
本期三件事:Shopify 用 JSON-to-Python 转译把 Flow Agent 的推理成本降了 68%;Monzo 用数据契约把处理成本降了 40%、数据着陆时间加速 25%;Halodoc 把 Spark on EKS 的节点利用率拉到 96%,EC2 成本顺手降了 10%。一个共同的趋势——Agent 和数据基建落地,走完了”做小”和”稳定”两步,正式进入第三步:算账。
前两周我们聊过 Agent 要做小、做小之后怎么稳定跑生产。这周看到的几篇复盘,主线又往前走了一格——怎么把这些已经在跑的东西做得更便宜、更可持续。
每条都带具体的成本数字。这是个好信号——意味着行业过了”先跑通再说”的阶段,开始进到”跑通了,但能不能更便宜”。下面看几个具体案例。
行业动态
Shopify:Flow Agent 推理成本降 68%
Shopify 工程团队发了一篇关于他们 Flow(自动化工作流)产品里 AI Agent 的复盘——核心问题很具体:让 LLM 直接生成复杂的工作流 JSON 时,模型总是在 schema 边界上犯错,要么字段写错、要么嵌套层级搞混。
他们的解法不是换更大的模型,而是加了一层 JSON-to-Python 的转译器——让 LLM 用 Python 这种它更熟悉的语法表达逻辑,再把 Python 翻译回 JSON。Python 有更多的训练数据、更友好的语法、更好的错误信号。结果——同等准确率下,推理成本降了 68%。
这背后是一个简单但容易被忽略的判断:LLM 不擅长写人类设计的格式(JSON / YAML / DSL),擅长写它在训练数据里见过最多的格式(Python)。让模型用它最舒服的方式表达,比逼它用你的格式硬写更省钱。
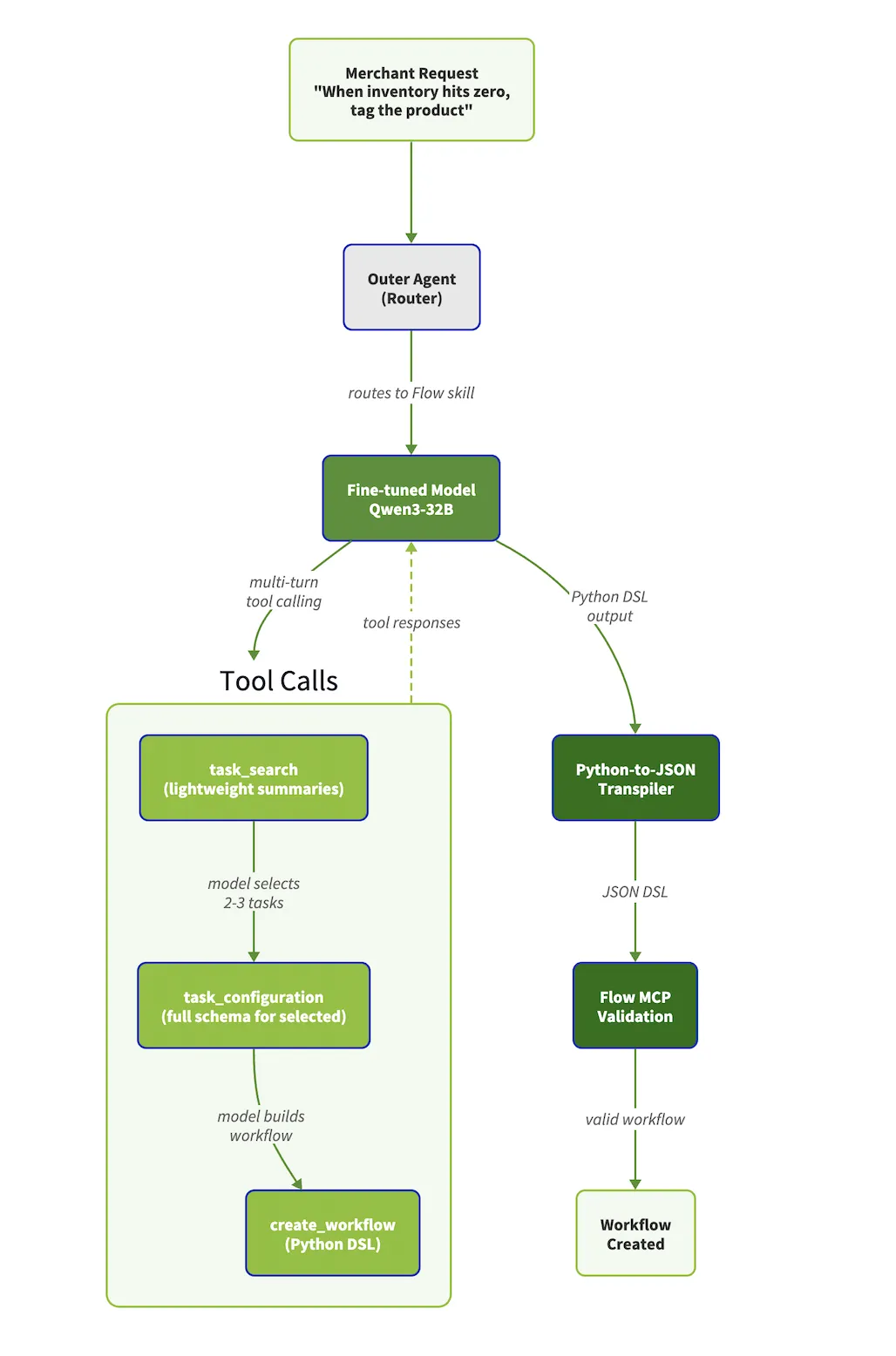
原文:Fine-Tuning an Agent to Generate Shopify Flow · Shopify Engineering
Monzo:数据契约让处理成本降 40%
英国数字银行 Monzo 写了他们这一年怎么做”meshy approach”——一个介于完全集中式数仓和纯分布式数据网格之间的中间形态。
核心做法:在生产服务和数据消费方之间,显式定义数据契约(schema、口径、SLA),上游变更必须先过契约审查。这套做下来,处理成本降了 40%,数据从产生到可用的延迟(着陆时间)缩短了 25%。
听起来像是流程问题,本质上是架构问题。过去金融业的数据治理依赖事后清洗——业务系统乱改字段,数据团队拼命兜底;现在反过来——上游必须遵守契约,下游不再当救火队员。
这是数据治理从”被动应对”转向”主动约束”的典型案例。
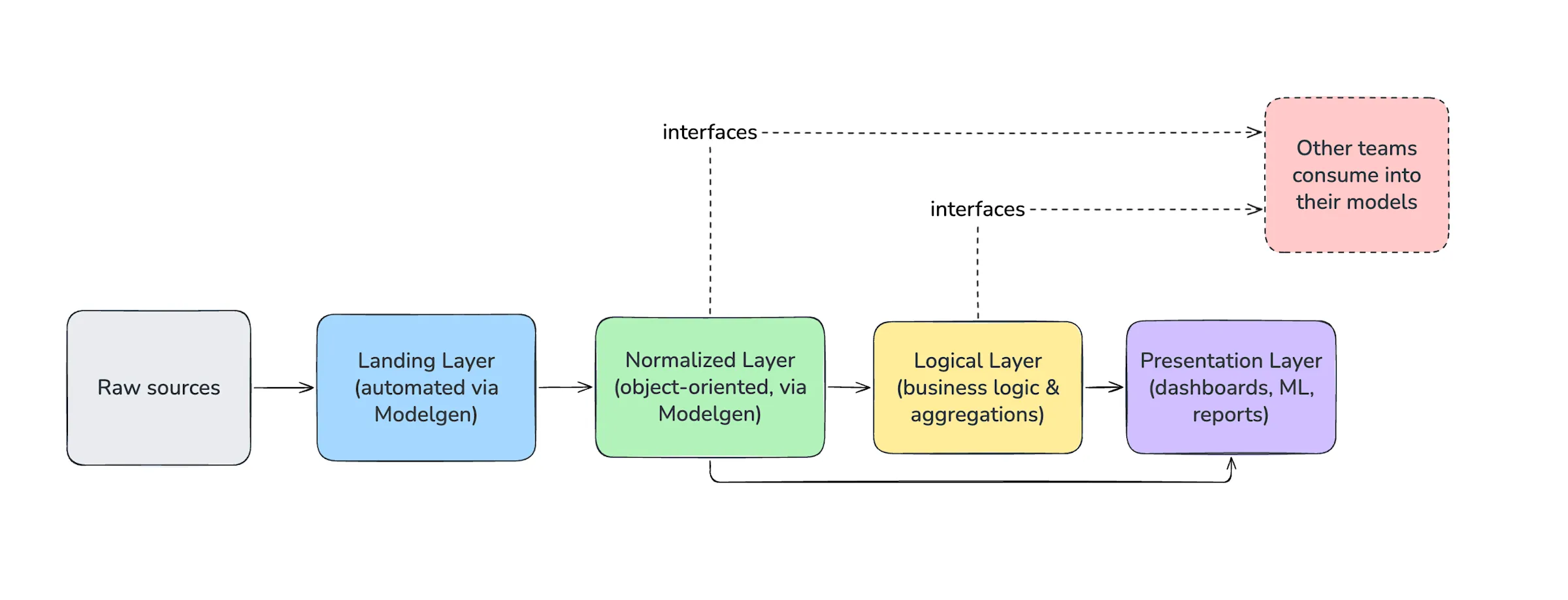
原文:A “meshy” approach to data · Monzo
Halodoc:YuniKorn 让 EKS 节点利用率到 96%
印尼医疗科技公司 Halodoc 在 EMR on EKS 上跑 Spark,一直被一个常见问题困扰——容器调度过于保守,导致节点平均利用率只有 60% 左右。剩下的 40% 是计费的,但没在干活。
他们引入了 Apache YuniKorn 作为调度器,把”装箱算法”用起来——同一个节点上塞更多 Pod,挤掉碎片资源。结果——节点利用率到了 96%,EC2 成本降了 10%,Spot 实例采用率也提升了。
利用率从 60% 到 96% 这一步,没换硬件、没换 Spark 版本,只换了个调度器。这种基础设施层的”无痛降本”,是国内大量数据团队应该看一眼的——你账单的 30%-40% 可能就是这种空转。
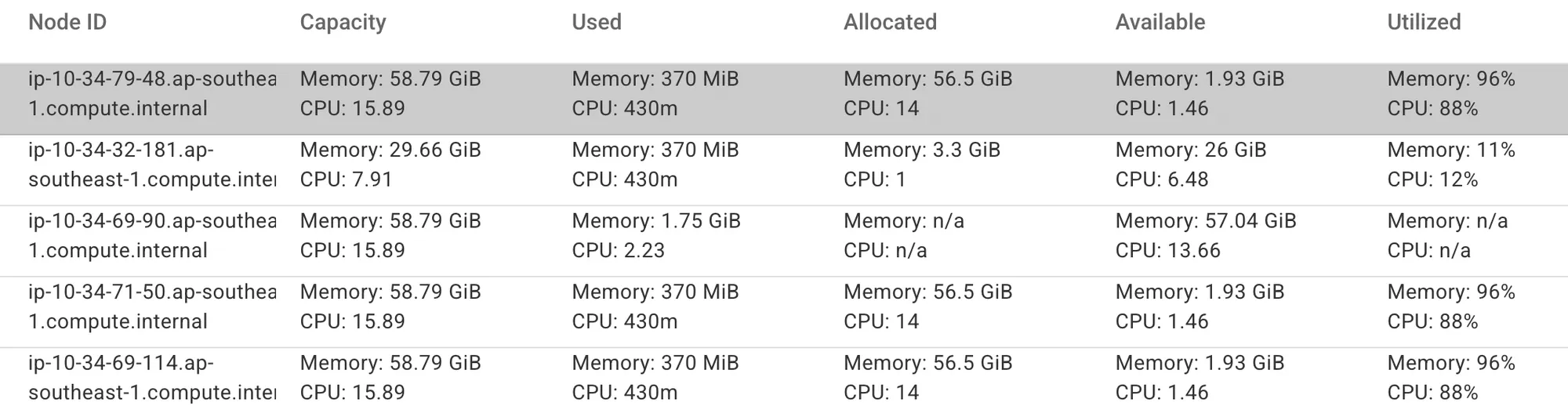
原文:Implementing Apache YuniKorn on EMR on EKS at Halodoc · Halodoc Blogs
观点看点
Microsoft:当数据分析”学会推理”
微软数据科学团队的一位工程师 Pratish Yadava 写了一篇观点文章,论点很简单——传统数据分析交付的是”被动报告”,未来交付的是”主动推理”。
被动报告:每周一份 PPT,给人看。Dashboard 数字摆在那儿,要不要看你自己决定。
主动推理:一个持续运行的 Agent,监测业务数据 → 发现异常 → 定位原因 → 提出建议 → 推送给决策者。Agent 不是替代分析师,是替代分析师的”等人来问”那部分时间。
这篇没有数字,是一个值得想一想的方向预测。它和我们前面讲的 Shopify/Monzo/Halodoc 是同一组思考的不同侧面——都是关于”数据/AI 系统从被动到主动的转变”。
原文:Data Agents - When Enterprise Analytics Learns to Reason · Pratish Yadava @ Microsoft
拾穗解读:Agent 落地的第三阶段——开始算账
把前面三条放一起看,会发现一个共同特征——它们都不是关于”AI 能不能做”的问题,是关于”AI 做得便不便宜”的问题。
这是 Agent 在企业里落地的第三阶段。
第一阶段是”能不能跑”——2023 年前后整个行业都在做这事,把 LLM 接进自己的产品里,证明它能干活。这个阶段的产出是大量的 Demo 和 PoC。
第二阶段是”能不能稳定跑”——2024 到 2025 年的主线。我们上一期周刊讲的 Whatnot、Slack、Teads 都属于这一阶段——他们解决的是基础设施层的可靠性问题,故障率、上下文管理、长跑稳定性。
第三阶段就是这一周看到的——“能不能便宜跑”。Shopify 把推理成本降 68%、Monzo 把处理成本降 40%、Halodoc 把节点利用率拉到 96%——这些数字背后是同一个判断:AI 系统已经过了”是不是噱头”的争论,进入了”账本能不能算清楚”的实用主义阶段。
这件事对数据从业者个人意味着什么?
我自己最近想清楚一件事——第三阶段对个人能力的要求和前两阶段完全不同。
第一阶段需要的是”对新技术的好奇心”——你愿不愿意学 LangChain、RAG、Prompt 工程,是不是早入场。第二阶段需要的是”工程能力”——你能不能把 Demo 推到生产、能不能搭可观测的系统。第三阶段需要的是”成本意识”——你能不能给一个 AI 系统算清楚账,包括 token 成本、推理延迟、人工干预成本、维护成本。
这第三种能力,恰好是绝大多数技术人最薄弱的。我们习惯讨论”做不做得到”,但对”做得起做不起”想得不深。接下来一年市场会重新分配溢价——不是给”会用 AI”的人,而是给”能让 AI 在合理预算内跑起来”的人。
Shopify 那个 JSON-to-Python 的转译思路特别值得琢磨。这是个很”工程师味儿”的解法——不去找更强的模型,而是顺着模型的训练数据分布走,让模型用它擅长的东西表达。这种思路在国内数据团队里还很少见,国内更习惯的做法是”换个更新的模型”或”加一轮 RLHF”——但那都是更贵的解法。
Monzo 那篇我觉得对国内金融业有直接借鉴价值。数据契约不是个新概念,但能在生产环境真实推行的公司不多——大多数公司停留在 wiki 上写文档、靠人盯。Monzo 把契约审查嵌进了上游服务的发布流程,这是治理能落地的关键。
Halodoc 那篇技术上不复杂,但意义在于”基础设施层的无痛降本”是被严重低估的。国内很多数据团队的成本焦虑很重,但解法多停留在”砍业务”层面——其实先把现有基础设施挖一遍,往往能省一大笔。一个 Spark 集群的利用率从 60% 到 96%,相当于免费多了 60% 的算力。
如果让我给这一期做一句话的收束:Agent 落地的下一个 18 个月,比拼的不是模型谁更强,是谁能算清账。
说到这里我自己一直在琢磨——国内数据团队里”懂业务 + 懂工程 + 懂账本”的人,到底有多稀缺? 这种复合能力本来在企业里就少,AI 时代变得更稀缺。这是我最近在梳理的一个题目,有想法的朋友可以加我微信(shisuidata)一起聊。
本周其他值得看的
- Smarter URL Normalization at Scale:Pinterest 的 MIQPS 算法,通过实证渲染分离内容信号与噪声,做大规模 URL 去重
- Scaling Camera File Processing at Netflix:Netflix 在摄像头素材采集端做自适应处理,无需 GPU 基础设施
- Doing More With Less: Entity-Level Sentiment at Scale:Meltwater 用单次 Transformer 前向传递提取多实体嵌入,推理成本降 45.5%
- Airflow DAG Bundles: Managing DAGs Without Helm Upgrades:S3 后台同步实现 DAG 热重载,30 秒内完成新管道部署
- Context Management in Agent Harnesses:Aparna Dhinakaran 分析 5 个 AI Agent 框架的上下文管理模式,揭示”内存层级”的系统演进
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些观察——我觉得值得说出来的那部分。
数据来源:
- Data Engineering Weekly #267(本期素材主要来源)
- 各公司工程博客原文(链接见文中各条)
《数据周刊》每周更新一期,挑数据行业值得看的动态,附拾穗的判断。拾穗数据|https://ss-data.cc


