
本文来源于数据从业者全栈知识库,更多体系化内容请访问知识库。
Agentic Data Engineering 方法论
一句话判断数据工程师不会被 Agent 取代,但”写管道的数据工程师”会。价值重心从执行指令迁移到设计意图、护栏和数据产品契约。Intent replaces instructions, intelligence replaces toil——但前提是基础设施先配得上 Agent。
前置知识读这篇之前,建议先了解 AI Agent 智能体概述、MCP 学习路线图 和 数据产品架构。如果这三个概念你还觉得陌生,下面的判断会悬在空中。
一、先把焦虑摆到桌面上
2026 年春天,一个在字节做了六年数据开发的朋友半夜给我发消息:Databricks 的 Agent Bricks 把他上周写的一条 CDC 链路在 11 分钟内重写了一遍,指标对得上,代码比他干净。他问我:“我是不是该转行了?”
我说不是。但你不能再把自己定义成”写管道的人”了。
Qlik、Databricks、Nexla、Snowflake 在 2026 年前后不约而同提出了一个名字:Agentic Data Engineering。这不是又一轮”低代码取代工程师”的旧故事——那些故事失败是因为低代码平台的抽象做得粗糙,工程师绕过它们反而更快。Agent 不一样。Agent 会在你眼皮底下写 SQL、读日志、调 API、改 DAG。你第一次真切感到,有个东西在做你以前做的事。
焦虑是真的。判断也要是真的。
二、为什么传统数据管道不配被 Agent 消费
先问一个反直觉的问题:Agent 已经能写管道了,为什么还搞不定生产级的数据问题?
答案不在 Agent 身上,在管道身上。过去二十年我们为人类工程师和 BI 报表设计的数据管道,根本不是为 Agent 设计的。
传统数据管道有三个假设:
- 查询是可预测的。BI 报表的 SQL 是开发时写死的,运行时只换参数。数仓建模围绕已知问题做聚合。
- 链路是单向的。数据从 OLTP 流向 ODS、DWD、DWS、ADS,越往下游越静态。写回是例外。
- 上下文是离线的。T+1 的批处理是默认节奏,业务含义写在 Confluence 里,不在数据里。
Agent 的工作负载恰好在这三点上全部反着来:
| 维度 | 人类/BI 负载 | Agent 负载 |
|---|---|---|
| 查询模式 | 预定义 + 少量 Ad-hoc | 完全不可预测、跨域组合 |
| 方向 | 单向(读) | 读+写回(action-taking) |
| 上下文 | 离线文档 | 必须可机读、实时、带语义 |
| 时延 | 分钟级~小时级 | 秒级甚至亚秒级 |
| 治理颗粒度 | 表/字段级 | 行级、属性级、按意图授权 |
你让 Agent 去”查过去 30 天华北区复购率异常的类目”,它需要同时访问订单、用户画像、类目主数据、异常检测结果。这些数据可能分散在 Hudi 表、ClickHouse、特征库、Elasticsearch 里。没有统一的语义层和数据产品契约,Agent 要么瞎猜表名,要么返回一堆 hallucination。
核心判断**你不能把一个为人类设计的数据平台扔给 Agent,然后指望它表现得像个高级工程师。**它更可能表现得像一个刚入职三天、没人带的实习生——而且不会脸红。
三、Agentic Data Engineering 的四层模型
我把这套新范式抽成四层。这不是 Databricks 官方画法,是我自己在给客户做咨询时反复验证下来的框架。

第一层:Intent Layer(意图层)。用户的输入不再是 SQL,而是自然语言意图。这一层最怕”裸奔的 Text-to-SQL”——没有语义层兜底,Agent 会把”GMV”翻译成十种不同的 SUM。语义层(如 Cube、dbt Semantic Layer、AtScale)在这里是必需品不是可选项。
第二层:Orchestration Layer(编排层)。Planner 拆解意图,Executor 调用工具,Critic 做 Eval 和护栏。工具调用统一走 MCP 协议,避免每个 Agent 都造一套私有协议。相关架构参考 Agentic-RAG 进阶架构。
第三层:Product Layer(数据产品层)。这一层是灵魂。Agent 不直连底层表,只访问发布为数据产品的契约接口。每个数据产品有 Owner、SLA、Schema 契约、血缘、访问策略。这和 数据产品架构 是一脉相承的。
第四层:Infrastructure Layer(基础设施层)。Lakehouse 提供统一存储,流批一体支持低延迟查询,向量库承载语义检索,可观测性系统记录每次 Agent 调用的血缘。
四层之间有严格的访问方向:上层只能通过契约访问下层,不能穿透。这是 Agent 可信的前提。
四、数据工程师的三次角色迁移
把时间线拉长,数据工程师这个岗位其实已经迁移了两次。
| 阶段 | 核心工作 | 关键技能 | 价值来源 |
|---|---|---|---|
| ETL Engineer(2010s) | 写管道、调度作业 | SQL / Shell / Informatica | 把数据从 A 搬到 B |
| Data Platform Engineer(2020s) | 建平台、做治理 | Spark / Airflow / K8s / dbt | 让别人能自助用数据 |
| Intent Architect(2026+) | 设计意图契约、护栏、Eval | MCP / 语义层 / Eval 框架 / 数据产品契约 | 让 Agent 能可信地用数据 |
第三次迁移的关键词是契约和护栏,不是管道。
这意味着什么?意味着你的简历不该再写”负责 XX 业务线 ETL 开发,日处理 500TB”——这件事 Agent 做得比你快。应该写”设计了 XX 域的数据产品契约体系,支撑 Agent 工作流日均 20 万次调用,幻觉率低于 0.3%”。
一个判断一个数据工程师的价值,越来越取决于他让 Agent 不出错的能力,而不是自己不出错的能力。
五、一个具体案例:从”华北复购率异常”到答案
抽象讲完了,落到一个真实场景。某头部电商的数据中台支持这样一个业务请求:
“给我看过去 30 天华北区复购率异常的类目,按影响的 GMV 降序排。”
这个请求在旧范式里怎么处理?业务找分析师,分析师写 SQL,SQL 跑 10 分钟,结果发到飞书,第二天老板问”异常怎么定义的”——然后返工。
在 Agentic Data Engineering 范式里,流程长这样:
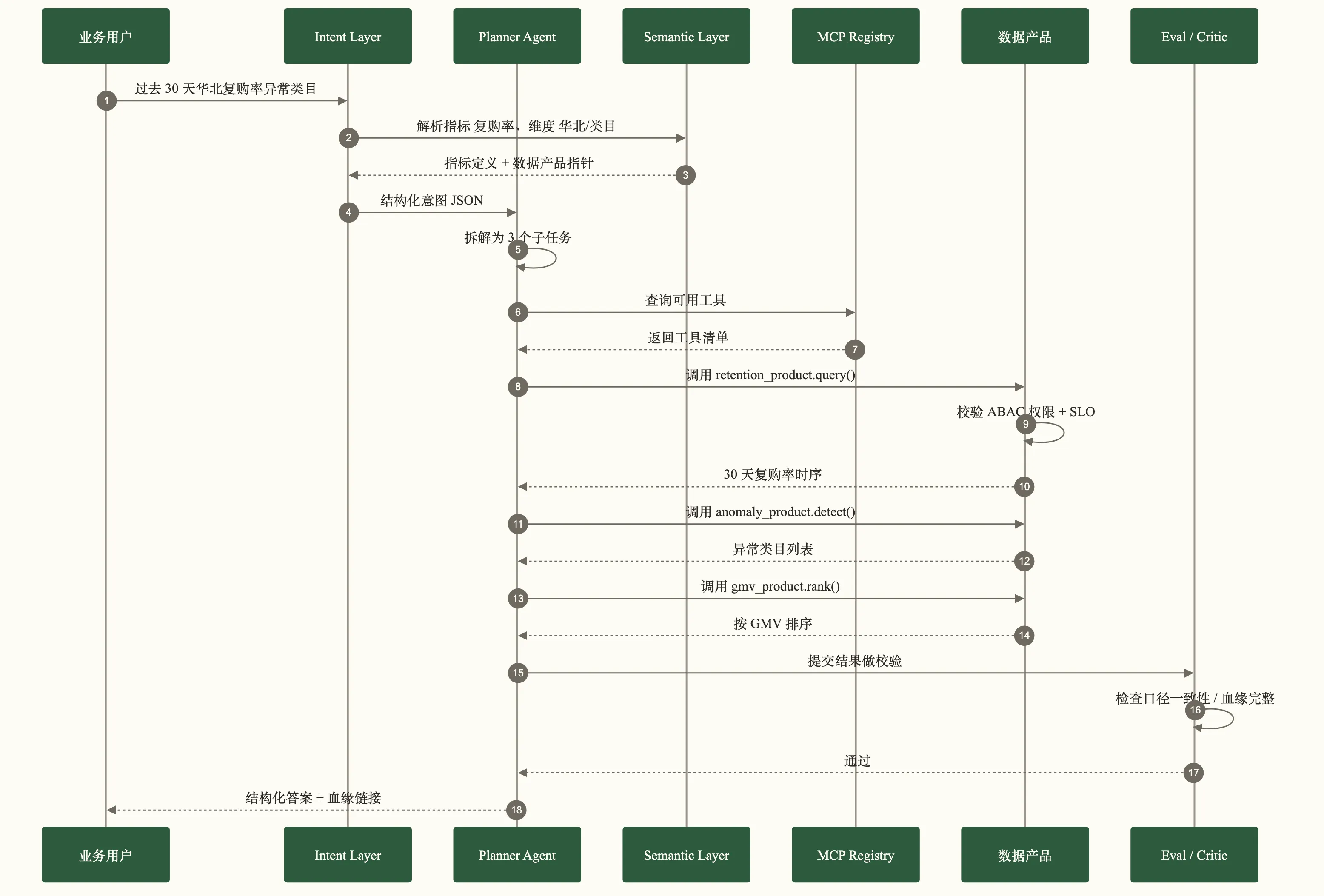
整条链路 8 秒完成。关键细节:
- Agent 从来没有直接写 SQL 访问底层 Hudi 表。它调用的是
retention_product、anomaly_product、gmv_product三个数据产品。 - 指标”复购率”的定义由语义层给出,不由 Agent 即兴发挥。
- 权限校验发生在数据产品层(ABAC,按用户属性),不是表级 GRANT。
- Critic Agent 在返回前检查口径一致性——三个产品的时间窗口、地域定义必须对齐。
- 最后返回的不只是数字,还有血缘链接,业务可以一键溯源”这个异常是怎么算出来的”。
这套链路为什么能跑通?因为数据工程师事先花了六个月,把这三个数据产品的契约、SLO、血缘、Eval case 都设计好了。Agent 只是在他们铺好的轨道上跑。
六、五个反模式:别把新范式搞砸
我在咨询中见过的”把 Agentic Data Engineering 搞成灾难”的套路,几乎都逃不出这五个:
反模式 1:把 Agent 当”更便宜的工程师”。直接把生产问题甩给 Agent:“去把这个告警排查一下。“Agent 会给你一个看起来合理的答案——它永远会给——但没人知道对不对。生产环境没有不验证的答案,这条底线不能破。
反模式 2:没有语义层就搞 Text-to-SQL。Text-to-SQL 的 demo 看起来很炫,上线就翻车。“GMV”在不同部门有五种算法,Agent 只会选 token 概率最高的那种,不会选对的那种。
反模式 3:把治理留到最后。“先让 Agent 跑起来,治理以后再说”——这句话的另一个版本叫”先上线再说,技术债以后再还”。经验告诉我们:以后永远不会来。
反模式 4:忽视 Eval 体系。没有 Eval,你根本不知道新版本 Agent 比旧版本好还是坏。凭感觉调 Prompt 是 Agent 时代的”凭感觉调参”。建议参考 Agentic-RAG 工程实战 中的 Eval 方法论。
反模式 5:让 Agent 直连底层表。这是最致命的一条。一旦 Agent 能看到 ods_order_detail,它就会用它。一年后你想重构这张表,发现有 47 个 Agent workflow 依赖它——而且没人知道这些 workflow 在哪。数据产品契约存在的全部理由就是隔离。
七、三条不能让:工程师的底线
有朋友问我:“那到底哪些工作绝对不能交给 Agent?”
我的清单只有三条,但每一条都是底线:
第一条:数据合约的定义权不能让。一张表的 Schema 是什么、指标口径是什么、SLA 承诺是什么——这些决策必须由人类工程师做。因为这些决策背后是跨团队的契约,需要商业判断、政治斡旋、对业务的深度理解。Agent 可以起草草案,但签字的必须是人。
第二条:业务语义的裁定权不能让。“什么叫活跃用户""什么叫华北区""什么算异常”——这些定义在企业里永远有争议。争议的化解不是技术问题,是组织问题。Agent 没有资格裁定。它最多是在既定的语义下执行。
第三条:故障的归因与复盘不能让。当一条链路出问题、财报数字错了、监管被问询时,责任必须落在人身上。Agent 可以辅助排查,可以生成时间线,但归因报告的签名必须是人。这不是技术问题,是问责问题。法律上 Agent 也签不了。
底层逻辑这三条共同指向一个事实:需要承担后果的决策,不能交给不能承担后果的主体。
八、转型路线图:6-12 个月的学习路径
给已有 3-8 年经验的数据工程师,一个务实的转型建议。
节奏说明:大厂 vs 中小厂的两条时间线同一份路线图,在不同规模的公司里走的节奏不一样。别拿”应该”的节奏苛责自己。
大厂 / AI 进展激进的公司(12-18 个月窗口):平台已经有 MCP、Unity Catalog、内部语义层在推动,机会多、工具全、同事卷。这套 12 个月路线图基本贴合。窗口之所以紧是因为组织在变,不等你——看谁能第一批接上内部 AI 平台项目,第二批可能就只能跟随了。
中小厂 / 传统行业(2-3 年窗口):基础设施还停留在数仓 + BI 的阶段,MCP、语义层、Agent 这些概念离落地还远。这套路线图可以拉长到 2-3 年,而且前半年主要工作是”推动基础设施升级”而不是”学新技术”。
所以下面的月份是大厂节奏。如果你在中小厂,按 1.5-2 倍时间放大,然后把精力更多放在”争取一个试点项目”而不是”刷完所有工具”。
第 1-2 个月:补齐 Agent 基础
- 精读 AI Agent 智能体概述 和 AI 多 Agent 协作系统
- 跑通一个最小 Agent demo(LangGraph 或 OpenAI Agents SDK)
- 理解 Planner / Executor / Critic 的职责分工
第 3-4 个月:吃透 MCP 协议
- 完整走一遍 MCP 学习路线图
- 自己用 MCP Server 开发实践 给公司内部某个数据源包一个 MCP Server
- 理解 MCP 和传统 REST/RPC 的区别——核心是工具自描述和上下文协商
第 5-6 个月:切入语义层和数据产品
- 选一个语义层工具(dbt Semantic Layer 或 Cube)做 POC
- 把自己负责的某个业务域,按数据产品架构重新建模——写 Data Contract,定义 SLO
- 这一步很痛苦,因为你会发现以前建的宽表没一个配得上”产品”两个字
第 7-9 个月:建 Eval 体系
- 给你的 Agent 工作流建一套 golden dataset
- 学会用 Ragas、DeepEval 或自建 Eval 框架做回归
- 每次 Prompt/模型/工具链改动,都跑 Eval——Eval 跑不过不许上线
第 10-12 个月:做一个端到端落地
- 选一个真实业务场景(不要太大,建议是”某个报表的智能解读”或”某类告警的自动根因”)
- 端到端走一遍:意图 → 编排 → 产品 → 基础设施
- 量化业务价值:替代多少人工、提升多少时效、降低多少口径歧义
到这里你会发现,自己的简历已经不一样了。你不是”数据工程师”,你是Intent Architect。
九、写在最后:慢一点,但不要停
Agentic Data Engineering 不是风口,是基础设施迁移。风口三个月就换,基础设施十年起步。
所以不要焦虑地去追每一个新框架。2026 年冒出来的 Agent SDK 到 2028 年可能一半消失。但意图契约、数据产品、语义层、Eval 体系——这些底层判断不会变。
共勉数据工程师的黄金年代从来不在写管道的那十年。黄金年代一直都是你能不能在一团混乱的业务和一堆不可靠的数据之间,建立起清晰的秩序。过去这件事叫建数仓,现在叫建数据产品,明天叫设计意图契约。形式会变,手艺不变。
相关阅读
- 技术趋势导览
- 数据产品架构
- 数据开发智能化
- AI Agent 智能体概述
- Agentic-RAG 进阶架构
- Agentic-RAG 工程实战
- MCP 学习路线图
- 数据工具 MCP 集成实战
掌握检查
- 能说清楚传统数据管道为什么不适合 Agent 消费(至少三点)
- 能默画 Agentic Data Engineering 四层模型,并解释每一层的职责
- 能举一个例子说明”没有语义层的 Text-to-SQL 会如何翻车”
- 能说出数据工程师”三条不能让”的底线是哪三条
- 对自己未来 6-12 个月的学习路径有明确判断
实践练习
- 选一个你熟悉的业务域(订单、用户、营销均可),按数据产品契约的思路写出 2-3 个数据产品的 YAML 契约定义(包含 Owner、SLO、Schema、访问策略)。
- 用 LangGraph 或类似框架搭一个最小 Planner-Executor-Critic 三角 Agent,让它完成”查询某个指标并给出简单异常判断”的任务,跑通一次完整链路。
- 对照本文”五个反模式”,审视你当前团队的数据平台,写一份 2 页的风险评估——哪些反模式已经出现,哪些正在路上。


