
这周的数据工程新闻,有点像搬办公室。
不是换一张工位,也不是多买几台显示器,而是重新决定:谁有钥匙,谁能进仓库,谁负责把门关上,出了问题又该找谁。
Data Engineering Weekly 在 2026 年 5 月 18 日更新了 #270。我把这一期看完,最明显的主线不是某个新工具突然冒头,而是几家大厂都在解决同一个老问题:数据系统变大以后,真正拖垮团队的不是计算不够快,而是边界不够清楚。
Airbnb 在讲统一数据接口。Netflix 在讲项目级身份。Meta 在讲大规模迁移怎么不把生产弄坏。Databricks 在讲开放表格式和目录治理如何重新合在一起。几件事摊开看,像四张不同的病历,病根却差不多。
下面是本期值得看的几条。
一、Airbnb Viaduct 1.0:Data Mesh 不是口号,是一扇统一的门
Airbnb 发布了 Viaduct 1.0。
Viaduct 是 Airbnb 的数据导向服务网格,一个基于 GraphQL 的系统,目标是给公司内部各种数据源和业务能力提供统一访问接口。它不是传统意义上的“数据平台大一统”,更像是在公司内部修了一扇统一的门:外面的人从这扇门进来,里面各个团队仍然管理自己的房间。
这篇文章里有两个点值得数据团队看。
第一个点是中央 schema。Airbnb 希望整个组织的数据和能力,有一个一致、可发现、可治理的接口。客户端不需要知道后端到底应该调哪个服务,而是通过一个统一图谱来访问跨域能力。
第二个点是去中心化开发。中央 schema 如果只能由一个平台团队维护,很快会变成瓶颈。所以 Viaduct 用多租户运行时承载各团队模块:每个团队定义自己负责的 schema 和 resolver,平台负责执行、扩展、观测和集成。
这就是数据 Mesh 经常被说糊的地方。
很多团队谈 Data Mesh,容易谈成组织架构口号:域团队负责,平台团队支撑,大家自治。听起来很高级,落地时往往变成“每个团队各玩各的”。Airbnb 这套更朴素:统一入口,分散负责。没有统一入口,自治会变成散装;没有分散负责,统一入口会变成中央平台的排队窗口。
国内不少公司做数据平台,最容易卡在这一步。业务线希望快,平台希望稳,最后两边都不满意。Viaduct 给的启发不是“都去上 GraphQL”,而是:数据平台不能只提供工具,还要提供清楚的接口边界。
二、Netflix Data Projects:数据资产不要再挂在人名下面
Netflix 这周写了 Data Projects,用来管理大规模数据资产。
它家的背景很夸张:数据仓库里有数百万张表,调度系统里有数万条定时工作流。这个规模下,两个问题会反复出现。
第一,权限跟不上组织变化。一个团队合并、拆分、换人,就要成批修改表权限。权限维护一累,大家就会倾向于把访问开大一点,最后细粒度 ACL 形同虚设。
第二,工作流绑定在人身上。以前很多调度任务会以某个工程师的身份运行。这个人一换组、离职、权限变化,任务就可能失败。然后团队再临时换成另一个人的身份,新的权限问题又冒出来。Netflix 把这种状态称为权限打地鼠,挺形象的。
Data Projects 的做法,是把管理粒度从“单个资产 / 单个人”提高到“项目”。一个 Data Project 有两层含义:
- 它是相关资产的容器,表、工作流和其他数据资产可以放在同一个逻辑伞下;
- 它也是一个稳定的、可被授权的合成身份,调度任务用项目身份执行,而不是用某个员工身份执行。
更有意思的是 Netflix 提到一个概念:gravity,重力。项目身份创建的新资产,会自动归到这个项目下面。也就是说,组织关系不是靠人手维护出来的,而是顺着执行身份自然长出来。
这对国内团队太现实了。
我们经常把“数据资产管理”理解成目录、标签、血缘、文档。那些都重要。但还有一个更底层的问题:资产到底属于谁?任务到底代表谁在运行?权限到底跟着人走,还是跟着项目走?
很多公司出了数据事故,回头查才发现,关键任务挂在一个已经转岗同事的账号下面,表权限靠微信群里一句“先开一下”维持,责任边界像一团泡过水的毛线。
Netflix 这篇文章提醒我们:数据治理不是先买一个目录产品,而是先把“身份”这件事想清楚。
三、Meta 迁移数据摄取系统:真正的大迁移,先学会影子跑
Meta 分享了他们在超大规模下迁移数据摄取系统的经验。
这套系统每天会把数 PB 级社交图谱数据从 MySQL 增量摄取到数据仓库,供分析、报表、机器学习训练和产品开发使用。旧系统在更严格的数据到达时间要求下开始不稳定,于是他们做了一次完整迁移,并且已经把 100% 工作负载切到新架构。
这类文章最容易被看成“大厂炫肌肉”。但我更关心它的迁移方法。
Meta 没有把迁移理解成“新系统写好了,找个窗口切过去”。他们先定义了清楚的迁移生命周期,每个任务只有满足几个条件,才能进入下一阶段:
- 新旧系统产出的数据没有质量差异,要比对行数和 checksum;
- 新系统的数据到达延迟不能退化,至少要和旧系统持平;
- 计算和存储资源使用不能变差,至少要可比;
- 关键表还要和依赖团队约定额外验收标准。
其中最关键的是 shadow phase,影子阶段。新系统先消费同样的生产源数据,但把结果写到隔离的 shadow table。团队持续监控行数和 checksum 差异,发现不一致就修,修完再验证。
这个方法听起来不新鲜,可是很少有团队真的做扎实。
很多国内数据平台迁移,最怕两种极端:一种是无限期双跑,跑到大家都忘了为什么迁;另一种是拍脑袋切换,出了问题再熬夜回滚。Meta 这篇的价值在于,它把迁移拆成可验证的门槛,而不是靠负责人经验和群里一句“应该没问题”。
对个人来说,这也是项目经历里很值得写的一类能力。简历里写“参与数据平台迁移”,分量不大;写清楚“设计新旧链路 shadow 对账,按行数、checksum、延迟和资源指标分阶段放量”,这才像真正做过生产系统。
四、Databricks Catalog Commits:开放表格式又回到了目录
Databricks 这周写 Catalog Commits 已经 GA。
这件事表面看是 Delta Lake 和 Unity Catalog 的技术更新,往下看,其实是湖仓架构走到一定阶段后的补课。
过去几年,开放表格式很火。Delta、Iceberg、Hudi 解决了对象存储上表的事务、元数据和演进问题。可是系统一多,又冒出新问题:计算引擎直接写存储层,目录不知道;不同引擎从不同路径访问数据,权限和审计不统一;多表事务想做一致更新,又绕不开协调层。
Databricks 把这些问题总结为几个典型挑战:split brain,也就是目录元数据和真实表状态分裂;multi-engine access sprawl,也就是多引擎、多 Agent 直接访问存储路径带来的治理扩散;以及多表事务协调困难。
Catalog Commits 的思路,是让 catalog 重新进入读写路径,负责协调表访问并追踪最新表状态。这样不同引擎和 Agent 不再硬编码对象存储路径,而是通过标准目录 API 解析和访问表。
这条新闻放在 2026 年看特别有意思。
AI Agent 开始消费企业数据以后,过去那些“只要工程师知道路径就行”的做法会越来越危险。人类工程师还能凭经验绕一绕权限和路径,Agent 如果拿到一堆静态路径和粗粒度权限,后果就比较难看。
所以目录不再只是数据治理同学看的网页。它正在变成一个运行时控制点:发现、授权、审计、事务协调,都要回到这里。
一句话说,湖仓的下一步不是继续把文件格式做漂亮,而是把“谁能通过什么方式读写这些文件”重新管起来。
五、DuckDB 继续往缝隙里长
这一期还有两条 DuckDB 相关内容。
一条来自阿里云 AliSQL。文章讲的是把 DuckDB 作为存储引擎集成到 MySQL 体系里,让 MySQL 获得轻量级 OLAP 能力,同时保持 MySQL 协议、语法和运维体系兼容。文中提到,DuckDB 分析只读实例使用读写分离架构,通过 binlog 从主库同步数据,分析查询可比 InnoDB 提升最高 200 倍,存储空间通常约为主库的 20%。为了兼容 MySQL,他们还做了约 17 万条 SQL 自动化兼容测试,结果显示兼容率 99%。
另一条是 DuckDB 全文检索扩展。作者用邮件语料演示了 DuckDB 的 FTS 能力,包括安装扩展、创建索引、BM25 打分、调 k₁ 和 b 参数。它还不如 Postgres 或 Elasticsearch 那么完整,比如高亮、同义词等能力还弱,但对探索式文本分析已经够轻便。
这两条放一起看,会发现 DuckDB 的路线很有意思。
它不是只在一个方向上做“大数据库”。它更像一把锋利的小刀,开始钻进各种缝隙:嵌入 MySQL、挂进本地分析、处理临时文本语料、做轻量 OLAP。以前这些场景常常要搬一套沉重系统,现在可能一个扩展、一个只读实例、一个本地文件就能开始。
对数据从业者来说,这不是让你放弃数仓,也不是让你把所有东西塞进 DuckDB。更现实的启发是:很多“小而急”的分析任务,不一定需要上大平台。先用合适的小工具把问题看清楚,再决定要不要工程化,反而更稳。
拾穗解读:数据平台正在从“功能堆叠”回到“责任边界”
把本期几条放在一起,我看到的不是新技术列表,而是一个共同趋势:数据平台正在从功能堆叠,回到责任边界。
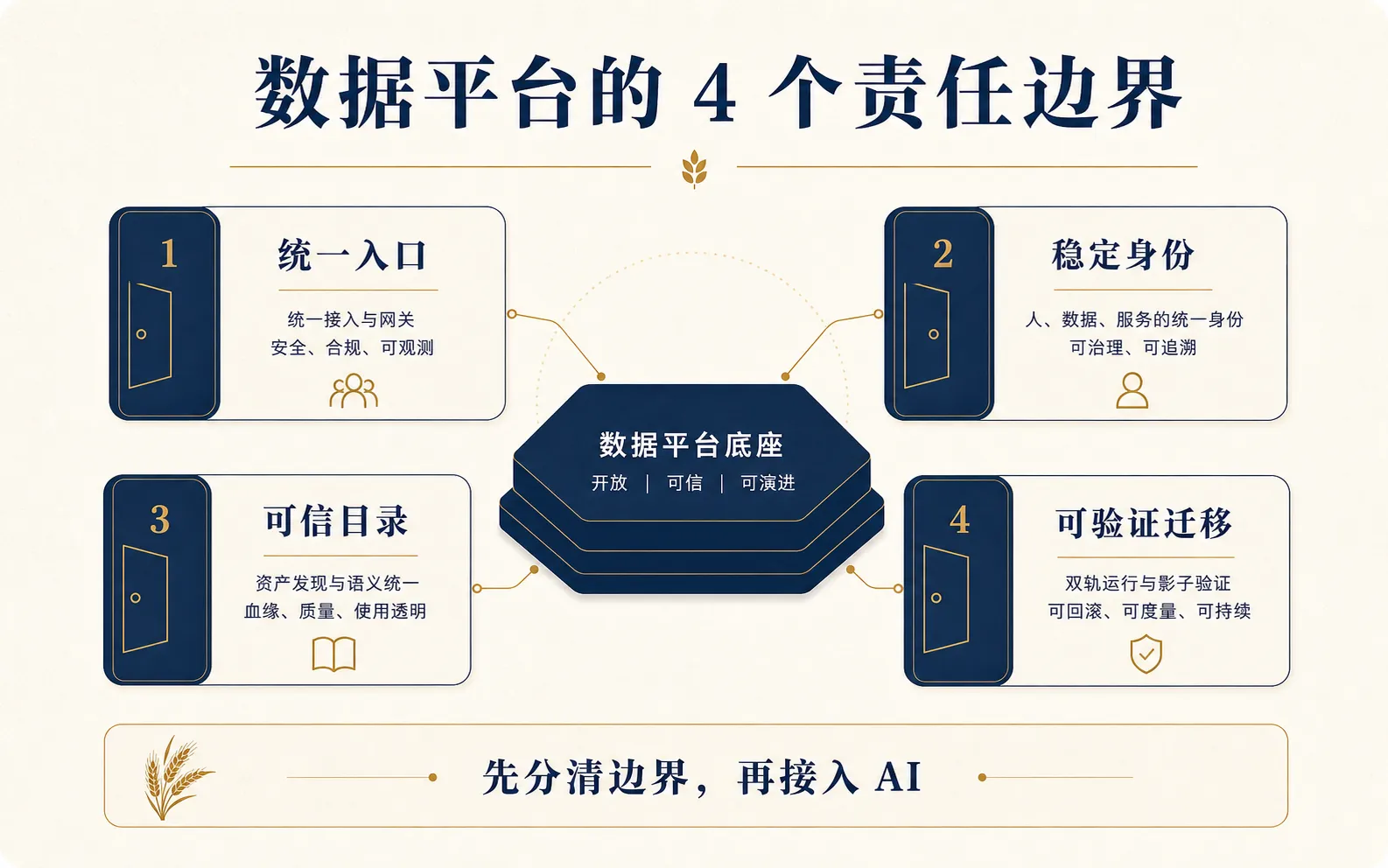
过去几年,数据团队很喜欢讲能力地图:采集、存储、计算、治理、质量、血缘、调度、服务、AI。每一项都能买工具,每一项都能做项目。久而久之,平台像一间越堆越满的杂物房,什么都有,但找东西越来越慢。
这周几篇文章都在做相反的事。
Airbnb 问的是:统一接口在哪里?
Netflix 问的是:项目身份是谁?
Meta 问的是:迁移进入下一阶段的验收门槛是什么?
Databricks 问的是:多引擎和 Agent 到底通过谁访问表?
AliSQL + DuckDB 问的是:能不能在不推翻原有系统的情况下,把分析能力嵌进去?
这些问题都不炫。甚至有点像办公室行政工作:门禁、工牌、资产登记、验收单、值班表。可是大系统真正能跑稳,靠的就是这些不炫的东西。
AI 进入数据团队之后,这种边界感会变得更重要。
因为 AI Agent 会放大系统里原本模糊的地方。权限边界不清,它会放大权限问题;接口不清,它会乱找入口;目录不可信,它会基于错误上下文做判断;迁移没有验收门槛,它会把不确定性包装成很自信的说明。
所以这期周刊给我的提醒是:别急着给数据平台再加一个 AI 助手,先看看你的平台有没有清楚的门、稳定的身份、可信的目录和可验证的迁移流程。
这对个人成长也一样。
如果你是数据开发,不妨在下一个项目里多想一层:这个任务现在挂在谁的身份下?出问题谁负责?换人以后会不会断?
如果你是数据分析师,也可以多问一句:我现在调用的数据入口是稳定接口,还是某个同事告诉我的临时路径?这个指标背后的口径和权限,是否能被后人看懂?
很多时候,所谓高级能力,不是会更多工具,而是能把混乱的系统讲清楚、分清楚、稳住。

如果你想系统补齐数据工程、数据治理、AI 数据底座这些能力,我也会继续把这类案例整理进 数据从业者全栈知识库。周刊负责帮你看见风向,知识库负责把能长期复用的东西沉下来。
本周其他值得看
- Eric Sun:A Query Proxy for Analytical and Fast Data。用 gRPC、Arrow/Parquet 和服务凭证,把 Snowflake、Databricks、StarRocks、Iceberg 等分析引擎包装成统一查询代理,适合关注“分析能力如何服务化”的同学。
- Faire:重建搜索排序。Faire 用 Deep & Cross Network 替换 XGBoost,并通过多任务表示缩短新场景上线周期。对做推荐、搜索、广告特征工程的人有参考价值。
- Marc Bowes:Aurora DSQL Coupler。讲 Aurora DSQL 的 CDC 设计,利用低延迟 journal fan-out 让 Coupler 作为订阅者工作,避免传统 CDC 对数据库造成太大压力。
- DuckDB FTS。如果你平时会临时分析一批邮件、文档、工单,DuckDB 的全文检索扩展值得放进工具箱。
我叫石头,在数据行业里摸爬滚打了十几年,踩过的坑,比写过的文档多。这里写的,就是这些教训——我觉得值得说出来的那部分。
来源
- Data Engineering Weekly #270 · Ananth Packkildurai · 2026-05-18
- Airbnb Engineering:Viaduct 1.0 and the future of Airbnb’s data mesh · 2026-05-13
- Netflix TechBlog:Data Projects: Managing Data Assets at Netflix Scale · 2026-05-11
- Meta Engineering:Migrating Data Ingestion Systems at Meta Scale · 2026-05-12
- Databricks:The Convergence of Open Table Formats and Open Catalogs
- Alibaba Cloud:When MySQL Meets the Columnar Storage Engine DuckDB in the AI Era · 2026-05-13
- Pete Doherty:Full-Text Search with DuckDB · 2026-04-29
《数据周刊》每周更新一期,挑数据行业值得看的动态,附拾穗的判断。拾穗数据|https://ss-data.cc


