
本期三件事:Whatnot 讲了 LLM 平台的真话——模型反而是最轻的一块;Slack 拆解长跑 Agent 的上下文管理难题;Teads 让 AI 编排 ML 实验,带来约百万美元利润。一个共同的结论——到了生产环境,Agent 的坎不在模型,而在基础设施。
上周我们聊了 Agent 要做小、拒绝万能。这一周的讨论接着往下走了一层——Agent 做小了之后,怎么让它真的稳定跑在生产上。几篇来自 Whatnot、Slack、Teads、Pinterest 的复盘,视角高度一致:模型再强,基础设施不到位,一切白搭。
下面是本期的主要内容。
行业动态
Whatnot:模型是最简单的部分
美国直播电商平台 Whatnot 工程团队写了一篇复盘,讲他们这两年搭 LLM 平台的教训,标题就很直接:《模型是最简单的部分》。
核心论点:生产环境里的 LLM 问题,80% 以上和模型本身无关——超时、流控、重试、上下文丢失、漂移检测、成本追踪,这些基础设施问题占据了工程师绝大部分精力。他们列了几个”可靠性支柱”:流量调度、降级链路、监控告警、漂移检测。每一个听起来都不新鲜,但都不能少。
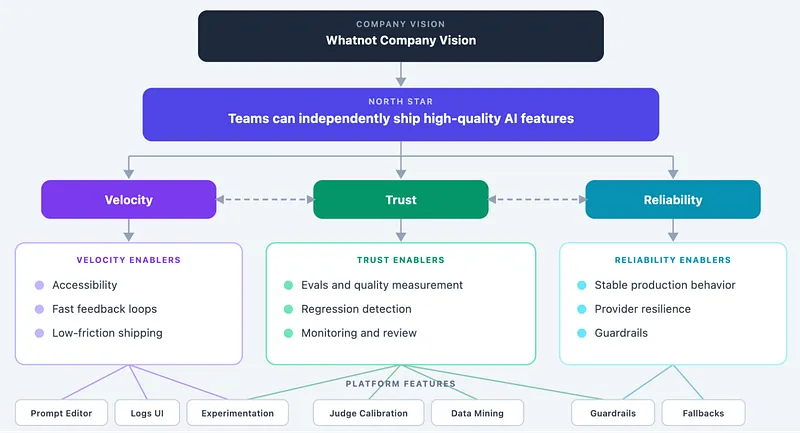
原文:The model is the easy part: Building the LLM Platform at Whatnot · Whatnot Engineering
Slack:长跑 Agent 的上下文管理
Slack 工程团队发了一篇关于多 Agent 长期运行的文章,重点解决一个具体问题——多个 Agent 协作、任务跨几小时甚至几天时,上下文会丢、会漂移、会互相打架。
他们的方法用了三件配合的工具:
- Director’s Journal(导演日志)——一个共享的结构化上下文池,所有 Agent 读写同一本”日志”
- Critic(评审 Agent)——专门一个小 Agent 负责打分,识别”这一步是不是走偏了”
- 时间线剪枝——定期把无关历史折叠掉,只保留决策轨迹
这套组合拳把长跑任务的一致性问题压下去了。
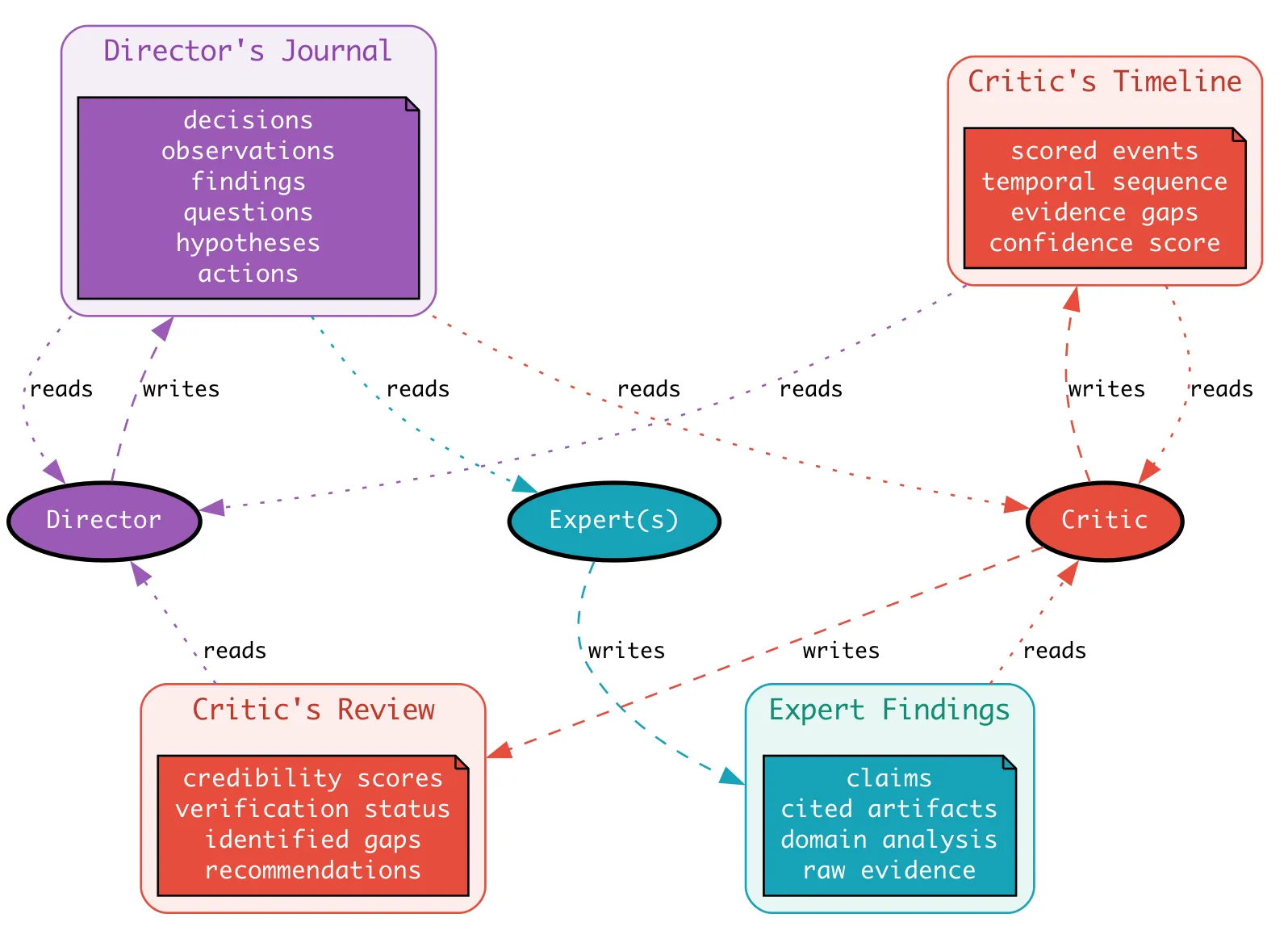
原文:Managing context in long-run agentic applications · Slack Engineering
Teads:AI 编排 ML 实验,百万美元利润
Teads(广告技术公司)让 AI Agent 通过 MCP API 直接编排 ML 实验——从数据准备到模型训练到评估到上线决策,Agent 全程跟进。带成本护栏(防止 Agent 自己跑飞账单)。
结果:实验吞吐量显著上涨、工程师从重复劳动里解放出来、为公司带来约 100 万美元的净利润(这个数字是他们自己算的增量贡献)。
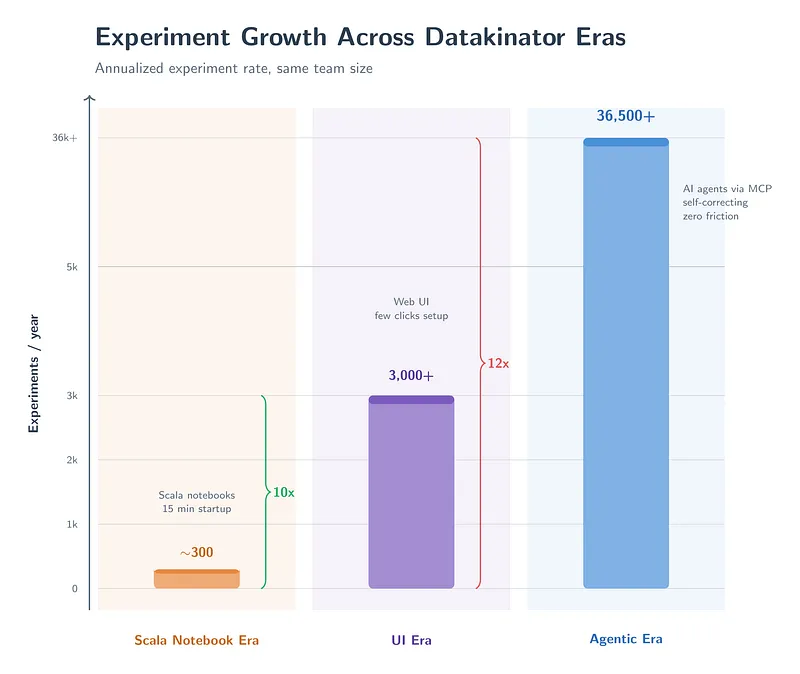
原文:We Let AI Agents Orchestrate Our ML Experiments · Teads Engineering
观点看点
AI-Ready Data vs Analytics-Ready Data
一位叫 Animesh Kumar 的数据架构师写了篇观点,把 “AI 就绪数据”和”分析就绪数据” 区分成两个不同的轴。
他的论点:分析用的数据是面向人类解读的,口径清晰、字段规范、能 join;但 AI Agent 用的数据需要的是完整的上下文——包括字段的业务含义、历史演化、使用场景、异常模式等。传统数仓建模解决前者,解决不了后者。
换句话说,你司的 Kimball 数仓再漂亮,AI Agent 也可能用不明白。
原文:AI-Ready Data vs. Analytics-Ready Data · Animesh Kumar
Agentic BI 的前提是数据质量
SafetyCulture 的一位工程师 Thiago Baldim 写了他们做 “Agentic BI”(让 AI 直接回答业务问题)的踩坑记录。结论很朴素——AI 再牛,底下数据口径乱、血缘不清、测试不足,一切都是白搭。他们最后做的不是上更强的模型,而是把 Kimball 数仓重建了一遍,把测试密度加上去,把归属权理清楚。
原文:The journey to Agentic BI · Thiago Baldim
拾穗解读:AI 时代最贵的,是”让它能跑下去”
上周讲完”Agent 要做小”,我自己一直在想一个后续问题——做小之后呢?怎么让它真的跑到生产、稳定服务用户? 这一周的内容刚好回答了这个问题,而且回答得相当扎实。
先说 Whatnot 那篇。标题《模型是最简单的部分》挺有冲击力,但读完你会发现这不是危言耸听。他们列的那些”可靠性支柱”——流量调度、降级链路、漂移检测、成本追踪——每一个都是数据工程师熟悉的老朋友。过去我们说数据工程师”干脏活”,在 AI 时代这份脏活不但没少,反而更多了。原先建一个 ETL 管道,坏了用户看到的是数据延迟;现在 LLM 接口挂了,用户看到的是”AI 回答乱说话”甚至”直接没回应”。故障面放大了十倍,工程要求也相应放大十倍。
这里面有一个容易被忽略的转变。过去数据团队的输出是”可信的报表”,现在要变成”可信的 Agent 行为”。前者是一次性结果,后者是持续性服务。这不是量的累加,是质的跳跃。身边有些团队还没意识到这事儿的难度,以为搞一个 RAG Demo 就是上线了——那其实只是起点。
Slack 那篇讲 Agent 上下文管理,我印象最深的是 Director’s Journal 这个设计。它本质上是给多个 Agent 协作时设的”共享记忆”。听起来技术含量一般,但解决了一个非常真实的痛点:多 Agent 系统跑长了,每个 Agent 都觉得自己在做正确的事,但合起来在做错误的事。国内做 Agent 平台的团队如果没遇到过这个问题,大概率是还没真的跑起来。
Teads 那条最有意思。100 万美元利润不是用户付给 Agent 的——是 Agent 替公司省下来的人力和跑实验的周期。这个数字的含义是:AI Agent 的第一波真实 ROI,不在”卖给 C 端用户”,而在”替内部团队打杂”。国内很多公司在想 AI 产品怎么赚钱——也许答案是:先别想赚 C 端的钱,先用它把内部重复劳动消化掉,那就是真金白银的节流。
本期还有一类我每次都会留意的内容——基础设施的胜利,往往来自不被看见的工程优化。像上周 Netflix Druid 的缓存、这周 Pinterest 推荐系统的请求级去重(我放在了本周其他值得看里),这类工程没有论文可发、没有故事可讲。80% 的性能来自 20% 的关键路径,但这 20% 从来不会出现在架构图 PPT 上。它藏在某个缓存代理、某个去重逻辑、某段不起眼的 SQL 里。一个数据团队有没有做这种事的习惯,是区分”能跑”和”能赚钱”的分水岭。
最后是 AI-Ready vs Analytics-Ready 这个提法。我觉得它戳中了一个很多公司没想清楚的矛盾——你司数仓再漂亮,Agent 可能还是用不明白。因为 Agent 需要的不仅是”字段能查到”,还需要”字段的业务语境、边界条件、历史异常都查得到”。这是一个文档工程的问题,不是建模工程的问题。听起来有点像十几年前我们讲”数据字典要写全”,只是那时候我们写给人看,现在要写给 AI 看。
如果让我给这一期做一句话的收束:AI 时代,最贵的不是模型,是”让它能跑下去”的那套基础设施,以及愿意去做这件事的工程师。
说到这里我自己一直在想一件事——Whatnot 那句”模型是最简单的部分”言下之意是工程才是难的那块。那么一个从零起步的数据人,这条”工程路线”的学习地图长什么样? 从哪里起步、中间有哪些坎?这是我最近在慢慢梳理的一件事,有想法的朋友可以加我微信(shisuidata)一起聊。
本周其他值得看的
- Scaling Recommendation Systems with Request-Level Deduplication:Pinterest 在 ML 推荐全链路做请求级去重,基于 Iceberg + 交叉注意力 Transformer 压成本
- Engineering the Forge Billing Platform for Reliability and Scale:Atlassian 计费流水线日处理 3 亿事件,去重 + 校验 + 双层存储的确定性设计
- From Events To Real-Time Profiles On Apache Fluss:Apache Fluss(新的实时存储项目)+ Roaring Bitmap 做实时用户画像,延迟从小时压到秒
- Daedalus and the Data Labyrinth:Just Eat 的多层数据治理组合拳——词典 + 目录 + 元数据 + 质量信号 + 语义层
- The AI Modernization Guide:Dagster 出的指南,讲怎么把老数据平台改造成 AI 就绪状态(官方软文但有干货)
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些观察——我觉得值得说出来的那部分。
《数据周刊》每周更新一期,挑数据行业值得看的动态,附拾穗的判断。拾穗数据|https://ss-data.cc


