
这周的数据工程新闻,有一个共同味道:大家都在给“混乱”装仪表盘。
AI 第二大脑也好,多 Agent 数据流程也好,模型生命周期图谱也好,自愈数据管道也好,表面上都很新。往下看,其实还是老问题:知识散落、流程太长、模型没人管、管道变慢却没人发现。
Data Engineering Weekly 在 2026 年 5 月 11 日更新了 #269。我把这一期和几个辅源看了一遍,挑出几条对国内数据从业者最有启发的内容。
这期不想写成工具清单。
我更想讨论一个问题:当 AI 开始进入数据团队,真正值钱的能力,可能不是“多接一个模型”,而是把那些过去靠人记、靠群聊问、靠经验猜的东西,沉淀成可观测、可复用、可追责的系统。

一、Meta 的 AI 第二大脑:知识管理终于被逼到台前
Meta Analytics 团队分享了一篇文章:他们为 6 万名知识工作者搭建 AI Second Brain。
这个题目很容易被理解成“企业内部知识库 + 聊天机器人”。但如果只这么看,就太浅了。
大公司真正的问题,不是没有文档,而是文档、数据、指标、项目经验、历史讨论散落在太多地方。一个新人想弄明白某个指标为什么这样定义,可能要翻 wiki、找仪表盘、问老同事、查群聊记录,最后还不一定得到确定答案。
AI 第二大脑的价值,不只是帮人搜索。
它是在尝试把组织里的隐性知识变成可调用的上下文。
这对数据团队很关键。因为很多数据问题本来就不是 SQL 问题,而是上下文问题:这个指标过去改过几次?为什么不用另一个口径?这个看板谁在看?某个异常上次怎么处理?
如果这些东西永远靠老员工记在脑子里,团队就会越来越脆弱。
AI 进入数据团队以后,第一批真正有用的场景,可能不是自动写一切,而是让团队少问几遍“这个东西以前是谁做的”。
二、Salesforce / Informatica:数据工作流不是一个 Agent 能做完
Salesforce Engineering 写了 Informatica 如何构建多 Agent AI 系统,把一些数据工作流从数月缩短到数天。
这类标题容易让人兴奋,也容易让人误解。
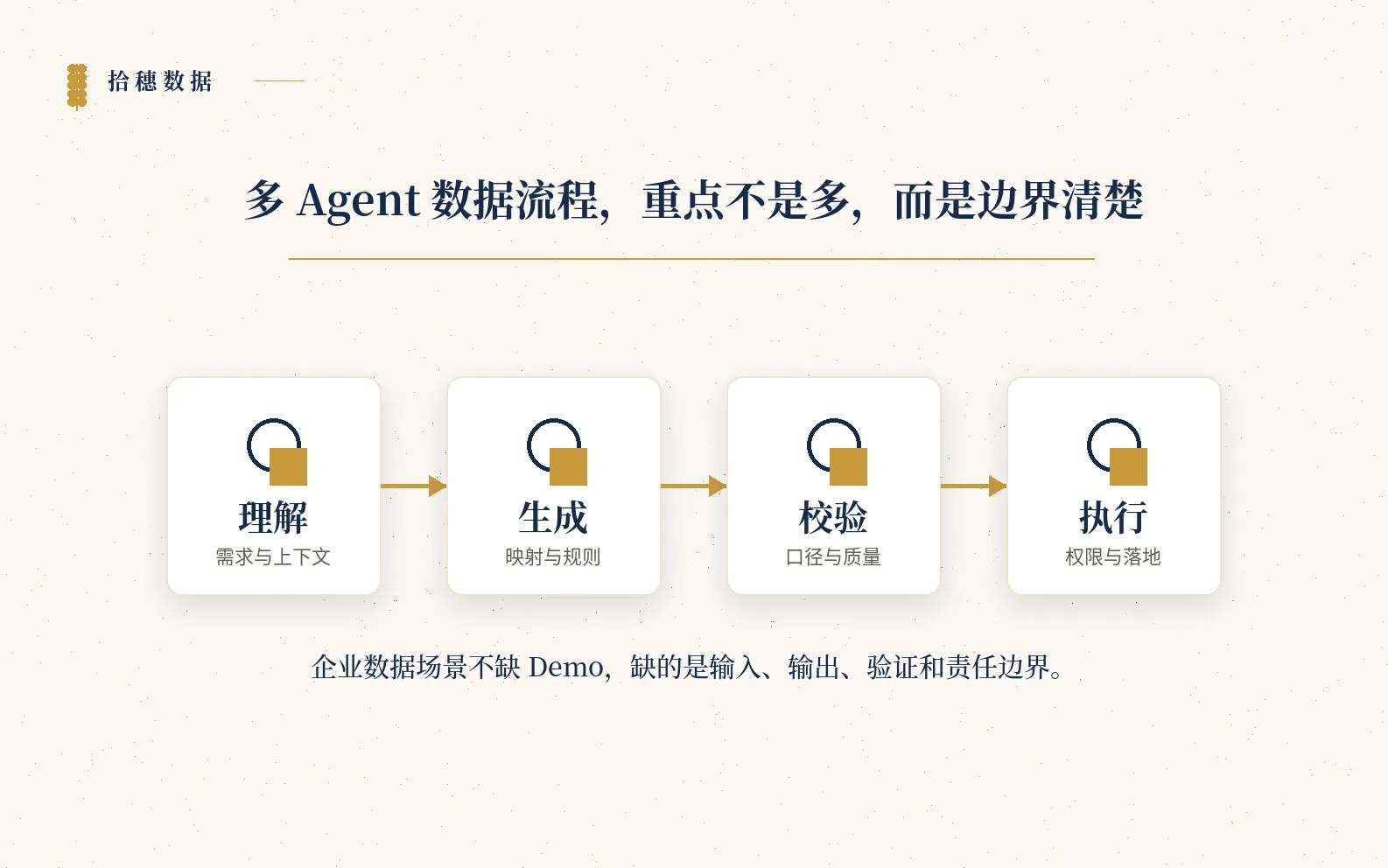
我不建议把它读成“一个 Agent 替代整个数据团队”。更准确的理解是:复杂数据流程本来就不是一个角色能完成的。需求理解、字段映射、规则生成、验证、审批、执行,每一步都需要不同上下文和不同约束。
所以,多 Agent 的重点不是“数量多”。
而是边界清楚。
一个 Agent 负责理解,一个 Agent 负责生成,一个 Agent 负责校验,一个 Agent 负责执行。它们之间如果没有明确输入输出,最后只会变成一群很热闹的自动化脚本。
这对国内团队也有提醒。
很多公司现在试 AI 数据助手,容易一上来做一个“万能助手”:能取数、能分析、能写报告、能改 SQL、能解释指标。听起来很好,落地时却经常卡在权限、口径、验证和责任上。
企业数据场景不缺 Demo。
缺的是能把边界讲清楚的流程设计。
三、Netflix 的模型生命周期图谱:模型也需要“户口本”
Netflix Tech Blog 写了 Model Lifecycle Graph,用来民主化机器学习。
这个方向很值得数据工程同学看。
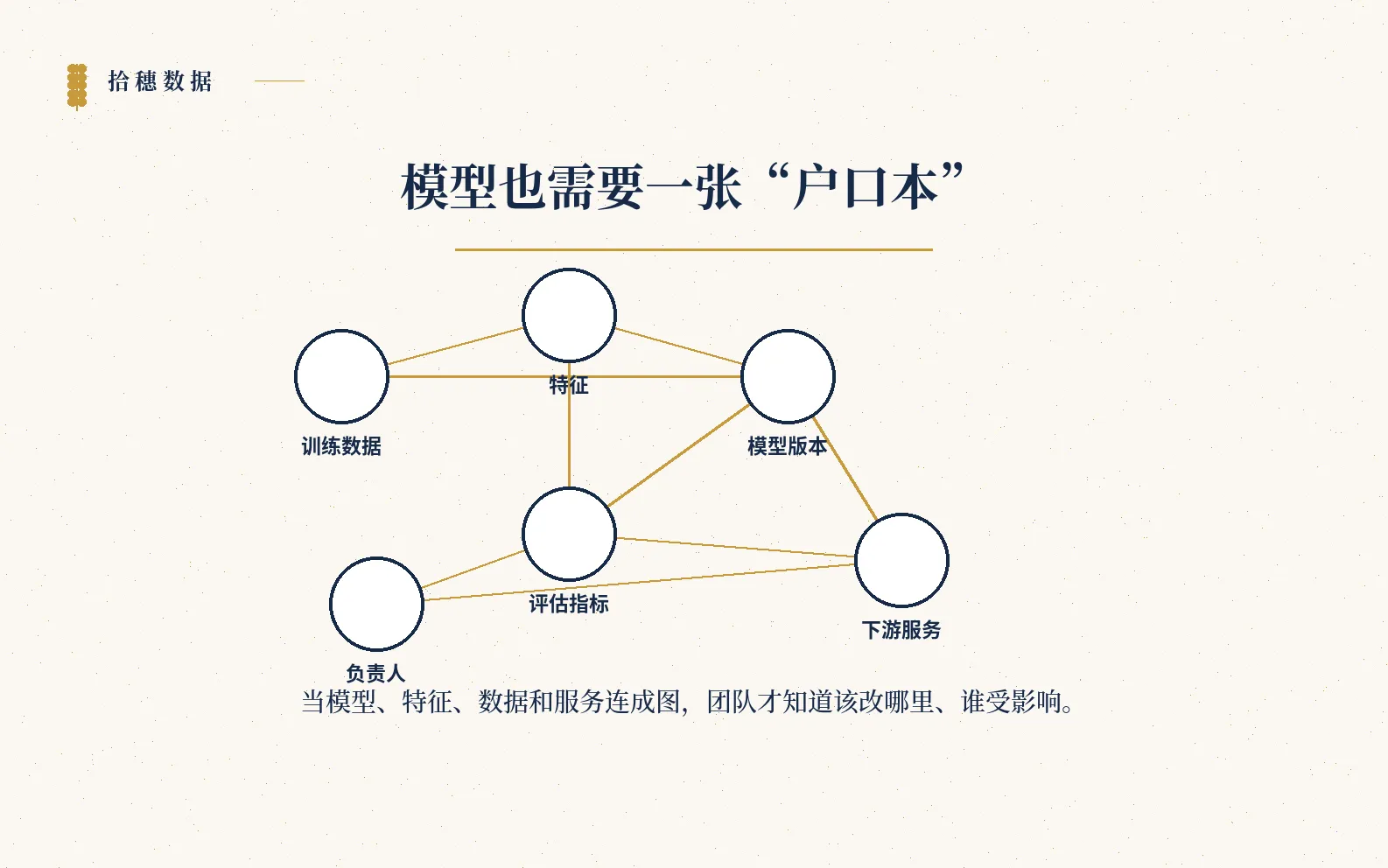
模型上线以后,并不是一个孤零零的文件。它有训练数据、特征、评估指标、实验记录、部署版本、下游服务、监控告警。时间一长,如果没有一张图把这些关系串起来,团队就很难回答几个基本问题:这个模型从哪来?用了哪些数据?影响哪些业务?现在谁负责?
这和数据血缘很像。
以前我们关心表和字段的血缘:这张表来自哪里,影响哪些报表。现在,机器学习和 AI 应用越来越多以后,模型、特征、提示词、评估集也需要类似的生命周期管理。
否则模型多起来之后,组织里会出现一种新的混乱:没人敢删,没人敢改,没人知道哪个版本还在被用。
Netflix 做模型生命周期图谱,本质上是在给模型建一套“户口本”。
这事不花哨,但很实用。
国内很多团队如果正在做 AI 应用,也迟早会遇到类似问题。今天你觉得只有几个模型和几个 prompt,用表格记一下就行。等业务线都开始接入,版本、数据和评估关系会很快长成一团毛线。
四、Whatnot:管道没有挂,不代表它没有坏
Whatnot Engineering 的文章标题很有意思:The ML Feature Pipeline That Got Slower and No One Noticed。
一个 ML 特征管道变慢了,但没人发现。
这句话特别适合数据团队反思。
我们平时很重视“任务失败”。失败会报警,会进群,会有人处理。可是很多问题不是失败,而是变慢、变贵、变不稳定、质量一点点下降。
这些问题更隐蔽。
它们不会让系统立刻停摆,却会慢慢吃掉团队时间和业务信任。今天延迟多 10 分钟,明天特征晚到一点,后天推荐效果波动,最后大家只觉得“最近系统有点不对劲”。
Whatnot 这个案例提醒我们:数据管道的健康,不应该只看成功或失败。
还要看延迟、吞吐、成本、质量、下游影响,以及这些指标有没有被人真正看见。
这对求职和个人成长也有关系。
如果你能在项目里讲清楚“我不只是把任务跑通,还建立了管道健康指标,让变慢、变贵、变脆的问题提前暴露”,这比单纯写“负责调度任务维护”更有分量。

五、Flink、实时 OLAP 和自愈管道:实时系统也在补课
这一期还有几条实时和管道治理相关内容。
Confluent 写了 Flink、ClickHouse、Pinot 的边界比较,讨论 stream processing 和 real-time OLAP 的差异。这个话题对国内团队很实用。很多架构争论,本质上是把“处理流”与“查询实时结果”混在了一起。Flink 适合持续处理事件流,ClickHouse / Pinot 更偏实时分析查询。它们不是谁取代谁,而是承担不同环节。
Grab 写了 Flink shadow testing,用影子测试降低生产上线风险。这也很现实。实时任务最怕直接在生产里试错,一旦影响下游,回滚和排查都很难。影子测试的思路,是让新逻辑先在不影响生产结果的情况下跑起来,对比输出,再决定是否切换。
Halodoc 写了 self-healing data pipelines。自愈管道听起来像一个很大的词,但背后常常是一些具体动作:自动识别 CDC 问题、自动恢复、减少人工介入、把常见故障处理流程固化下来。
这些内容合在一起看,会发现实时系统也在补课。
过去几年,大家追求更实时。现在,大家开始追求更稳、更可测、更可恢复。
这是一种成熟。
拾穗解读:AI 时代,数据团队的底座会重新变重要
很多人谈 AI,会把注意力放在模型能力上。
模型当然重要。但对数据团队来说,更大的变化可能在底座。
Meta 的 AI 第二大脑,需要组织知识底座。
Informatica 的多 Agent 流程,需要清楚的流程和权限底座。
Netflix 的模型图谱,需要元数据和血缘底座。
Whatnot 的管道观测,需要监控和指标底座。
Flink shadow testing 和 self-healing pipelines,需要测试、恢复和责任边界底座。
这些东西听起来没有“新模型发布”热闹。
但它们决定 AI 能不能进生产。
一个数据团队如果连指标口径、任务延迟、模型版本、特征来源都说不清楚,就算接了再强的模型,也只是在混乱上面加了一层更会说话的混乱。
所以,这期周刊给我的提醒是:AI 时代的数据工程,不是从底层走向边缘,而是底层重新变得重要。
对个人也是一样。
如果你正在做数据开发,不要只问自己会不会某个新工具。可以多问一句:我能不能让一条链路更可观测、更可恢复、更容易被别人接手?
如果你正在做数据分析,不要只问自己会不会用 AI 写报告。可以多问一句:我能不能把一个指标的上下文、口径变化和业务使用场景讲清楚?
这些能力不一定闪亮。
但很耐用。
本周其他值得看
- Pinterest 写了把实时上下文接入序列推荐模型,适合关注推荐和广告的同学。
- Luminousmen 写了 data sketches 的综述,适合补概率数据结构和近似计算基础。
- Seattle Data Guy 在 5 月 14 日写了现在带数据团队到底像什么,里面关于 AI 热潮下团队现实处境的观察,可以作为管理视角补充。
- dbt Roundup 5 月 10 日的文章《The computers talk to us now》也值得看,主题是计算机开始用自然语言和我们对话以后,分析工程会发生什么变化。
如果你最近也在准备数据岗位求职,可以把本期内容当成一个提示:别只写“维护数据管道”“参与模型上线”“负责报表开发”。试着写清楚,你让什么东西变得更可信、更可观测、更可复用。
这比多背一个工具名更接近未来的岗位要求。
我叫石头,在数据行业里摸爬滚打了十几年,数字背后的逻辑,比数字本身更值得看。这里写的,就是这些教训——我觉得值得说出来的那部分。
来源
- Data Engineering Weekly #269 · Ananth Packkildurai · 2026-05-11
- Meta Analytics: How we built an AI second brain for 60K knowledge workers
- Salesforce Engineering: How Informatica built a multi-agent AI system
- Netflix TechBlog: Building the Model Lifecycle Graph
- Whatnot Engineering: The ML Feature Pipeline That Got Slower and No One Noticed
- Confluent: Stream Processing vs. Real-Time OLAP
- Grab Engineering: Enhancing Flink Shadow Testing
- Halodoc: Building Self-Healing Data Pipelines


