
我有个朋友,5 年前花了 1 万 5 考了 Cloudera 的 CCP 数据工程师认证,那时候这是大数据圈子里挺硬的资历——简历上一摆,年薪可以多谈 10%。
去年他跳槽,面试官一脸茫然问他:“Cloudera 是什么?”
类似的事每个数据人身边都有几个。Storm 这个项目你们还记得吗?2014 到 2017 年大厂实时数仓的当家技术。HBase 呢?Sqoop?Pig?这些当年简历上闪闪发光的关键词,今天你写上去面试官多半会看一眼然后跳过。
技能不是不会被替换,是替换速度永远比你以为的快。
什么叫”技能折旧”
汽车折旧好理解——你今天买一辆车,明天开出 4S 店就便宜 10%。技能也类似,区别是你看不见折旧的过程。
技能折旧的常见形态有四种:
第一种,被新技术替代。你会的那个工具被一个更顺手的工具取代了。Storm 被 Flink 替代、Pig 被 Spark SQL 替代、传统 ETL 工具被 dbt 替代——你之前花的时间还在,但市场不再为它付费。
第二种,被自动化吃掉。这是 AI 时代的主旋律。你之前做的事变成了一个工具按钮,比如”写一段把 raw 表清洗成宽表的 SQL”——以前是数据工程师 2 小时的活,现在 AI Copilot 30 秒。
第三种,门槛降低。你的技能本身没过时,但学会它的成本变低了。供给变多,单价变低。Python 数据分析现在大学生都会,10 年前是稀缺技能。
第四种,标准变了。市场对”什么算合格”的标准变高了。10 年前你会写 SQL 就是数据分析师,今年你只会写 SQL 但不会做归因分析、不懂 AB test、不能写出业务洞察——你拿不到 offer。
理解这四种形态,是为了搞清楚一件事——不是所有技能都按同样的速度折旧。差异巨大。
技能折旧表(数据从业者版)
下面这张表是我自己最近梳理的,结合身边朋友的市场反馈和招聘数据(Indeed Hiring Lab 报告、各家 JD 关键词分布观察)。按折旧速度分四个区:

下面是逐区的详细列举——
🔻 加速折旧区(2-3 年内市场需求大幅下降)
| 技能 | 折旧原因 | 当前还能用多久 |
|---|---|---|
| 纯 ETL 工具操作(Informatica / Kettle / DataStage) | 被 dbt + Airflow 生态替代,AI 还在加速这个过程 | 3-5 年 |
| 单一平台技能(Hadoop / Cloudera 全家桶) | 云数仓和湖仓一体把它挤到边角 | 2-3 年 |
| Pig / Storm / Sqoop / HBase 操作 | 已经基本退出主流 | 已经过期 |
| 会写 SQL 但不懂业务的”取数员” | AI Copilot 30 秒能写 | 2 年 |
| 做基础报表 / 看板搭建 | 自助 BI + AI 接管 | 3 年 |
| 简单的描述性统计分析 | AI 标准动作 | 2 年 |
| 模板化的 PPT 汇报 | AI 一键出 | 1 年 |
特征:纯执行性、强工具依赖、低判断含量
🟡 中速折旧区(5-10 年仍有市场,但回报递减)
| 技能 | 现状 |
|---|---|
| Python 数据处理(pandas / numpy) | 基础项,必须会但不再加分 |
| Spark / Flink 开发 | 仍是核心技能,但要求叠加场景理解 |
| 传统数仓建模(Inmon / Kimball) | 没过时,但要会迁移到云原生 |
| 经典机器学习(决策树/线性回归/聚类) | 仍有价值,但被深度学习和 LLM 挤压 |
| 标准 AB 测试执行 | 不过时,但要懂得设计而不只是跑 |
特征:仍是”基本盘”,但单独靠它已经撑不起市场价
🟢 保值区(10 年甚至更长依然增值)
| 技能 | 为什么保值 |
|---|---|
| 数据建模思维(不是工具) | 业务再变、工具再变,建模本质不变 |
| 因果推断 / 实验设计 | 反直觉、需要数学和判断力,AI 短期内做不好 |
| 业务理解 + 翻译能力 | 把模糊业务问题变成具体数据问题——这是 AI 最弱的环节 |
| 数据治理 / 元数据 / 血缘 | 越来越重要,且工具替代不了治理决策 |
| 系统架构设计 | 全局视角 + 取舍判断,AI 能辅助但替代不了 |
| 写作 / 表达 / 影响力 | 跨任何技术周期都增值 |
特征:判断力 + 跨场景 + 不依赖特定工具
🌱 新生区(出生 2 年内,正在加速升值)
| 技能 | 当前价值信号 |
|---|---|
| RAG 系统设计与优化 | JD 出现频率显著上升(参见 Indeed 报告中”数据/分析岗 45% 含 AI 关键词”的趋势) |
| Agent 编排 / 多 Agent 协作 | 几乎所有 AI 工程岗都在问 |
| LLM 评测体系(eval / trace / golden set) | 真正能让 AI 产品上线的关键能力 |
| Prompt 工程 / Context 工程 | 从被嘲笑到被严肃要求 |
| 向量数据库 / 语义检索 | 标配 |
| 模型选型 / 成本优化 | 新岗位”AI Cost Engineer”已经在出现 |
| LLMOps / AI 平台可靠性 | 上一期周刊讲过的 Whatnot 那篇就是典型案例 |
特征:刚有市场需求、供给还没跟上、入场早的人享有溢价
为什么差异这么大
把上面四个区域放一起看,你会发现一个规律——越靠近”工具”的技能,折旧越快;越靠近”判断”的技能,折旧越慢;越靠近”新工具配新判断”的技能,反而在升值。
为什么?
工具是有形的、可复制的、有替代品的。任何一个具体工具——Cloudera 也好、Storm 也好、Informatica 也好——它的本质是”针对某个时代的工程问题给出的一个解”。时代变了,问题被新工具更好地解了,老工具就退场。这是技术演化的常态。
判断力是抽象的、个人化的、积累型的。“这个数据该信吗""这个业务问题该怎么拆”——这种事你从入行第一天开始练,到第十年还在练。AI 现在能模拟一部分判断,但判断力的核心是基于上下文 + 经验的”知道在乎什么”——这是 AI 短期内做不到的。
新工具配新判断为什么升值?因为市场刚刚意识到自己需要它,但合格供给还没到。RAG 系统设计、Agent 编排、LLM 评测——这些技能两年前几乎没有市场,现在 JD 上越来越多,但有真实生产经验的人还很少。供需缺口 = 溢价。
学习时间该怎么分配
如果你认同上面的分类,下面是我的建议——把你的学习时间切成三块:
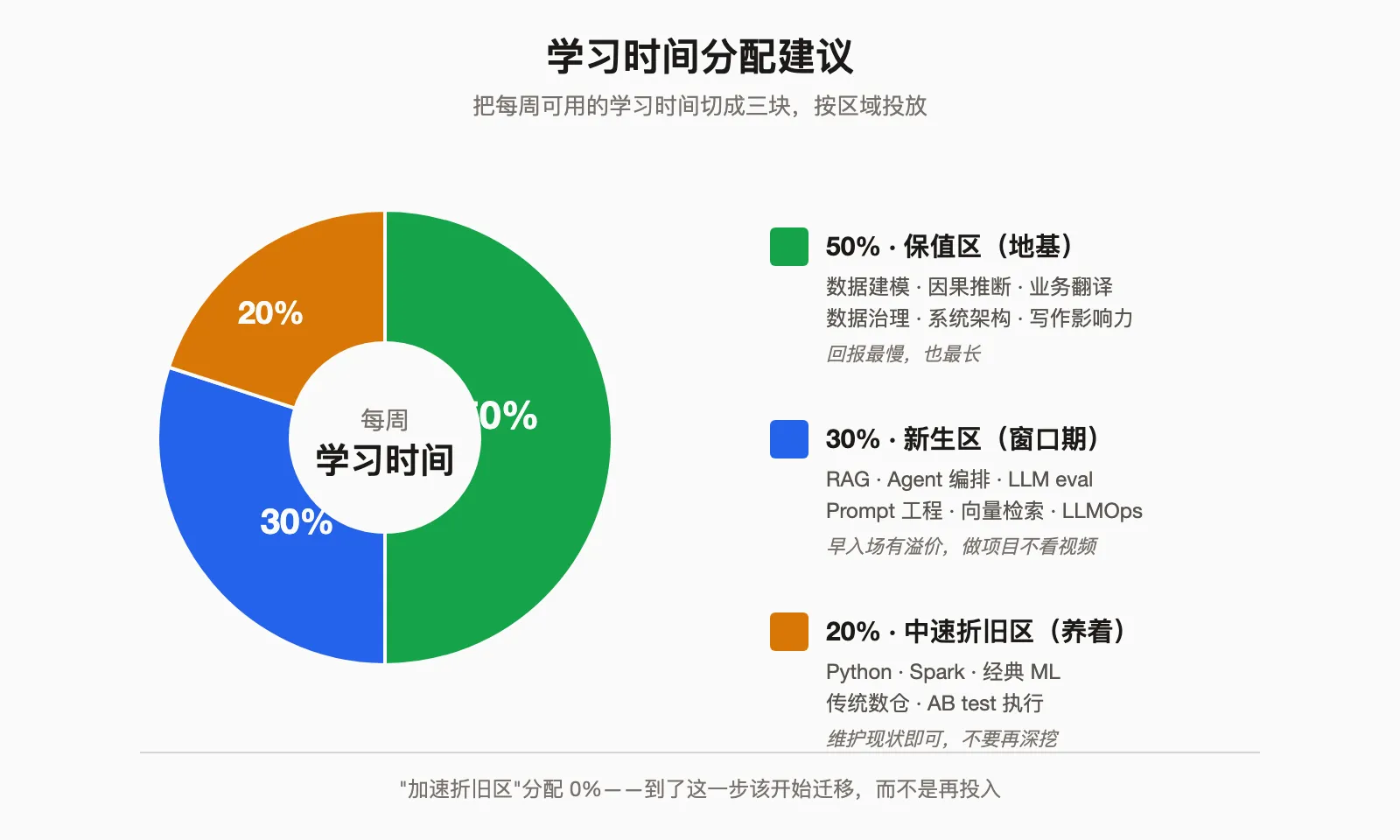
第一块:50% 投在”保值区”打基础
这是地基。如果你刚入行 1-3 年,所有的判断力训练都不嫌多。具体可以这样投:
- 系统读完 Kimball 的《数据仓库工具箱》(这本书 30 年了,依然是数据建模圣经)
- 学一遍因果推断——推荐 Judea Pearl 的《Book of Why》入门 + Scott Cunningham 的 Causal Inference: The Mixtape 进阶
- 找机会做完整的 AB test 设计——不只是跑实验,是从假设、样本量、统计检验、解读这一整套
- 每周写一篇技术或业务复盘,强迫自己练”把模糊问题说清楚”的能力
这部分投入回报最慢,但回报最长。5 年后你和同期入行的人之间,就靠这一块拉开本质差距。
第二块:30% 投在”新生区”抓窗口
新生区的特点是早入场就有红利。但风险是它可能不会变成下一个保值区——比如 5 年前的”区块链工程师”。
所以这一块的投入要带一点理性的赌性:
- 集中投在已经有真实落地案例的方向——RAG、Agent、LLM eval、向量检索。这些不是 hype,是已经有大厂在用的工程能力。
- 做项目,不是看视频。学这些技能最快的方式是建一个能跑的小系统——哪怕是一个 RAG 化的”我的笔记问答机器人”。
- 关注开源项目的演进——LangChain、LlamaIndex、DSPy、MCP——这些是这一波技术的”工具书”。
- 在公司里主动接一个 AI 项目。哪怕只是一个内部小工具,把它做到能上线、能被同事用——你的简历上会多一笔硬通货。
第三块:20% 投在”中速折旧区”维护现状
这部分是养着——保持基本盘不丢,但不要再过度投入。Python、Spark、传统数仓这些技能你已经会了,每年花 20% 的时间维护更新就够。不要再为一份新的”Spark 性能调优大全”花一个月去啃——你会的那点已经够用了。
剩下的 0% 给”加速折旧区”——别再投入了,到了这一步就该开始迁移。
一个反例:保值不等于不学
需要澄清一件事——保值区的技能不会贬值,但你的”对它的掌握程度”会贬值。
5 年前你做的 AB test 是”分流量看 ctr 涨没涨”,今年公司期待的 AB test 是”考虑长期效应、考虑 sleeper effect、考虑因果识别、考虑实验间互相干扰”——同样叫 AB test,深度要求完全不一样。
保值区不是”学一次永久受益”的躺平区。它是”你必须不断加深理解”的区域——只是加深的方向不会错。
一个更长远的判断
AI 这一波下来,最值钱的不是某个具体技能,是**“判断什么会折旧”这个能力本身**。
5 年前我看到 Hadoop 那一套全家桶,没多想就跟着学了。后来发现这一套被云数仓挤到边角,自己投在上面的时间一去不返。
今年再看 LLM 这一波,我学聪明了——不再死磕某个特定 framework(LangChain 半年迭代一次架构,你跟得过来吗?),而是死磕”模型无关”的能力:怎么写好 prompt、怎么搭 eval、怎么管 context。
这种”看清折旧速度”的能力,是元能力。它指导你下一次该投资什么、该放弃什么。它本身永远不会折旧——因为每一次技术换代,市场都需要这种判断。
一句话收束
技能折旧不可避免,但可以管理;判断什么会折旧的能力,永远值得投资。
说到这里我自己一直在想一件事——如果让我画一张”数据从业者每个段位 5 年内的学习地图”——保值区学什么、新生区抓什么、什么时候放弃什么——会长什么样? 这是我最近一直在梳理的,有想法的朋友可以加我微信(shisuidata)一起聊。
我叫石头,在数据行业里摸爬滚打了十几年,学到的东西,大半是在做错之后才想明白的。这里写的,就是这些教训——我觉得值得说出来的那部分。
数据来源:
- Indeed Hiring Lab:January 2026 US Labor Market Update(数据/分析岗 45% 含 AI 关键词的来源)
- Anthropic:Labor Market Impacts of AI Research
- 上一期周刊提到的 Whatnot LLM 平台案例:拾穗·数据周刊第 3 周
- 技能分类 + 折旧速度判断为作者基于多源招聘数据 + 业内观察的综合整理
拾穗数据|https://ss-data.cc


