
本文来源于数据从业者全栈知识库,更多体系化内容请访问知识库。
Iceberg V3 深度解析:为 AI workload 重新设计的表格式
前置知识
- 湖仓一体架构基础:理解表格式在整体架构中的位置
- Hudi 概述:有对比视角,选型时更清晰
- Paimon 概述:了解流批一体表格式的另一条路
- Agentic Data Engineering 方法论:理解 AI 工程对数据基础设施的新需求
2026 年 4 月 6 日,Dremio 宣布 Iceberg V3 在其云服务上正式可用。这个日期值得记一下,不是因为 Dremio,而是因为这意味着 V3 从规范走向生产。
很多人把 V3 理解成 V2 的”小升级”——加了几个数据类型,改了几个内部结构。这个理解是错的。V3 是一次有明确方向的重新设计:它的设计目标不再只是”让 BI 查询更快”,而是”让 AI workload 能用上表格式的所有好处”。
这两件事对表格式的要求完全不同。
1. V2 的局限:为什么 AI 时代需要 V3
V2 在 BI 场景下表现很好。ACID 事务、时间旅行、Schema Evolution——这些能力对数仓迁移和报表系统来说已经够用了。
但 AI workload 带来了三个 V2 没有认真对待过的需求。
需求一:多模态数据类型
AI 应用的数据不只是整型、字符串、浮点数。一个 RAG 系统的文档库需要存文档元数据(嵌套 JSON)、向量索引状态(半结构化)、地理标注(坐标+多边形)。V2 的数据类型系统没有半结构化类型,遇到 JSON 要么 CAST 成字符串丢掉结构,要么在应用层自己解析。两种做法都是绕路。
需求二:高频 Schema Evolution
模型迭代速度比业务迭代快得多。特征工程版本更新意味着特征表的列要频繁增减,而且不同版本的特征可能需要同时存在(A/B 实验)。V2 的 Schema Evolution 支持加列、改列名,但默认值只能在写入时解决——如果历史数据很大,加一列就要么重写所有文件,要么接受 NULL 值语义的歧义。
需求三:高并发不可预测查询
BI 查询的模式相对固定,可以通过分区策略和物化视图预优化。AI 推理和训练的数据访问模式完全不可预测——增量训练要抓某个时间窗口内变化的行,特征回填要按样本 ID 点查,Embedding 更新要识别哪些行改动过。V2 的删除机制(Position Delete Files + Equality Delete Files)在这类随机写、频繁小批量更新的场景下性能很差,Compaction 压力极大。
这三个问题不是调参能解决的,需要在规范层做结构性改变。V3 做了。
2. V3 的四个核心变化
2.1 新数据类型
V3 引入了四个新类型,每个都针对具体场景:
Variant(半结构化类型)
这是变化最大的一个。Variant 是一种列内嵌套的动态类型,可以存储任意 JSON/半结构化内容,但与直接存字符串不同——Variant 在物理层有结构感知的编码,查询引擎可以利用 shredding 技术直接下推谓词到嵌套字段,不需要全列扫描再应用层解析。
-- V3 中可以直接对 Variant 列的嵌套字段做谓词下推SELECT doc_id, metadata:embedding_model, metadata:chunk_sizeFROM rag_documentsWHERE metadata:language = 'zh-CN' AND metadata:token_count > 500;对比 V2 的做法——metadata 只能是 string 类型,上面的查询要全表扫描 + 应用层解析 JSON,性能差一到两个数量级。
Geospatial(地理空间类型)
原生支持 Point、LineString、Polygon 等几何类型,并在元数据层携带边界框(Bounding Box)信息用于空间裁剪。对 LBS 数据平台、地图 AI 应用意义明显。
纳秒时间戳(timestamp_ns / timestamptz_ns)
V2 的时间戳精度到微秒。AI 推理日志、高频交易特征、流式事件通常需要纳秒级精度。V3 补上了这个精度层级。
unknown 类型
表示”类型待定”的占位符,主要用于 Schema Evolution 中的向前兼容场景。写入方可以先声明列存在,类型后续确认。
2.2 Row Lineage(行级血缘)
这是 V3 最有工程含义的变化,值得单独讲(下一节详述)。
每一行数据在写入时自动携带两个系统列:
_row_id:全局唯一的行标识符,跨快照不变_last_updated_sequence_number:最后一次更新该行的操作序号
这两列不需要用户声明,由引擎在写入时自动维护。
2.3 Deletion Vector 升级
V2 的删除机制有两种:Position Delete Files(按文件+行号记录哪行被删了)和 Equality Delete Files(按某个列值标记删除)。两种方式在读取时都需要 merge-on-read——读文件的同时读 delete 文件,实时合并过滤。数据更新频率高时,delete 文件积累很快,查询性能下降明显,Compaction 必须频繁运行。
V3 引入位图式删除向量(Deletion Vector):每个数据文件对应一个 Roaring Bitmap 文件,记录该文件中哪些行被标记删除。读取时只需扫描 bitmap,跳过对应行,不需要 merge 两个文件集合。
效果:
- 小批量高频更新(流式写入、CDC 接入)的写放大显著降低
- 读取时的 I/O 减少:bitmap 文件远小于 delete files
- Compaction 频率可以大幅降低,因为单次累积的”脏数据”代价更小
对特征平台和实时数仓场景,这个变化直接影响系统设计——V2 时代需要精心设计 Compaction 策略,V3 之后这个负担轻了很多。
2.4 Default Values 的 Metadata 层声明
V2 加列时,历史数据文件里没有这一列。查询返回 NULL 是正确的 SQL 语义,但问题在于:NULL 到底是”这行在这列上确实是空”,还是”这列不存在于历史文件中”?两种含义在业务上完全不同。
V3 允许在 Schema 的列定义里直接声明 default_value,这个信息存在 Metadata 里,不需要重写历史数据文件。查询引擎遇到历史文件里缺失的列,返回 Schema 声明的默认值,而不是 NULL。
{ "id": 5, "name": "feature_version", "type": "int", "required": false, "default-value": 1}Schema Evolution 的语义清晰度大幅提升,这对多版本特征共存的场景非常实用。
3. Row Lineage 为什么对 AI 是”游戏规则改变”
先把问题说清楚:AI 工程里有一类高频操作叫”增量处理”。你的训练数据、特征数据、文档库不是静态的,它在持续变化。每次数据变化,下游的 AI 任务——模型训练、Embedding 计算、向量索引更新——只需要处理变化的那部分,不需要全量重跑。
问题是,“哪些行变了”这件事,在 V2 里没有行级答案。Iceberg 快照可以告诉你两个时间点之间哪些文件被增删,但文件粒度太粗——一个 128MB 的 Parquet 文件可能只有 10 行改动,你必须读整个文件再自己做 diff。
V3 的 _row_id 和 _last_updated_sequence_number 把答案精确到行。
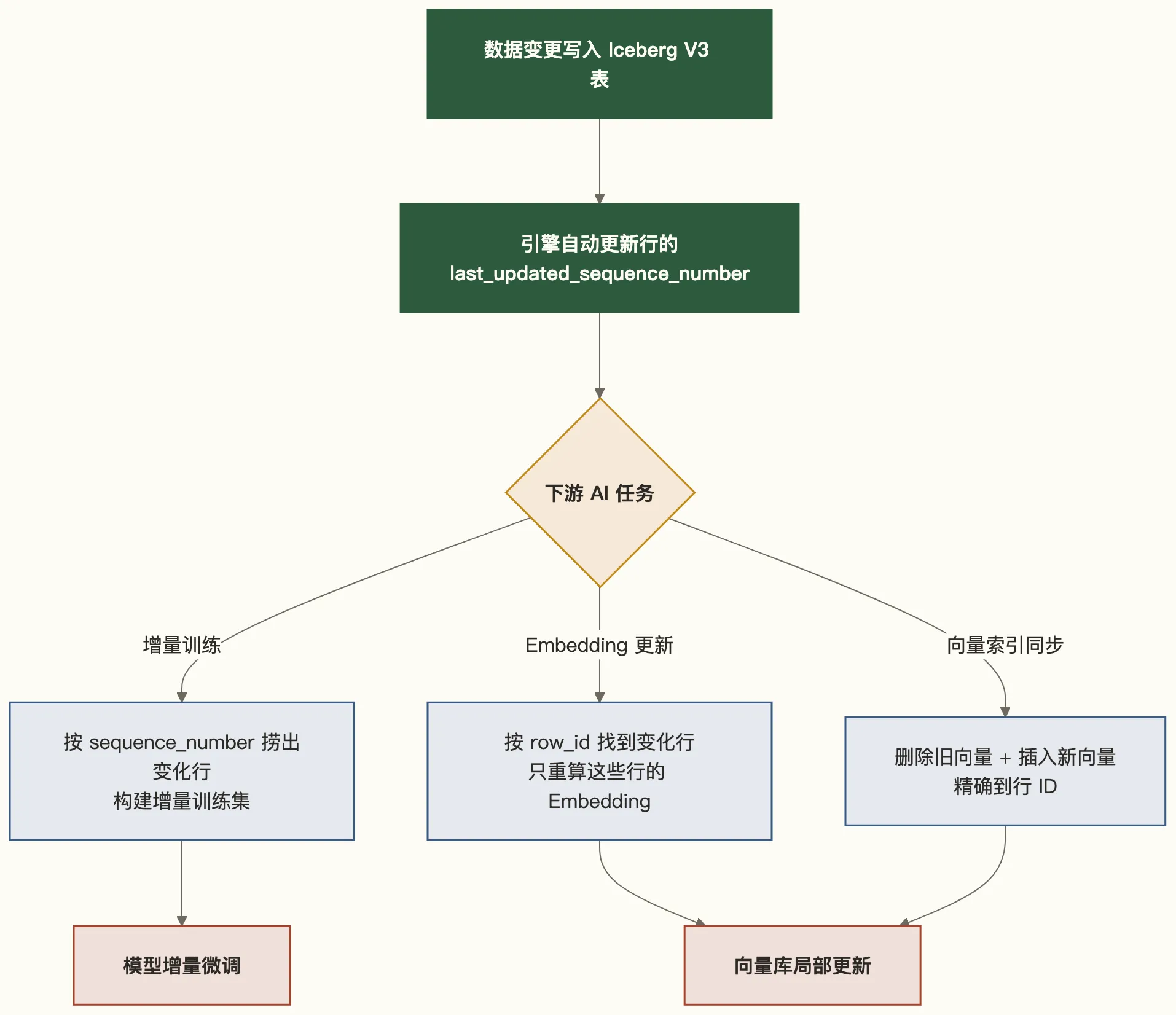
场景一:增量训练样本的精准捕获
模型每日增量微调(Continual Learning)需要当天新增或修改的样本。V3 之前的做法:用事件日志或 CDC 工具在数据管道里额外维护一份变更记录,增加系统复杂度。V3 之后:直接查询 _last_updated_sequence_number > last_training_checkpoint 的行,数据湖本身就是变更的权威来源。
场景二:Embedding 增量重算
RAG 系统的文档库如果有文档更新,对应的 Embedding 必须重算,否则向量检索结果是过期的。V3 的 _row_id 提供了稳定的跨版本行标识——同一文档在多次更新后 _row_id 不变,可以精确找到”这篇文档的 Embedding 记录”然后替换,而不是全量重建向量库。
场景三:数据漂移检测的新基础设施
模型监控里有一个重要任务:检测训练数据分布是否漂移。V3 之前需要额外的监控系统来追踪”哪些行在什么时候被修改成什么值”。Row Lineage 让 Iceberg 表本身就携带了这个历史信息,数据漂移检测可以直接建立在表格式的原生能力上,不需要另起一套基础设施。
4. 横向对比:2026 年表格式格局
| 能力维度 | Iceberg V3 | Iceberg V2 | Hudi (0.14+) | Paimon (1.0+) |
|---|---|---|---|---|
| 半结构化类型 | Variant(原生) | 无(存字符串绕路) | 无原生 Variant | 无原生 Variant |
| 行级血缘 | _row_id + sequence_number | 无 | Record Key(写入时声明) | 主键变更追踪(有限) |
| 删除向量 | Roaring Bitmap DV | Position/Equality Delete Files | MOR + COW 两模式 | LSM-Tree 式合并 |
| AI 原生能力 | Row Lineage 支持增量 AI 管道 | 弱,依赖外部 CDC | 中,Record Key 可追踪 | 中,Changelog 模式 |
| Schema 默认值 | Metadata 层声明,无需重写 | 需写入时处理 | 支持部分默认值 | 支持 |
| 生态成熟度 | 高(Spark/Flink/Trino/Dremio) | 高 | 高(Spark 侧强) | 中高(Flink 侧强) |
| 向量原生支持 | 无(LanceDB 仍占位) | 无 | 无 | 无 |
| Catalog 标准 | REST Catalog 优先 | Hive/REST | Hive 为主 | Hive/REST |
选型判断
- 以 BI 查询为主、团队已有 Iceberg V2:渐进迁移到 V3,不急
- 新建 AI 数据基础设施:V3 是首选,Row Lineage 和 Variant 是真实差异
- 流批一体、Flink 为主:Paimon 仍有优势,V3 在流场景的生态还在完善
- Spark 生态重度用户、需要 Upsert 的 CDC 场景:Hudi 仍然成熟
5. 生产落地的三个真实场景
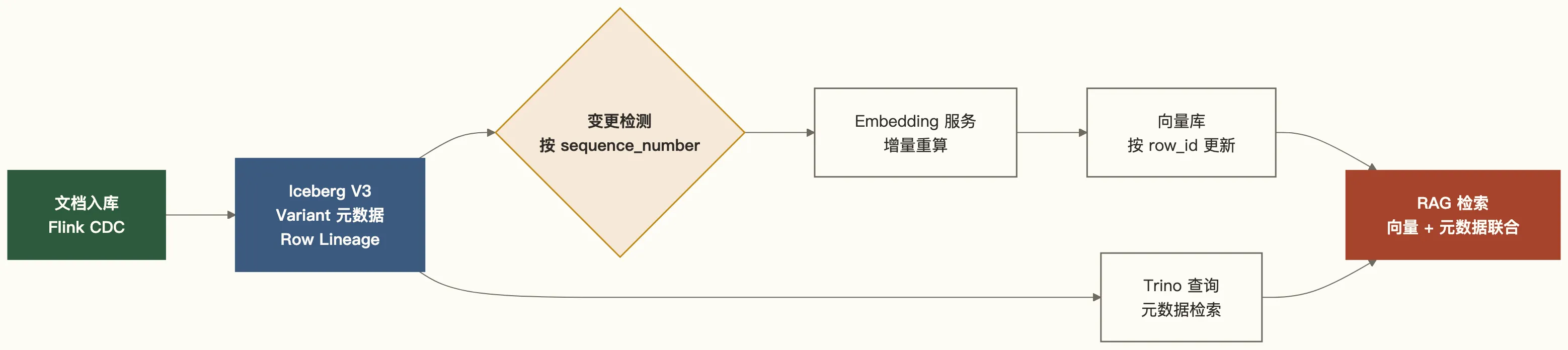
场景 A:RAG 系统的文档库
需求:存储企业知识库文档,支持频繁更新(文档版本迭代),同时维护文档的 Embedding 和多模态元数据(图片引用、表格结构、语言标注)。
V3 的价值:
Variant类型存储每篇文档的元数据(chunk_strategy、embedding_model、语言、图片引用列表),不需要预先固化 schema_row_id作为 Embedding 向量库的外键,文档更新时精准触发 Embedding 重算- Deletion Vector 支持文档下线(标记删除)而不立即触发文件重写,读取性能不受影响
-- 查询近 24 小时内更新的文档,触发增量 Embedding 重算SELECT doc_id, _row_id, title, metadata:chunk_strategyFROM knowledge_base_docsWHERE _last_updated_sequence_number > ( SELECT MAX(processed_sequence) FROM embedding_sync_checkpoint);架构示意:
场景 B:实时特征平台的高频更新
需求:用户行为特征每分钟更新,特征表有数十亿行,需要支持点查(按 user_id)、批量训练读取、实时在线服务(低延迟)。
V3 的价值:
V2 时代这个场景的痛点是 Delete Files 积累导致的读放大。实际生产中见过这样的情况:一个特征表每天 Compaction 任务跑 4 小时,但表的写入速度让 Compaction 永远追不上,最终查询性能退化到不可用,被迫切回 HBase。
V3 的 Deletion Vector 显著降低写放大,同一更新量下 Compaction 频率可降低 60%-70%(Dremio 内测数据)。配合 _row_id 实现精准点查:
-- 按 user_id 批量点查最新特征(覆盖写场景)SELECT user_id, feature_vec, feature_versionFROM user_featuresWHERE user_id IN (/* 当前 batch 的 user_id 列表 */) AND _last_updated_sequence_number = ( SELECT MAX(_last_updated_sequence_number) FROM user_features f2 WHERE f2.user_id = user_features.user_id );场景 C:数据合约 + AI 血缘
需求:企业要求每个 AI 模型的训练样本可溯源——哪个模型版本用了哪批数据,数据从哪里来,是否经过脱敏处理。
V3 的价值:Row Lineage 作为 AI 血缘(AI Lineage)的数据底座。
传统数据血缘追踪到表级或分区级,对 AI 监管要求来说粒度不够——监管方要求知道”这个模型的预测是否基于了不合规的个人数据”,表级血缘无法回答。
V3 的 _row_id 是行级的稳定标识,结合模型训练记录里保存的”训练批次 → 行 ID 集合”的映射,可以实现完整的行级 AI 血缘:
模型 v2.3.1 的训练集 └─ Iceberg 表: user_events, snapshot_id: 8827163 └─ 行 ID 范围: [uuid-001..uuid-89999](通过 sequence_number 捞取) └─ 原始数据来源: CDC from MySQL orders_v3 └─ 脱敏处理: mask_pii job, run_id: 2026-03-15-001这套链路建立在 Iceberg V3 的原生能力上,不需要另立一套血缘系统。关联 MCP Gateway 可以进一步把这套血缘暴露为 AI Agent 可查询的工具接口。
6. 从 V2 迁移到 V3:10 件要注意的事
迁移前必读V2 到 V3 不是原地升级,是格式版本升级。部分引擎对 V3 的支持仍在完善中,迁移前务必逐项确认。
- 引擎版本确认:Spark 3.5+、Flink 1.19+、Trino 440+ 才有完整 V3 支持。低版本引擎读 V3 表会报错或静默丢失新特性。
- Catalog 版本:Hive Metastore 不支持 V3 部分 Metadata 字段,需要切换到 REST Catalog(如 Nessie、Unity Catalog、Polaris)。
- 格式升级命令:使用
ALTER TABLE ... SET TBLPROPERTIES ('format-version'='3')升级,升级前做全量快照备份。 - Deletion Vector 兼容:升级后新写入会产生 DV 格式的删除文件,老版本读引擎无法识别。混合读写窗口期内不能有 V2 引擎的写操作。
- Row Lineage 激活:需要显式开启
'write.row-id.enabled'='true',默认不启用(避免存储开销)。历史数据不会回填_row_id,只有升级后写入的数据才有。 - Variant 类型迁移:原先存储为
string的 JSON 列不会自动转换为 Variant,需要重写对应列(ALTER TABLE ... ALTER COLUMN ... TYPE variant)并做数据迁移。 - Compaction 策略调整:DV 模式下 Compaction 触发阈值需要重新标定,原先基于 Delete Files 数量的触发条件不再适用。
- 监控指标更新:原来监控 Delete Files 积累量的告警需要替换为 DV 膨胀率监控。
- 读写并发测试:升级期间做灰度验证,先在非关键表上验证新旧引擎的并发读写行为,确认没有脏读。
- 备份策略:V3 格式的 Metadata 文件结构有变化,确认现有备份工具(如快照导出脚本)已适配 V3。
7. V3 没有解决的问题
说完优点,要说清楚边界。V3 很重要,但它不是万能的。
跨表事务依然困难
V3 解决了单表的 ACID,但多表原子写入(比如同时更新特征表 A 和模型状态表 B)仍然没有原生支持。需要依赖 Catalog 层的事务能力(Nessie 的 Branch & Merge)或外部协调机制。这是整个 Iceberg 生态的历史欠债,不是 V3 专门能解决的。
多模态二进制大对象的存储效率
Variant 类型很好,但它存的还是”结构化的半结构化数据”——JSON、坐标这类。图像、视频、音频这类真正的二进制大对象(Binary Large Object),V3 没有给出存储优化方案。生产上这类数据还是存 S3 对象,Iceberg 表里存引用 URL。存储效率和检索效率都有明显天花板。
向量原生支持还没进来
这是对 AI 场景影响最大的缺失。V3 有 Row Lineage,可以知道”哪些行的 Embedding 需要更新”,但 Embedding 本身——高维向量列的存储、ANN 索引的管理——V3 里没有。LanceDB 这类向量数据库仍然占据这块生态位,Iceberg 表和向量库之间需要额外的同步机制。
Iceberg 社区在讨论 Native Vector Column 类型,但 2026 年还没进规范。在这个问题解决之前,RAG 系统 的向量存储部分仍然需要专门的向量数据库来承担。
掌握检查
- 能解释 Variant 类型和存 JSON 字符串的本质区别(不只是”更方便”)
- 理解 Row Lineage 的两个系统列分别记录什么,以及为什么历史数据没有这两列
- 能描述 Deletion Vector 和 Position Delete Files 的物理差异,以及为什么前者读性能更好
- 知道 V3 迁移时 Catalog 替换的原因(Hive Metastore 的限制在哪里)
- 对 V3 的三个局限(跨表事务、二进制大对象、向量支持)能各举一个受影响的实际场景
实践练习
基础题:设计一个 RAG 文档库的 Iceberg V3 表 Schema,要求:支持存储文档元数据(语言、分块策略、来源系统)、支持通过 Row Lineage 触发 Embedding 增量更新、支持文档软删除。写出建表 DDL(Spark SQL 语法)。
进阶题:你的团队有一张 Iceberg V2 的用户行为特征表,每天更新量约 5 亿行,当前 Compaction 任务每 6 小时运行一次,仍跟不上 Delete Files 积累速度。请制定迁移到 V3 的方案,包括:灰度策略、引擎版本检查清单、Compaction 策略调整方案、监控指标替换计划。预估迁移后 Compaction 频率可以降低到多少,理由是什么。
下一步
- 横向对比:Hudi 架构与核心特性 — 理解另一条路的设计权衡
- 生态深挖:Paimon 架构原理 — LSM-Tree 式表格式的设计哲学
- 架构视角:湖仓一体架构设计 — 表格式在整体数据架构中的定位
- AI 方向:Agentic Data Engineering 方法论 — AI 工程如何重新定义数据基础设施的需求


