周五晚上 10 点,群里突然亮了一下。
“今天经营看板的订单数不对。”
这种消息有一种特殊的杀伤力。它不大声,但会让做数据开发的人把外卖盒盖上,把电脑重新打开。
一开始大家以为是同步延迟。后来发现不是。上游一个字段枚举变了,下游清洗逻辑没有接住,导致一批订单被过滤掉。经营看板、渠道报表、活动复盘,全都受影响。
运营同学在群里问:“那下午那版复盘 PPT 还能用吗?”
财务同学问:“我们已经按这个数给老板发过日报了,要不要撤回?”
数据同学一边查血缘,一边把“可能影响”四个字打进文档。这个词很轻,落到具体人身上就很重。因为它意味着,有些人已经拿着错数开过会了。
接下来 48 小时,团队把任务修了,把历史数据补了,把看板恢复了,还给业务发了说明。
事情看起来结束了。
直到周一复盘,负责人问了一句:
“除了这次修完,我们怎么保证下次不是同一个姿势再摔一次?”
会议室又安静了。
很多数据事故最麻烦的地方,不是修不完。
是修完以后,大家太想把它翻篇。
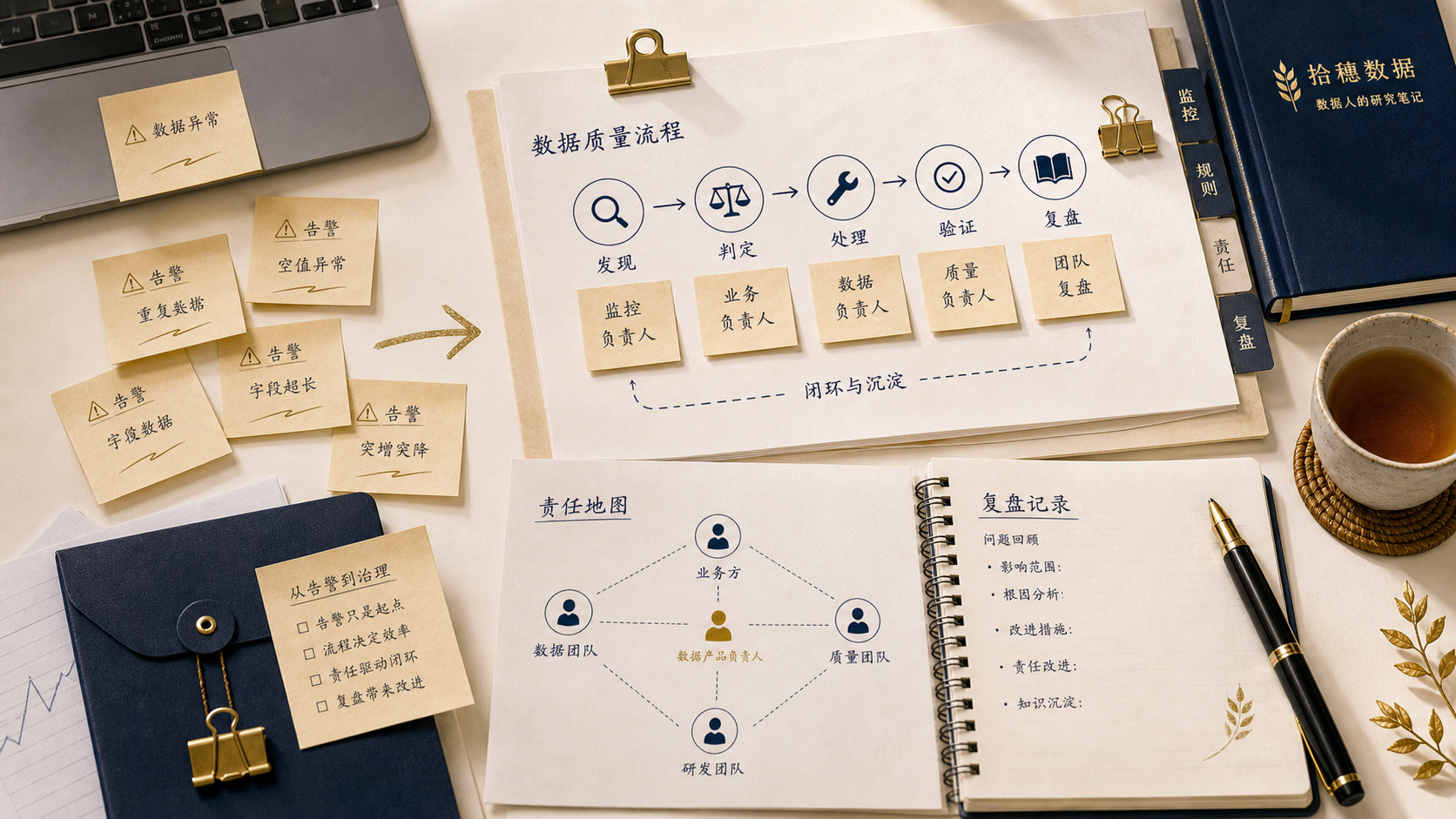
告警响了,不等于问题被管理了
数据团队复盘事故时,最常见的第一句话是:“我们补个告警。”
这句话当然没错。
没有告警,很多问题会等到业务发现。业务发现数据问题,通常已经晚了。数被看过,报表被截图,会议可能已经开完。
可是只补告警,经常不够。
因为告警只能告诉你“这里可能坏了”。它不能自动告诉你:
- 影响了哪些看板?
- 影响了哪些指标?
- 哪些业务已经用了这个数?
- 哪些历史数据需要重算?
- 修复后谁来确认结果可信?
如果这些问题没有答案,告警只会把人叫醒,但不会让团队更稳。
很多事故复盘停在“下次早点发现”。真正应该往前走一步:下次发现以后,我们能不能更快判断影响面、更快决定优先级、更快恢复业务信任。
这才是数据事故复盘的价值。
复盘第一问:这个错数被谁用过
复盘文档里最容易出现一种句子:
“由于上游字段枚举变更,下游过滤逻辑未及时适配,导致订单统计异常。”
这句话准确,但还不够。
它像一份给工程师看的病历。问题是,数据事故不是只发生在代码里,它也发生在业务判断里。
周一复盘时,技术同学很快说清了原因:哪个字段变了,哪段清洗逻辑没有适配,哪批分区需要重跑。
业务负责人听完以后,问的是另一件事:
“那上周五下午的渠道复盘,还算数吗?”
这个问题才真正把事故从“任务失败”拉回“业务影响”。
复盘里应该写清楚:
- 哪些指标受影响?
- 影响时间从几点到几点?
- 影响范围是全量业务,还是某几个渠道、门店、活动?
- 错误方向是偏高、偏低,还是部分缺失?
- 有哪些报表、会议、决策已经使用过错误数据?
这些问题会决定事故的严重程度。
同样是订单数少算 3%,如果发生在测试看板里,影响不大。如果发生在老板周会前 10 分钟,影响就不只是数据问题。
做数据工作,不能只问“任务哪里坏了”。
还要问“这个坏掉的数,被谁拿去做了什么”。
这个问题有时会让人不舒服。
因为它会把事故从技术范围拉到业务范围。技术同学会担心是不是要追责,业务同学会担心是不是要撤回已经发出去的材料,负责人会担心影响被越说越大。
可是事故复盘如果不走到这一步,就很容易变成一次漂亮的技术说明。字段为什么变了,任务为什么没接住,补跑为什么完成了,都说清楚了。唯独没人知道,这个错误数据到底走到了哪里。
不把影响面说清楚,就没法判断通知范围。不判断通知范围,就会出现一种尴尬情况:技术团队觉得已经修完,业务团队却还拿着旧截图继续开会。
复盘第二问:这 48 小时到底改了什么
事故发生后,大家很容易进入救火状态。
谁改了 SQL,谁补跑了任务,谁手动刷了缓存,谁通知了业务,都在群里来回滚动。等到周一复盘,很多细节只剩一句“已修复”。
这不够。因为“已修复”像一个盖章,但它没告诉后来的人,章盖在了哪里。
我见过一种很尴尬的场面:事故刚修完两周,类似问题又出现。新接手的人翻群聊,从凌晨 1 点翻到 3 点,终于找到一句“我先临时改一下过滤条件”。可是他不知道那次临时修改后来有没有回滚,也不知道补跑到底补到哪一天。
救火时靠群聊没问题。复盘时还只靠群聊,就会变成考古。
修复动作至少要留下 4 类记录:
第一,改了什么。
字段、任务、SQL、调度配置、质量规则,都要写清楚。不要只写“修复逻辑”。
第二,补了哪些数据。
补跑的时间范围、任务批次、影响分区、是否有失败重试,都要留痕。
第三,怎么验证。
修完以后不能只看任务成功。要和源表、历史趋势、业务口径做交叉检查。
第四,谁确认。
技术确认和业务确认是两件事。任务跑通不代表业务认可。数据恢复后,最好有明确的确认人。
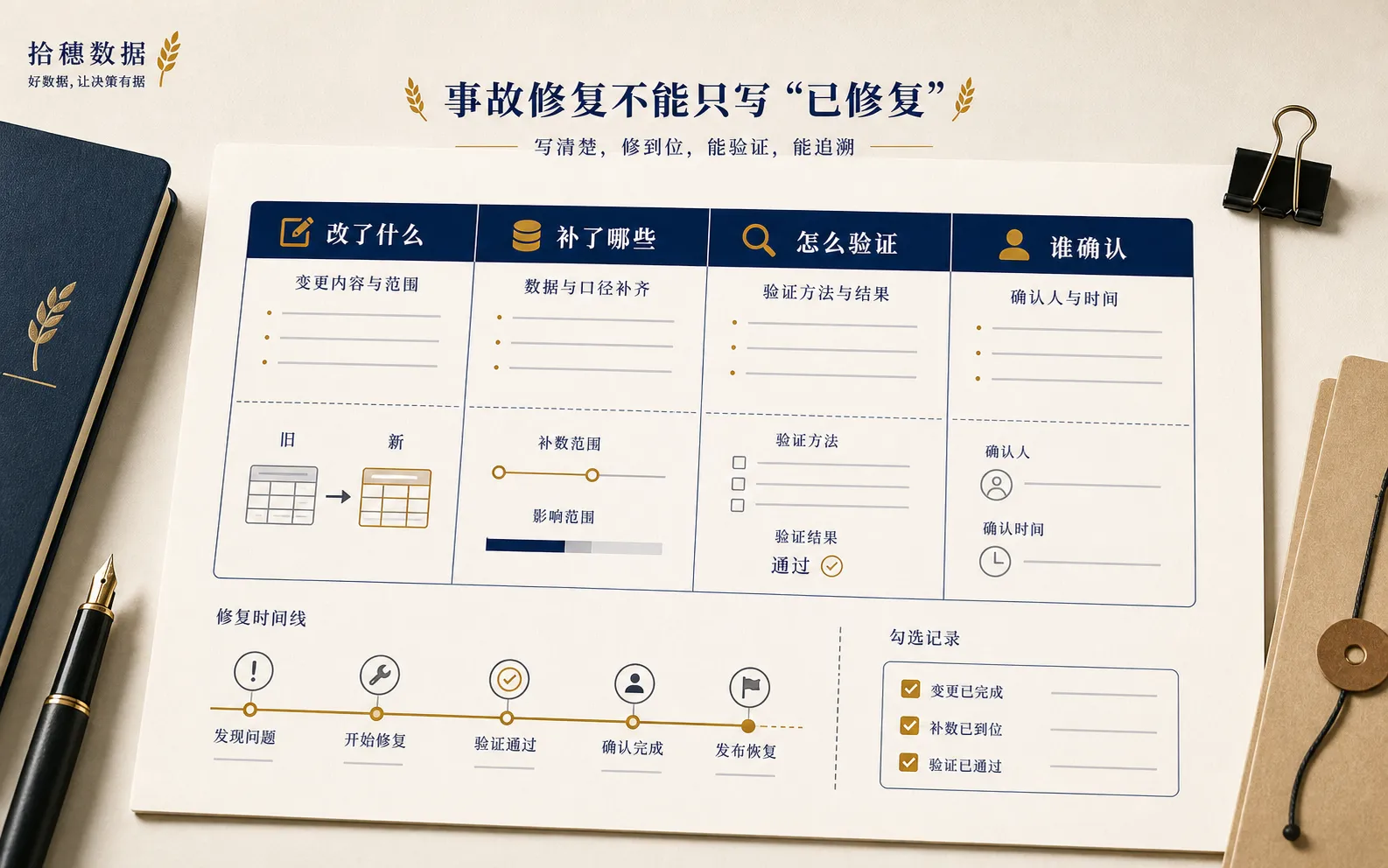
这些记录不是为了追责。
是为了下次有人接手时,不用从聊天记录里考古。
我比较建议复盘里保留一张很朴素的表。
不用写得像审计报告,但至少要有时间、动作、负责人、验证方式和确认人。比如“6 月 14 日 23:10 修改订单状态过滤条件,负责人 A;6 月 15 日 00:30 补跑 6 月 12 日至 14 日分区,负责人 B;6 月 15 日 01:20 与源表订单数、历史趋势和运营复盘表交叉验证,确认人 C”。
这张表的价值不在于好看。
它让后来的人知道,事故不是一句“修好了”就结束,而是经过了哪些具体动作。
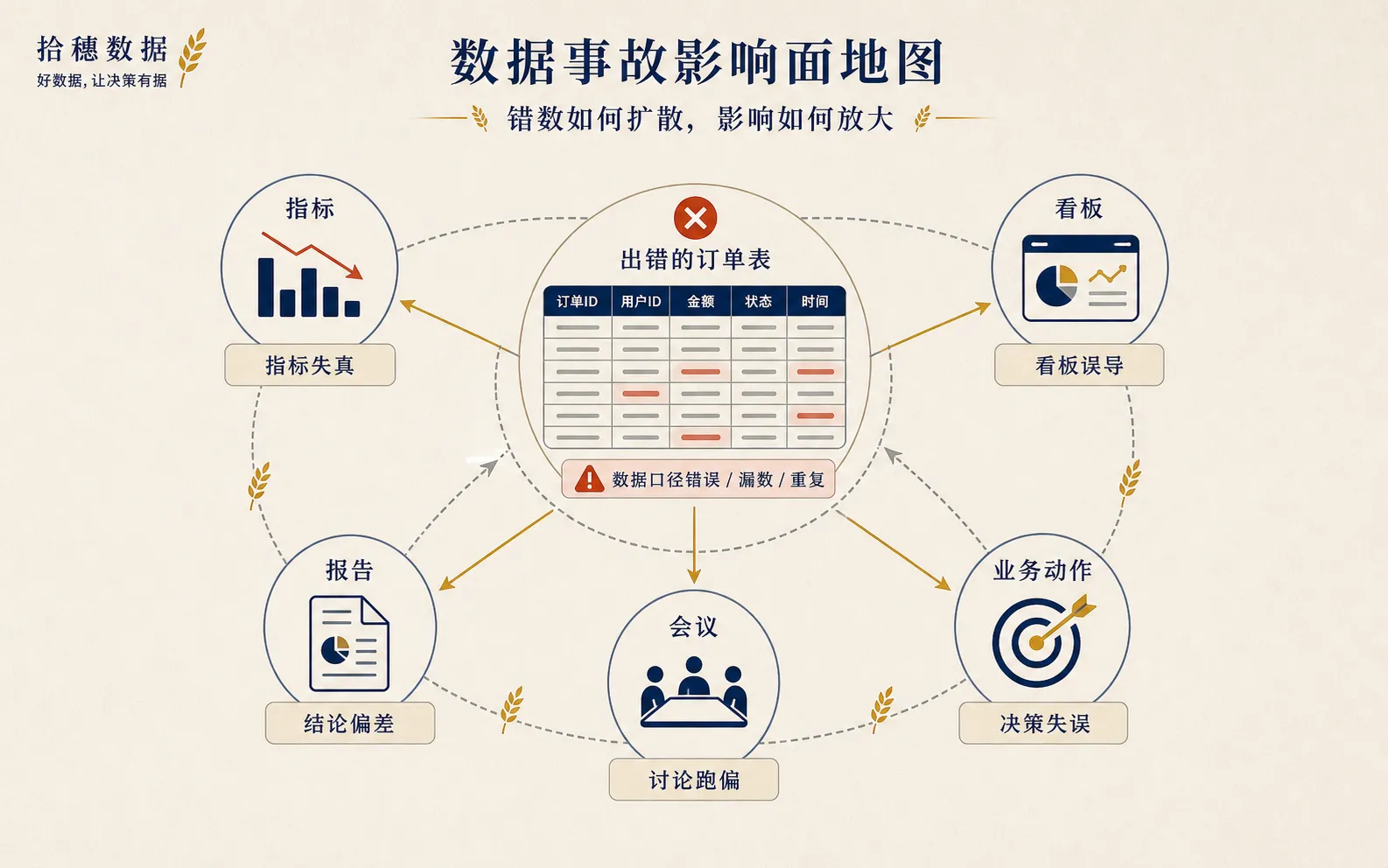
复盘第三问:影响面能不能不靠老同事回忆
很多数据事故一发生,群里会有人问:
“这个表下游还有谁在用?”
如果答案靠某个老同事回忆,就已经危险了。
老同事可能休假,可能转岗,也可能只记得 80%。剩下的 20%,往往就是事故扩散的地方。
所以数据事故复盘里,血缘影响分析不是锦上添花。
它应该回答:
- 这个字段影响哪些表?
- 这些表支撑哪些指标?
- 这些指标出现在什么看板和报告里?
- 有没有外部系统、API、导出文件使用它?
- 哪些下游需要重算,哪些只需要说明?
有了这张影响图,事故处理才不会变成“谁想起来谁补充”。
这也是我后来把“血缘影响分析”和“数据事故复盘”整理进 ss-data-skills 的原因。它不替你查系统,也不假装能自动判责;它只是把事故现场最容易漏掉的那些问题,提前放到你眼前:https://github.com/shisuidata/ss-data-skills
复盘第四问:明天到底补哪一个动作
事故复盘最后一栏,经常写得很客气:
“后续加强测试。”
这句话基本没用。
它太大了,大到没人知道明天要做什么。
更好的写法,是把预防动作拆小:
- 上游枚举变更时,是否需要自动检测新值?
- 核心指标是否需要每日波动检查?
- 关键任务失败后,是否要通知到业务负责人?
- 新字段上线前,是否要跑一组历史样例?
- 高影响表变更时,是否要做下游影响确认?
这些动作不一定一次全做。
但至少要有一个明确负责人、一个完成时间、一个验证方式。
比如这次事故,真正能落下来的动作可能不是“全面加强测试”,而是三件很小的事:
- 上游枚举新增时,每天自动扫一次新值;
- 订单核心指标增加渠道级波动检查;
- 高影响表变更前,先跑一遍下游看板清单。
这三件事不漂亮,也不适合写进年终总结。
但它们能让下一次事故少一截尾巴。

复盘不是写给过去看的。
是写给下一次事故发生前的自己看的。
事故修完,只是回到了起点
很多数据团队很能救火。
任务坏了能修,数据错了能补,报表炸了能恢复。这样的能力当然重要。没有救火能力,生产环境一天都撑不住。
可是如果一个团队只有救火能力,它会越来越累。
因为每次事故都会以不同名字回来。
真正成熟的数据团队,不是没有事故。那不现实。它只是每次事故之后,都把某个隐患从“靠人记着”变成“系统能拦一下、流程能提醒一下、文档能查一下”。
这听起来不刺激。
但数据工程很多时候就是这样。
不是靠一次漂亮的抢修证明自己厉害,而是让下一次半夜的消息少一点。
如果真的少不了,也至少让醒来的人知道该先看哪里。
最后还有一句不太好听的话:事故复盘如果没有人跟进,它就只是一次情绪整理。
会议开完,大家都说“以后注意”,文档写得也很认真。可是一个月以后,新值检测没有做,波动规则没有上线,下游清单还在老同事脑子里。那这次复盘对下一次事故几乎没有帮助。
所以复盘后最好过一周再回看一次。
不需要大张旗鼓,只要把那几条后续动作逐项确认:完成了吗,没完成卡在哪里,是否还值得做,是否需要降级成更小的动作。
很多团队不是不会复盘,是不会让复盘落地。
这一步做完,事故才真的从“故事”变成“系统的改进”。
我叫石头,在数据行业里摸爬滚打了十几年,也在半夜修过不少看起来“不大”的错数。这里写的,就是这些教训——我觉得值得说出来的那部分。