 SQL。用户审核的 SQL 和执行的 SQL 是同一份,不在运行时再偷偷变形。
这套链路听起来比“直接问模型”麻烦。
是的,它确实麻烦。
可是生产系统里的可信,很多时候就是由这些麻烦组成的。
Forge 仓库里也写得很坦白:这个方向还在早期,不能只展示成功样例,也要把失败边界讲清楚。AI 问数最怕的不是“还不够强”,而是把不确定性包装成确定答案。
Forge 是开源的,代码和目前的设计说明都放在这里:https://github.com/shisuidata/Forge
数据团队该怎么用 AI 写 SQL
如果你现在就在公司里试 AI 问数,我建议先别急着让所有人随便问。
可以从 3 件小事开始。
第一,挑 20 个高频问题。
不要一上来覆盖全库。先找经营会、运营复盘、渠道分析里最常见的 20 个问题,看它们对应哪些表、哪些指标、哪些权限。
这 20 个问题最好不是坐在会议室里拍脑袋想出来的。
你可以从过去一个月的群聊、周报、临时取数记录里捞。哪些问题被反复问,哪些 SQL 被反复复制,哪些指标每次都要解释,哪些看板总有人截图问“这个数准不准”。这些才是 AI 问数最应该先覆盖的场景。
因为它们已经证明了两件事:业务真的需要,数据团队也已经被重复消耗。
先把这些问题做稳,比一开始宣称“全公司都可以自然语言问数”靠谱得多。
第二,把指标定义写清楚。
不是写给人看的大段文档,而是写到系统能用的程度:名称、分母、分子、时间窗口、过滤条件、适用场景。
第三,保留 SQL 审核。
至少在早期,AI 生成的 SQL 不应该直接执行到业务决策里。数据同学要能看到它用了哪些表、哪些条件、哪些 join,并且能修改。
这 3 件事很土。
但它们比“换一个更强模型”更接近生产。
模型会越来越强,这是好事。可是公司的业务语义不会自动变清楚,指标口径不会自动统一,权限边界不会自动出现。
这些东西,还是要数据团队自己补。
AI 写 SQL 是一个很好的开始。
但真正值钱的,不是让模型替你写几行代码。
是让它在一套可信的语义和工程约束里工作。
否则它越聪明,你越不敢信。
我叫石头,在数据行业里摸爬滚打了十几年,也在做 Forge 这类 AI 问数工具。这里写的,就是这些教训——我觉得值得说出来的那部分。


