本文来源于数据从业者全栈知识库,更多体系化内容请访问知识库。
Agent 可观测性三件套:Trace / Eval / Guardrail
前置知识阅读本文前,建议先了解:
- LLMOps 体系全景——理解 Agent 工程化的整体框架
- AI Agent 概述——理解 Agent 的结构与执行机制
- LLM 可观测性与监控——传统 LLM 监控的基础知识
2026 年,Atlan 在产品发布会上把 Agent Observability 列为与 DataOps 平级的新品类。这不是营销话术,是一个真实信号:可观测性已经从 LLM 层下沉到了 Agent 层,而这两者的复杂度完全不在同一个量级。
传统 APM 工具——Datadog、New Relic——你当然还需要,但它们只能告诉你”这次调用耗时 1.2 秒、成功返回”。Agent 的核心问题从来不是”有没有返回”,而是”返回的东西对不对”。这是一个质量问题,不是性能问题。APM 是必要不充分条件。
真正的 Agent 可观测性需要三件套:Trace(追踪)、Eval(评估)、Guardrail(护栏)。
目录
- #为什么传统 APM 不够用
- #三件套框架
- #Trace:Agent 的眼睛
- #Eval:Agent 的判断力
- #Guardrail:Agent 的刹车
- #三件套的协同关系
- #真实案例:客服 Agent 的可观测性实施
- #2026 工具全景图
- #落地 Roadmap
- #反模式:踩过的坑
- #为什么数据人最适合切这块
为什么传统 APM 不够用
一个电商客服 Agent 上线了。Datadog 显示:P99 延迟 2.1 秒,错误率 0.3%,吞吐量稳定。一切正常。
但三天后,客服主管打来电话:Agent 连续给用户推荐了已经下架的产品,还在退款政策问题上给出了错误金额。没有任何报警,没有任何异常日志。
这就是 APM 的盲区。它监控的是系统健康,Agent 失败的方式是语义错误——返回了错误的事实、错误的建议、错误的格式。这类问题在传统监控指标里完全隐形。
APM 告诉你”服务活着”,但 Agent 需要的是有人告诉你”服务说的对不对”。
三件套框架
Trace:Agent 的眼睛
Trace 解决的问题:一次 Agent 执行发生了什么。
一次完整的 Agent 执行不是一个黑盒,它是一条调用链:
用户查询 → Planner → Tool Call 1 → LLM Call → Tool Call 2 → Response每一步都有输入、输出、token 消耗、延迟。Trace 就是把这条链路完整记录下来,可回放、可分析、可对比。
Trace 应该记录什么:
| 维度 | 内容 |
|---|---|
| 输入/输出 | 每一步的原始 prompt 和 completion |
| Token 消耗 | 每次 LLM 调用的 input/output token,换算成成本 |
| 延迟分布 | 每一跳的耗时,识别瓶颈节点 |
| 工具调用 | Tool name、参数、返回值、是否成功 |
| 会话上下文 | session_id、user_id、对话轮次 |
| 元数据 | 模型版本、temperature、系统 prompt 版本 |
主流工具对比:
- LangSmith:LangChain 生态最成熟,UI 友好,适合快速落地
- Langfuse:开源,自部署友好,数据不出境首选
- Arize Phoenix:开源,对 Eval 集成最深,适合重度评估场景
- OpenTelemetry Gen AI:正在成为事实标准,厂商中立,长期押注的方向
标准化趋势OpenTelemetry Gen AI Semantic Conventions 在 2025 年底进入 Beta。未来 Trace 数据格式很可能走向统一,工具层在格式上的差异会收窄。现在做 Trace,建议用 OTEL 兼容的 SDK 封装,避免强绑定单一工具。
Trace 本质上是数据血缘的 Agent 版本——不是表和表之间的血缘,而是 prompt 和 completion 之间的血缘。如果你理解数据血缘追踪,Trace 的概念对你来说是降维的。
Eval:Agent 的判断力
Eval 解决的问题:Agent 说的对不对。
人工抽检在小规模验证阶段没问题。但 Agent 上线后,每天可能产生数千次对话。靠人工:覆盖率不够、成本太高、漂移检测有延迟。一个悄悄退化的模型,可能在两周后才被人发现。
需要一套自动化的 Eval 体系。
三层 Eval 架构:
第一层:Unit Eval(单步评估)
评估 Agent 执行链路中某一步的输出是否正确。例如:
- SQL 生成节点产出的 SQL 能否执行
- 意图识别节点判断的 intent 是否准确
- 工具选择节点选的 tool 是否合适
适合用确定性规则或小型分类器来做,速度快,成本低。
第二层:Trajectory Eval(轨迹评估)
评估整条执行链路的决策路径是否合理。例如:
- Agent 是否调用了多余的工具(效率问题)
- 工具调用顺序是否符合逻辑
- 是否出现了”幻觉跳步”——跳过必要的信息收集直接给结论
这层评估更难,需要有”标准轨迹”作为参照,或用 LLM-as-Judge 来打分。
第三层:E2E Eval(端到端评估)
评估最终响应对用户的实际价值:
- 回答是否准确
- 是否符合业务规则
- 语气和格式是否合规
LLM-as-Judge 的优势与陷阱:
用另一个 LLM 来评估目标 LLM 的输出,是目前最主流的自动化 Eval 方案。优势在于泛化能力强,能处理开放式问题。但有几个陷阱需要警惕:
- 位置偏差:Judge 模型倾向于给第一个选项打高分
- 冗长偏差:更长的回答容易得到更高评分,不管内容质量
- 自我偏好:用 GPT-4 评估 GPT-4 的输出,存在系统性偏见
缓解方案:多 Judge 模型投票、使用结构化评分维度而非整体打分、定期用人工标注校准。
Eval 数据集的建立与维护:
- 初始集:从历史日志中挑选代表性 case,覆盖主要场景和边界情况,200-500 条起步
- 黄金集:人工标注的高质量样本,用于校准自动化评分器
- 回归集:每次发现 Bad Case 后加入,防止同类问题复现
- 维护频率:每 2 周评估一次分布漂移,季度做一次全量更新
这套逻辑和LLM 评估体系的方法论完全一致,只是 Agent 的 Eval 需要额外处理多步骤轨迹这个维度。
Guardrail:Agent 的刹车
Guardrail 解决的问题:不该发生的事情不发生。
Eval 是事后的,Guardrail 是实时的。Eval 告诉你昨天有多少次回答质量差,Guardrail 在坏的回答发出去之前把它拦下来。
输入护栏:
- Prompt 注入检测:识别并拦截试图通过用户输入篡改系统 prompt 的攻击
- 越权查询检测:用户试图让 Agent 访问其无权访问的数据(例如让数据 Agent 查询其他用户的订单)
- 敏感话题过滤:根据业务场景屏蔽特定类型的问题(政治、竞品比较等)
输出护栏:
- PII 检测:防止 Agent 在输出中泄露身份证号、手机号、银行卡号等
- 事实性检查:对关键事实(价格、政策条款)做规则校验
- 格式合规:确保输出符合下游系统的格式要求
- 有害内容过滤:防止生成歧视性或不适当内容
主流工具:
| 工具 | 定位 | 特点 |
|---|---|---|
| NVIDIA NeMo Guardrails | 开源,企业级 | 声明式配置,支持自定义 rail |
| Guardrails AI | 开源 | Python 友好,Validator 生态丰富 |
| Lakera Guard | 商业 | Prompt 注入检测最强,API 即用 |
| Azure AI Content Safety | 云服务 | 与 Azure OpenAI 深度集成 |
护栏不是越严越好Guardrail 的误杀率(false positive)和漏过率(false negative)是两个需要同时监控的指标。过度严格的护栏会把正常的用户查询挡在门外,伤害用户体验。每条 guardrail 规则上线前都应该用历史数据评估误杀率,并设定可接受的阈值。
三件套的协同关系
三件套不是三个独立的工具,它们之间有清晰的数据流关系:
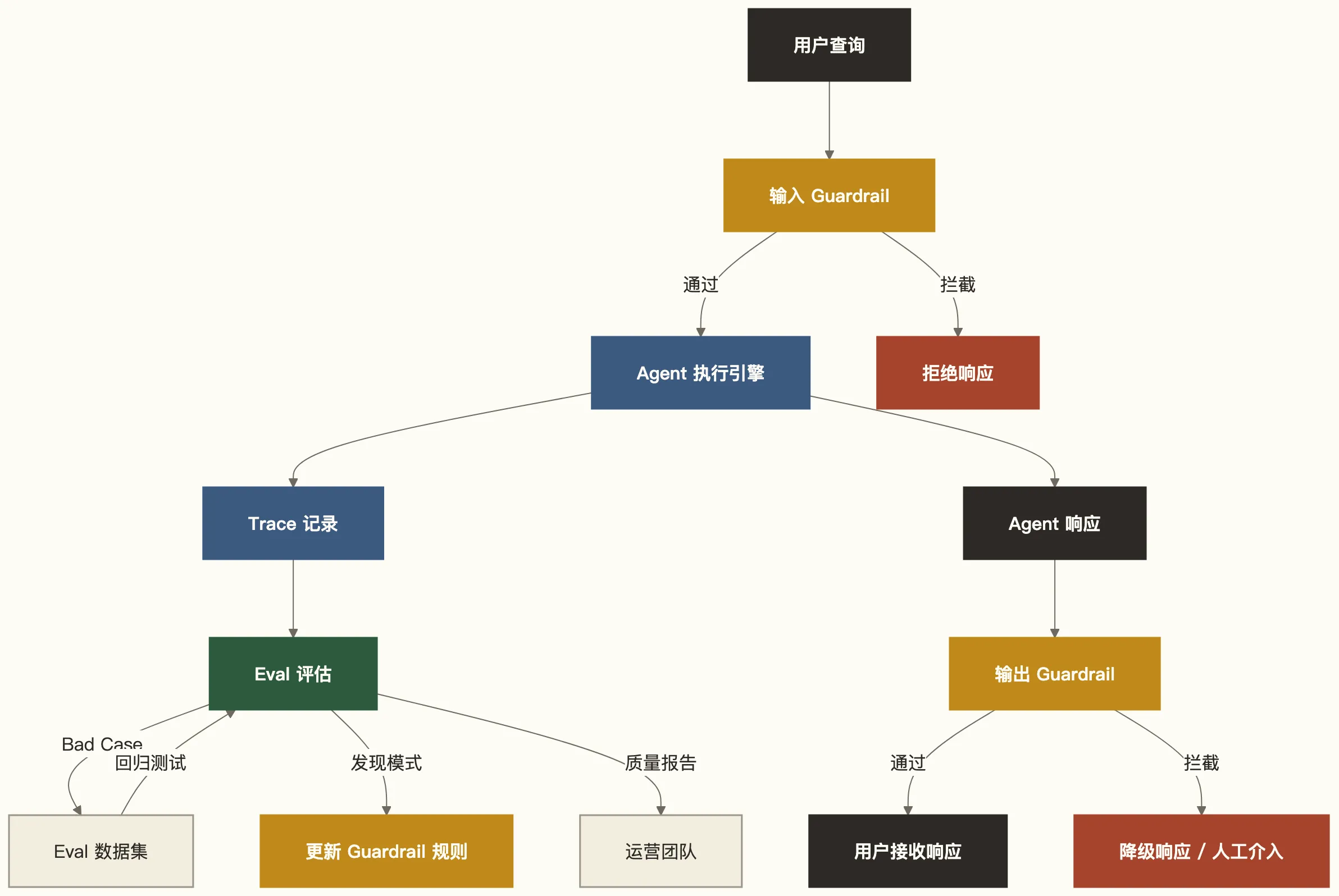
关系说明:
- Trace 是眼睛:记录一切,为 Eval 提供原材料,为调试提供回放能力
- Eval 是判断力:分析 Trace 数据,识别质量问题,驱动护栏规则的迭代
- Guardrail 是刹车:实时拦截,消费 Eval 的输出来持续优化规则
三者之间的核心数据流是:Trace 数据 → Eval 发现 Bad Case → 更新 Guardrail 规则。这是一个持续运转的闭环,不是一次性的配置。
真实案例:客服 Agent 的可观测性实施
以一个金融客服 Agent 为例,展示三件套从上线前到上线后的完整实施过程。
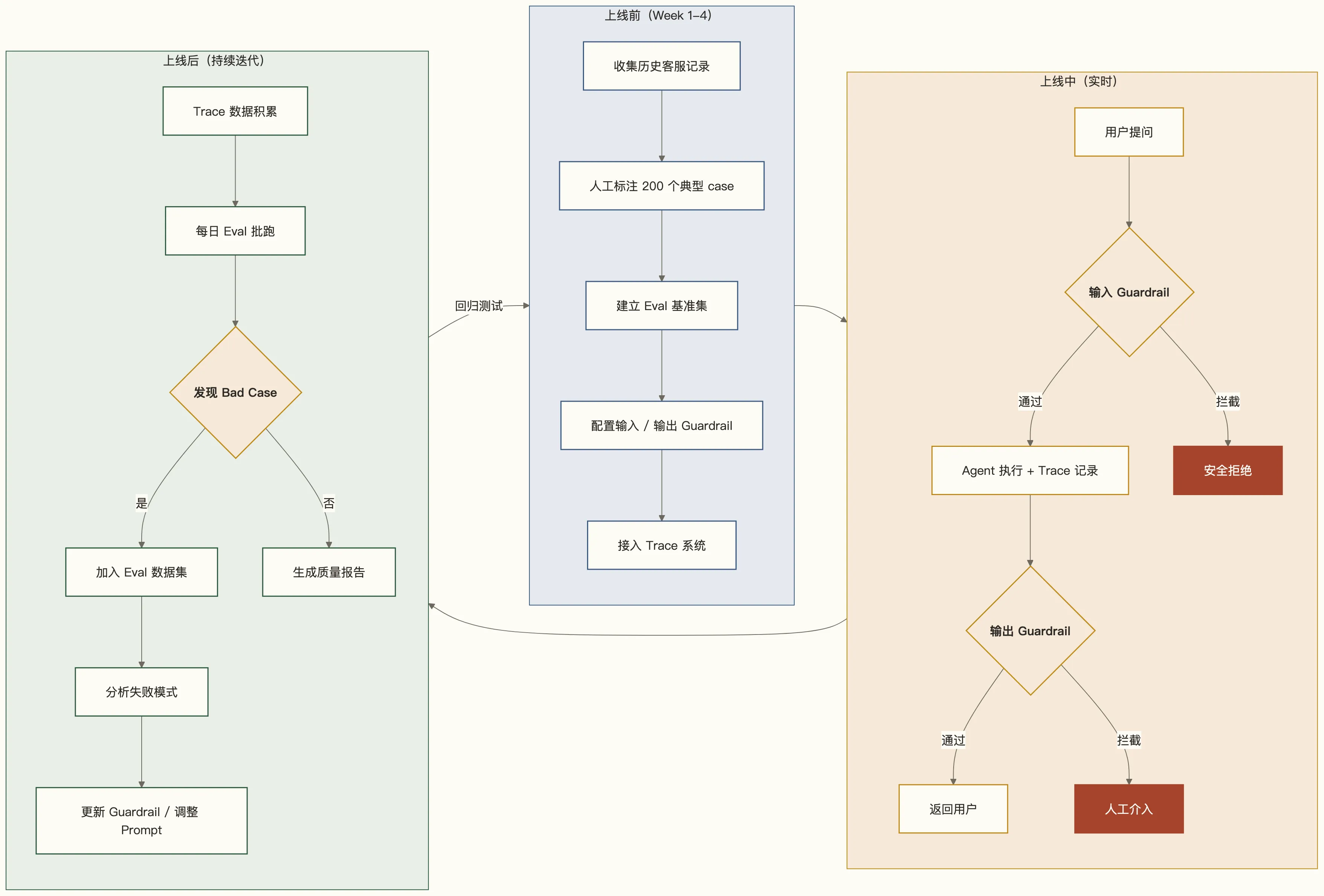
上线前两周:建立基准
从历史工单中挑选 200 个 case,覆盖:常见查询(余额、账单)60%,边界情况(异常退款、投诉)30%,恶意查询(Prompt 注入尝试)10%。人工标注正确答案和质量分。这 200 个 case 是后续所有 Eval 的基准线。
上线中:护栏发挥作用
第一周,Guardrail 的输入护栏拦截了 47 次越权查询(用户尝试通过自然语言查询他人账户)。输出护栏拦截了 12 次包含未脱敏手机号的响应。这些都没有触发任何 APM 告警——如果没有 Guardrail,这些问题会静默地发生。
上线后:Trace 发现问题,反哺 Eval
运行两周后,Eval 批跑发现一类 Bad Case:用户问”上个月账单”,Agent 频繁给出当前月账单。Trace 回放显示:Planner 节点在时间参数解析上存在歧义,“上个月”在某些上下文下被解析为”最近一个账单周期”。
这个 Bad Case 加入 Eval 集,触发了针对时间参数解析的专项 Unit Eval,同时新增了一条输出 Guardrail 规则(账单日期与查询日期偏差超过 40 天时触发人工复核)。
2026 工具全景图
| 工具 | 类型 | Trace | Eval | Guardrail | 部署形态 | 适用场景 |
|---|---|---|---|---|---|---|
| Langfuse | 开源 | ✅ | 基础 | ❌ | 自部署/云 | 数据不出境,预算有限 |
| Arize Phoenix | 开源 | ✅ | ✅ | ❌ | 自部署/云 | 重度 Eval 场景 |
| LangSmith | 商业 | ✅ | ✅ | 部分 | 云 | LangChain 生态,快速起步 |
| Arize(商业版) | 商业 | ✅ | ✅ | ✅ | 云/混合 | 企业全栈方案 |
| Datadog LLM Observability | 商业 | ✅ | 基础 | ❌ | 云 | 已有 Datadog 的团队 |
| NVIDIA NeMo Guardrails | 开源 | ❌ | ❌ | ✅ | 自部署 | 企业级 Guardrail 定制 |
| Lakera Guard | 商业 | ❌ | ❌ | ✅ | API | Prompt 注入防御专项 |
| Databricks Mosaic AI Eval | 平台自带 | 部分 | ✅ | ❌ | Databricks 内 | Databricks 用户 |
| Snowflake Cortex Playground | 平台自带 | 部分 | 基础 | ❌ | Snowflake 内 | Snowflake 用户 |
选型建议没有一个工具能覆盖三件套的全部能力。实际落地通常是组合方案:Trace 选一个(Langfuse 或 LangSmith),Eval 用 Phoenix 或平台自带,Guardrail 用 NeMo 或 Lakera。避免选择一个平台锁死全部需求。
落地 Roadmap
不要试图一次性把三件套全部上线。分阶段落地,每个阶段都有可交付的结果:
Week 1-2:接入 Trace
- 选定 Trace 工具(推荐从 Langfuse 开源版起步)
- 为 Agent 的每个关键节点添加埋点
- 确保每次 LLM 调用都被记录:输入 prompt、输出、token 消耗
- 验收标准:可以通过 session_id 回放任意一次完整对话
Week 3-4:建最小 Eval 集
- 从 Trace 数据中挑选 100 个有代表性的 case
- 人工标注”好/坏”和失败原因分类
- 跑通一次手动 Eval,确认评分维度和流程
- 验收标准:有一个可重复执行的 Eval 流程,产出质量报告
Month 2:加 Guardrail
- 根据 Eval 发现的问题模式,确定优先级最高的 3-5 条规则
- 上线输入护栏(Prompt 注入、越权查询)
- 上线输出护栏(PII、关键事实校验)
- 验收标准:Guardrail 每天产出拦截日志,误杀率 < 1%
Month 3+:持续联动
- 建立 Eval-Trace 联动的自动化流程:每天批跑 Eval,Bad Case 自动入库
- 每两周评审一次 Eval 数据集,补充新 case
- 每月评审一次 Guardrail 规则,根据误杀/漏过数据调整阈值
- 验收标准:Agent 质量有可量化的周环比趋势,而不是靠感觉
反模式:踩过的坑
只做 Trace,不做 Eval
看得见,判断不了。你知道 Agent 每次调用了哪些工具、用了多少 token,但不知道最终答案对不对。这是最常见的”半拉子工程”——团队觉得已经做了可观测性,实际上只做了 APM。
Eval 集从不更新
上线第一周花了两天建了 200 个 case,之后再也没动过。三个月后,Agent 已经在应对完全不同的用户提问模式,但 Eval 集还在评估三个月前的场景。Eval 集是活的,不是文物。
Guardrail 过度严格
某团队上线了一条输出护栏:任何包含数字的金额信息都需要人工审核。结果 70% 的正常回答被拦截,客服团队被淹没在人工复核请求里。护栏的目标是拦截异常,不是制造摩擦。误杀率必须是一等公民指标。
可观测性由应用团队自己搭
每个业务团队各自搭一套 Trace 和 Eval,工具不同、格式不同、标准不同。两个月后,没有人能在 Agent 之间做横向对比,也没有人能看到整体质量趋势。Agent Observability 应该是平台能力,由数据或基础设施团队统一建设,业务团队接入标准 SDK。这和LLMOps 平台化的逻辑完全一致。
把 Guardrail 当银弹
“我们上了 Guardrail,所以安全了”。Guardrail 是最后一道防线,不是唯一防线。它不能替代良好的系统 prompt 设计、权限控制、和 Eval 体系。护栏拦下的东西是症状,根治需要找到病因。
为什么数据人最适合切这块
这是 2026 年最值得数据人关注的职业方向之一。不是因为它时髦,而是因为数据人在这件事上有结构性优势。
三件套和数据人已有的知识体系存在直接映射:
| Agent 可观测性 | 数据领域对应概念 |
|---|---|
| Trace | 数据血缘——追踪数据从哪来、经过哪些处理、到哪里去 |
| Eval | 数据质量规则——定义什么是”好数据”,自动化检测和告警 |
| Guardrail | 数据访问控制——谁能看什么数据,敏感数据怎么脱敏处理 |
数据人理解数据管道,Agent 可观测性是 prompt/completion 管道。数据人理解数据质量,Eval 是 Agent 输出的质量。数据人理解数据治理,Guardrail 是 Agent 行为的治理。
这不是勉强的类比,是真实的方法论迁移。你已经知道怎么建数据质量规则、怎么做数据血缘、怎么做数据访问控制。把这套经验迁移到 Agent 域,学习曲线比应用工程师或 ML 工程师都要短。
更重要的是,Agent 的业务价值评估——它到底有没有帮助用户解决问题——本质上是一个数据分析问题。Eval 结果的解读、质量趋势的分析、不同 Agent 版本的 A/B 测试,都是数据人的本行。
结合AI Lineage 血缘 2.0的实践经验和MCP Gateway 生产部署的工程视角,数据人在 Agent 可观测性这个领域的竞争壁垒,比大多数人意识到的要高得多。
掌握检查
- 能解释为什么 APM 对 Agent 来说是必要不充分条件
- 能描述 Trace、Eval、Guardrail 各自解决的核心问题
- 能说出三层 Eval 架构(Unit、Trajectory、E2E)的适用场景差异
- 能说出 LLM-as-Judge 的两个主要偏差及缓解方法
- 能识别”只做 Trace 不做 Eval”这个最常见的反模式
实践练习
基础练习:为你熟悉的任意一个业务场景(推荐用电商、客服或数据查询),设计一个最小可行的 Eval 集。至少包含 5 个 case,每个 case 注明:用户输入、期望输出、评估维度(准确性/格式/合规性)。
进阶练习:选择 Langfuse(开源自部署)或 LangSmith(云端免费额度),为一个简单的 LangChain Agent 接入 Trace。能在 UI 中回放一次完整的对话调用链,截图为证。
思考题:如果你是一家数据中台团队的负责人,你会如何说服业务团队把 Agent 可观测性的基础设施建设预算放在平台层而不是各业务线自建?写出 3 条核心论据。
下一步
- 深入学习自动化评估方法论:LLM 评估体系
- 了解 Agent 工程化的整体框架:LLMOps 体系全景
- 生产环境 Agent 部署与网关:MCP Gateway 与生产部署
- 数据血缘在 AI 场景的延伸:AI Lineage 血缘 2.0