
我五年前每周刷 LeetCode 和 SQL 题。
那时候有个习惯——上下班路上听播客,到了公司打开 LeetCode,挑两道中等难度的题,闭着眼睛刷。pandas 的语法烂熟于心,Spark 的 join 优化我能在白板上画三种实现方式。那一年我觉得自己最值钱的就是这种”熟练度”——简历上一摆,比同段位的人强一截。
去年我打开 LeetCode 想随便练一下,发现页面边上多了个按钮:“AI 一键解答”。点进去,我那天准备做 30 分钟的题,AI 用 3 秒把代码 + 解释 + 复杂度分析全部给我了。
那一刻我突然意识到一件让我有点无措的事——我过去 5 年最值钱的那一身”熟练度”,正在被以小时为单位地折旧。
这一波 AI 对学习的真实冲击是什么
这不是一篇讨论”AI 会不会替代数据人”的文章——这种讨论已经够多了。这是一篇讨论**“已经在数据行业里的人,接下来到底该学什么”** 的文章。
先把判断说在前面:
AI 没有替代数据人,但 AI 把”熟练度”这件事的相对价值打到了零。剩下来真正稀缺的,是表达力、阅读力,和那些 AI 还做不好的判断。
我前几天写过 《数据人的工具瘾》 和 《会用模型的能力清单》,分别讲了”不要再追工具""会用模型的 5 种能力”。这一篇是把这两条线合起来——给已经在数据行业里的人一张重新校准过的学习地图。
它的核心和 《技能折旧表》 不一样。折旧表讲的是”哪些区域该学、哪些该放”——是学什么。这一篇讲的是”怎么学、学到什么深度”——是学的方式本身该变。
论点一:表达力是 AI 时代最稀缺的能力之一
先讲我的核心判断——表达力会变成 AI 时代最稀缺的能力之一。
这听起来反直觉。“表达力”这个词模糊、文科、像是文学社的事。但 AI 时代的”表达力”完全是个工程能力——它是你让 AI 替你做事的关键接口。
具体讲,“表达力”在数据人这一行里至少包括下面几个形态:
第一种,把模糊需求翻译成具体指令的能力
业务方扔给你一句”看看用户活跃度怎么样”——含糊不清。你要在 30 秒内问出”看哪段时间?哪个产品线?要分群看吗?什么算异常?“——这是表达力。
这种能力在 AI 时代变得更重要——因为现在你不只是和业务方对话,还要和 AI 对话。AI 比业务方更愿意听你的,但 AI 更不能猜你的意思。你说不清,AI 就跑不准。
第二种,把复杂问题拆成可执行步骤的能力
数据建模就是这种能力的一种——把”一个用户行为”翻译成几十张表里的几百个字段。这件事 AI 永远做不好——它不知道你公司的具体业务、不知道哪些字段有歧义、不知道哪些维度需要保留可追溯性。
第三种,把分析结果说成”决策者听得懂”的话的能力
你跑出一组数据:DAU 上周下跌 7%,主要是新增用户下降。这是个 SQL 输出。
但你递给业务负责人的不该是 SQL,是这样一段话:
“上周 DAU 下跌 7%,但老用户活跃度其实是在涨的——下跌全部来自新增用户减少。结合上周市场投放预算降了 30%,我倾向是投放问题,不是产品问题。建议先看一下投放渠道的转化漏斗。”
前者 AI 能做,后者 AI 做不了——后者要求你理解决策者关心什么、有什么决策选项、用最少的话给最有用的判断。这是高阶表达力。
第四种,写文档、写复盘、写技术博客的能力
这一种最容易被低估,但实际复利最大。你能写清楚一件事,意味着你想清楚了这件事。反过来——写不清楚的东西,多半你也没想清楚。
写作是数据人最便宜的判断力训练器。
论点二:阅读力是另一个被严重低估的稀缺能力
第二个稀缺能力——阅读力。
这个词我用得很广。它指的不只是”看懂中文”,而是”在信息爆炸时代快速从陌生材料里提取要点的能力”。
具体形态:
第一种,读 AI 输出的能力
AI 给你写了 200 行代码、生成了一份 5 页的分析报告、推送了一段方案建议——你能不能 5 分钟之内判断它对不对、有没有 bug、哪些是真见解哪些是套话?
这是 AI 时代最直接的”阅读力”考验。能识别 AI 输出问题的人,越来越值钱。只能”接受 AI 输出”的人,就是在帮 AI 打杂。
第二种,读论文 / 技术文档的能力
技术变化太快,每周都有新的开源项目、新的论文、新的最佳实践。能不能 30 分钟读完一篇 arxiv 论文,提取关键贡献、判断是否值得跟进? 这种能力以前就值钱,AI 时代更值钱——因为信息密度太高了,慢慢读会被节奏甩开。
第三种,读开源代码的能力
LangChain、DSPy、MCP——这些项目你用还是不用先不说,你能不能花一个下午读完核心代码、理解架构? 这种能力是你独立判断”该不该用”的基础。只能跟着教程走、不能读代码的人,永远在被工具牵着走。
第四种,读人 / 读会议 / 读组织的能力
这是最高阶的阅读力——在一场会议里 30 分钟,听出谁是真做事的、谁在等结果、谁是潜在阻力。这种”读人”能力 AI 永远学不会,但它决定你能不能在公司里把事情推下去。
论点三:技术底层原理”知道和了解”,但不必再练熟
如果说表达力和阅读力是”加分项”,那么底层技术原理是”减分项”——该有,但不必深练。
这是这一篇里最反直觉、也最重要的一个判断。
过去数据人的学习模式是这样:
学一个新技术 → 读官方文档 → 跟着教程做几个项目 → 反复练习直到”闭眼能写”
这套模式的核心是”熟练度”。它在 AI 之前是对的——因为你的工作里需要每天写 SQL、每天调 Spark 参数、每天 debug pandas。熟练度直接决定你的产出速度。
但今天熟练度的边际价值已经不一样了:
- 你练了 100 小时的 pandas,AI Copilot 写得比你快、记得比你准
- 你练了 50 小时的 SQL,AI 一眼能看出比你优雅的写法
- 你练了一周的 LangChain,半年后 LangChain 已经被新框架替代
练熟练度,就是在和 AI 比赛”谁记得更多”——这场比赛你赢不了。
那应该投什么?应该投”知道和了解”——理解原理,能看懂、能判断、能在出问题时定位。
举几个具体例子,说明”练熟”和”知道”的区别:
Spark 性能调优:
- 练熟版本:背 100 个 spark.sql.shuffle.partitions 之类的参数、记住每个的默认值和场景
- 知道版本:理解 Spark 的执行模型、shuffle 是怎么发生的、partition 数对性能的影响逻辑——遇到具体问题让 AI 帮你查参数就行
SQL 优化:
- 练熟版本:背 30 种 SQL 重写技巧、能秒认 EXPLAIN 输出
- 知道版本:理解执行计划的核心元素(join 顺序、index 选择、cardinality 估算)——具体的 EXPLAIN 解读交给 AI
机器学习:
- 练熟版本:能从零实现 random forest、能手推 gradient boosting 的损失函数
- 知道版本:理解树模型 vs 神经网络的差异、bias-variance tradeoff、什么场景该用什么——具体的实现 sklearn 一行解决
Transformer 架构:
- 练熟版本:能从零实现 attention 机制、能默写 multi-head 的矩阵运算
- 知道版本:理解 attention 在做什么、自注意力为什么强、long context 为什么贵——这就够了
注意——这些”知道版本”也不是浅薄的科普。它们要求你真正理解”为什么”和”什么时候”——这种理解是判断力,不是熟练度。
判断力 = 知道边界,知道选择,知道何时不用。这不是 AI 能替代的。
学习时间该怎么重新分配
按上面三个论点,我建议把数据人的学习时间重新分配成下面这个比例:
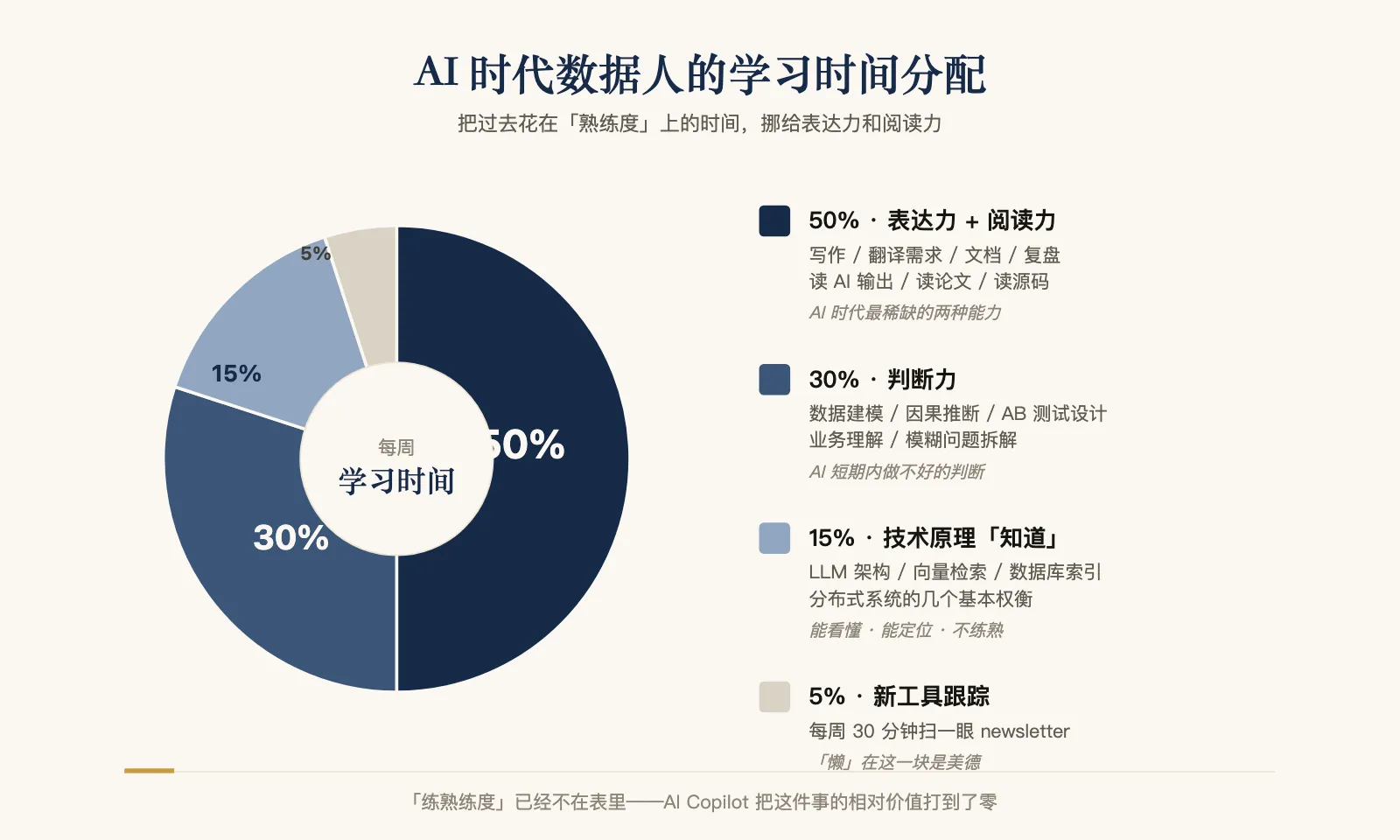
这和之前 《技能折旧表》 里给的 “保值 50% / 新生 30% / 中速 20%” 不一样——那一篇是从”内容”维度切的,这一篇是从”方式”维度切的。两个维度可以叠加用。
每一块的具体动作:
50% 表达力 + 阅读力
表达力训练:
- 每周写一篇 至少 2000 字的技术博客或业务复盘——发出去,被人读,接受批评
- 每天和 AI 对话之前先写”我想要什么”——具体到 schema、口径、格式。把 prompt 当文档写
- 看自己写的 prompt ——分析哪一步表达模糊。这是最直接的训练
- 学一两本经典写作书——William Zinsser 的《On Writing Well》、Steven Pinker 的《The Sense of Style》。这些书价值远超 AI 教程
阅读力训练:
- 每周读 1 篇 arxiv 论文 + 1 篇大厂工程博客 ——不要细读,练”快速提取要点”
- 每月读 1 个开源项目的核心代码 ——挑你正在用的,比如 LangChain、DSPy、Iceberg。读它的设计、不要只用 API
- AI 每次给你输出之后,强迫自己挑出 1-2 个”它做得不够好的地方” ——这是最直接的阅读力训练
30% 判断力(建模 / 因果 / 业务)
这一块和之前那篇 《技能折旧表》 讲的”保值区”重合,不重复。简短列几条:
- 系统读完 Kimball 的《数据仓库工具箱》
- 学一遍因果推断(Pearl 的《Book of Why》入门 + Cunningham 的 Mixtape 进阶)
- 做完整的 AB test 设计——从假设、样本量、统计检验、解读
- 持续在公司接”模糊问题”——这是判断力的真实训练场
15% 技术原理”知道”
不用深练,但要”知道”:
- LLM 架构:Transformer / attention / context window 的本质
- 向量检索:embedding / similarity / ANN 算法的核心思想
- Spark / Flink 的执行模型——理解 shuffle、stage、checkpoint 是什么
- 数据库索引、查询优化、并发控制的核心概念
- 分布式系统的几个基本权衡(CAP / 一致性 / 容错)
这些不是为了在面试里答出来,是为了”出问题时能定位”。具体写代码、写 SQL、调参数的事情,让 AI 干。
学习方式建议:读 1-2 本入门好书(不是教程)+ 看几个高质量讲解视频——比如 3Blue1Brown 的 Transformer 系列、Andrej Karpathy 的零基础课。不要刷题、不要背参数、不要默写代码。
5% 新工具跟踪
保持这个比例——不要让它变成 50%。新工具有红利,但红利窗口期通常 6-12 个月。
具体做法:
- 订阅 1-2 个高质量 newsletter(Data Engineering Weekly、Benn Stancil)
- 每周 30 分钟扫一眼新动态
- 看到值得深入的,就深入;看不到就拉倒
- 不要追每一个 hype——“懒”在这一块是美德
几个反直觉的建议
写到这里有几条反直觉但我觉得真有用的建议:
第一,写代码越来越像写诗——不在量在质
5 年前我会觉得”写代码就是要快”。现在我反过来想——该慢的时候要慢。AI 帮你写出一段代码,你读一遍、想一遍、改一遍——慢的那部分时间比写本身值钱。
第二,每周留 4 个小时”无 AI 时间”
这听起来反 AI,但我自己跑了半年发现——每周强迫自己 4 个小时不用 AI、自己想问题、自己写代码、自己读资料,对判断力的训练效果惊人。AI 用太多会让你的”独立思考肌肉”萎缩。
第三,看一个工具值不值得学,先问”它的核心思想在 5 年后还存在吗”
如果一个工具的核心思想(不是 API)5 年后还会存在,可以学。如果它本身就是临时形态——比如某个具体框架的某个版本——浅尝辄止。
第四,不要追”全栈 AI 工程师”这种标签
我前一篇讲过 《“AI 工程师”是不是泡沫》。同样的逻辑——追”全栈 AI”这种标签 5 年后会回头看是个坑。做深一两件事,比浅尝十件事更值钱。
第五,最值钱的不是”学得快”,是”学得对”
“学得快”在 AI 之前是有价值的——因为你能比同事先掌握新工具。AI 之后这个红利消失了——AI 学得比你快得多。剩下来真正重要的是”学得对”——投在对的方向、深到对的程度、放弃对的东西。
收束
如果让我给这一篇做一句话的收束:AI 时代数据人最值得投的两件事,是表达力和阅读力——剩下的事情,知道、了解、关键时让 AI 帮你。
这篇兑现了我前面几篇里反复出现的那个钩子——“工程路线学习地图”。但我后来想清楚了——地图本身不是这一篇的核心。核心是这套学习心法。有了这套心法,你自己就能给自己画地图——根据你所在的领域、你的段位、你的兴趣。
我自己接下来想做的事,是把这套心法在自己身上跑一遍——把过去花在”熟练度”上的时间挪给表达力和阅读力,看一年之后能不能感受到差异。
说到这里我自己一直在琢磨一件事——这套学习心法,对不同段位的数据人(应届 / 2-4 年 / 4-6 年 / 6+ 年)的具体落地动作会是什么?我应不应该按段位再写一份具体的实操指南? 这是我最近在想的下一个题目,有想法的朋友可以加我微信(shisuidata)一起聊。
我叫石头,在数据行业里摸爬滚打了十几年,学到的东西大半是在做错之后才想明白的。这里写的,就是这些教训——我觉得值得说出来的那部分。
拾穗数据|https://ss-data.cc


