
我前几天写过一篇关于 DeepSeek V4 切换决策的文章,里面留了一个没回答的问题——如果模型本身越来越便宜,那么”会用模型”这件事的具体能力清单到底是什么?
这一篇就是想把这个问题拆开。
模型层在变商品是事实。今年 DeepSeek V4 把价格打到 Claude 的 1/7,明年大概率还有人把它打到再 1/7。模型本身的差异化在以肉眼可见的速度抹平,这意味着——会调 API 不再是稀缺技能,能让 API 给你跑出真东西才是。
下面这 5 种能力,是我观察过去一年那些把 AI 真做出价值的人身上的共同特征。它们的共性是——AI 越普及,它们越值钱。
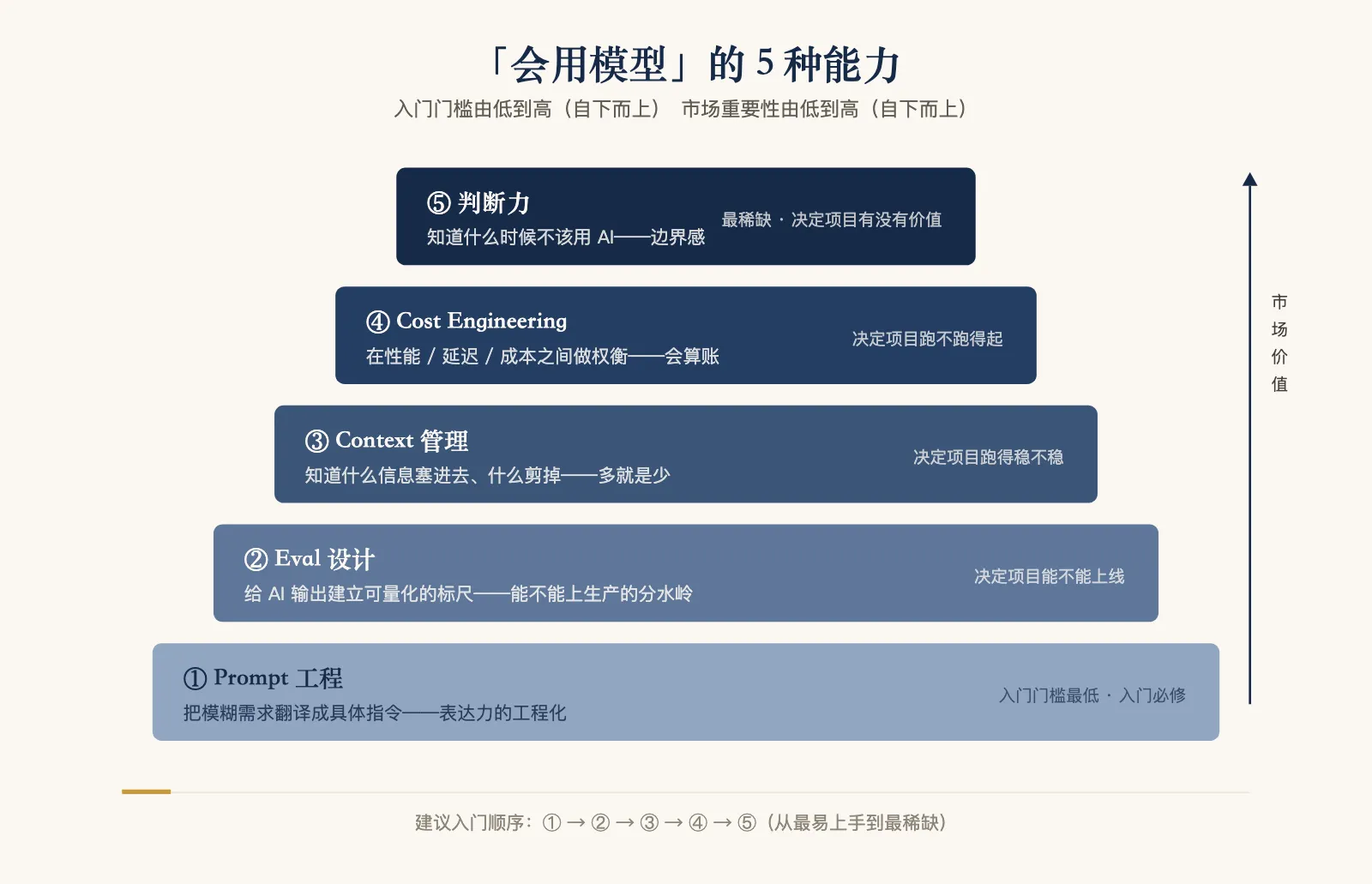
能力一:Prompt 工程——把模糊需求翻译成具体指令
很多人对 prompt 工程的印象还停留在两年前——“加上’你是一位专家’就能让模型表现更好”那种小聪明。这种”魔法咒语”已经被淘汰了。
今天的 prompt 工程是另一回事。它的核心是——把你脑子里那个模糊的”我想要什么”,翻译成一段可执行、可复用、可调试的具体指令。
举一个真实场景。一个 PM 问:“帮我看看上周用户活跃度怎么样”。
新手写的 prompt 大概是这样:
“请分析上周用户活跃数据并给出洞察”
老手的 prompt 长这样:
“我有一份 events 表,schema 是 [user_id, event_name, ts, properties_json]。请给我写一段 SQL,统计上周(4/22-4/28)相比上上周(4/15-4/21)的:1) DAU 变化;2) 新增用户占比;3) 单用户平均事件数。如果某项变化超过 ±10%,标注’值得关注’。输出 SQL + 一段 100 字的解读。别加任何 SQL 之外的说明、别假设字段不存在的情况——schema 就是我说的这些。”
差别不在”咒语”,在表达力。老手知道自己想要什么,新手不知道。
怎么练?三个具体动作:
- 每次和 AI 对话之前,先用 30 秒想清楚”我想要什么”——具体到字段、格式、口径、长度。不要把这一步交给 AI 猜
- 看自己写过的 prompt,挑出那些 AI 没给你想要的结果的,分析是哪一步表达模糊。这是最直接的训练
- 把好用的 prompt 模板存下来——比如”代码 review 模板""分析报告模板""会议纪要模板”。形成自己的 prompt 库,不要每次重新发明轮子
Prompt 工程的本质,和写文档、写需求、跟外包沟通是同一种能力——精确表达。这个能力 AI 时代之前就有人强、有人弱,只是 AI 时代它变得更值钱了。
能力二:Eval 设计——给 AI 输出建立可量化的标尺
如果说 prompt 工程是”让 AI 知道你想要什么”,那 eval 设计就是”让你知道 AI 做得对不对”。
这是绝大多数 AI 项目失败的真实原因——不是模型不行,是没人能客观判断”这次输出比上次好还是坏”。
举个例子。你给一家电商公司搭了一个客服 Agent,老板问”它表现怎么样?“。你怎么回答?
- 没有 eval 的人:凭感觉,“挺好的,看了几个对话感觉还行”
- 有 eval 的人:抽 200 条真实对话,按 4 个维度打分(问题理解 / 回答准确性 / 语气适当性 / 是否升级到人工),算分布、看趋势、对比上周
这两种人在公司里的命运完全不同。前者每次老板问就慌,后者每次都能拿出数字说话。在 AI 时代,有 eval 体系的人,是真正能把项目推到生产的人。
eval 设计不是统计学博士的活,是个工程化的练习。具体三步:
- 建一个”金标准集” (golden set)——找 50-100 个有代表性的真实输入,人工标注最理想的输出。这 50 条是你的”考卷答案”
- 定义打分维度——是 0/1 binary 还是 1-5 分制?是单维度还是多维度?关键是可重复——不同的人评同一条,分数不能差太多
- 跑回归测试——每次 prompt 改了、模型换了、context 调了,用同一份金标准集跑一次。没有 eval 的”优化”都是赌博
eval 这个能力之所以稀缺,是因为它反人性——它要求你承认自己可能错。建 eval 等于公开承认”我说不清这事好不好,我需要数据来验证”。很多人不愿意做这件事,因为它意味着自己的判断要被检验。
但就是这种”愿意被检验”的人,最后做出了真东西。
能力三:Context 管理——知道什么信息该塞进去
LLM 的 context window 越来越大——DeepSeek V4 默认 1M,Claude 也支持几十万。但这不意味着你应该把所有东西都扔进去。
Context 管理是 AI 时代最被低估的工程能力之一。它的核心是回答两个问题:
- “模型现在需要哪些信息才能完成这个任务?”
- “哪些信息塞进去反而会让它分心、跑偏、或浪费 token?”
举个反例。我见过有人做 RAG 系统,把文档切块切到几千个 chunk,每次查询召回 top-50,全部塞进 prompt。结果——模型大部分时间在”读”无关材料,对问题的实际理解反而下降。换成 top-5 + 更精准的召回,效果直接提升 40%。
多就是少。这是 context 管理的第一原则。
具体怎么练?
- 每次构造 prompt 之前,问自己”这段信息和任务直接相关吗?” 如果答不上”是”,就剪掉
- 学几个具体技巧——summarization(长文档先总结再传)、reranking(粗召回后精排序)、windowing(只看最近 N 条历史)。这些技术细节有没有不重要,重要的是知道这些选项存在,能在需要时用
- 观察你的 token 账单——如果每次调用都在 100k token 以上但效果还不好,几乎肯定是 context 没管好
Context 管理的延伸版本,在多 Agent 系统里就是”协作记忆设计”——上一期周刊讲过的 Slack 那个 Director’s Journal 就是这种能力的高阶应用。
能力四:Cost Engineering——在性能和成本之间做最优权衡
这是上一期周刊 《Agent 落地的账本》 讲过的——Agent 落地走过”能跑”和”能稳定跑”,进入了”能便宜跑”的阶段。
会算账的人,正在变得稀缺。
Cost engineering 不是”找最便宜的模型”那么简单。它是一整套在质量、延迟、成本三者之间做权衡的系统能力。具体包括:
- 路由策略:简单查询用便宜模型,复杂查询用贵模型——一个 token 都不浪费
- 缓存策略:相同/相似的查询走缓存,避免重复推理
- 截断策略:什么时候应该 early stop,避免 AI 在不必要的细节里燃烧 token
- 批处理:能不能把 N 个独立查询合并成一个长 prompt,省 system prompt 的开销
- fallback 设计:主模型挂了或贵了切到备用,保证可用性
这套能力的本质是工程权衡——不是技术问题,是产品 + 商业 + 工程的复合判断。
怎么练?最直接的方式——给自己跑的所有 AI 系统建一个”成本仪表盘”:每天调用量、单次成本、月度账单。看着数字思考:
- 哪一类调用占了 80% 的成本?
- 这一类里有多少是”其实不需要这么贵”的?
- 如果换便宜模型,质量会掉多少?掉多少是可接受的?
没有这个仪表盘,你做的每个决定都是凭感觉。
能力五:判断力——知道什么时候不该用 AI
最后这条,可能是 5 种里最值钱、也最稀缺的——判断什么时候不该用 AI。
听起来反直觉。这一行是 AI 工程师,怎么能”不用 AI”?
但你看那些把 AI 真做好的团队,往往有一个共同特征——他们对”该用 AI”和”不该用 AI”的边界有清晰的判断。
哪些场景应该用 AI?
- 答案空间大、规则不可枚举(比如”帮我读这份合同找出风险点”)
- 容错率高,错了不致命(比如内容草稿、初步分类、辅助决策)
- 个性化要求高,规则写不全(比如”根据这个用户的历史给推荐”)
哪些场景不应该用 AI?
- 答案空间小、规则可枚举(比如”判断这个邮箱格式合不合法”——一个正则就解决,不需要 LLM)
- 容错率低、错了致命(金融转账、医疗诊断的关键决策、合规判定)
- 可重复性要求高(同一个 input 必须每次返回完全一样的 output——LLM 天然做不到)
判断力的本质是知道工具的边界。不知道边界的人,会把所有问题都套上 LLM——结果是又贵又不稳。
怎么练?只有一个办法——多见、多踩坑、多复盘。判断力没有教程,是在真实业务里摔出来的。一个具体动作是——每次决定上 AI 之前,强迫自己写下”为什么不能用规则解决”。如果写不出有说服力的理由,就别用 AI。
5 种能力的优先级
如果你时间有限,下面是我建议的投入顺序:
- 优先 Prompt 工程(最基础,回报最快)
- 同时练 Eval 设计(决定你能不能把项目推到生产)
- 然后是 Context 管理(决定项目运行得稳不稳)
- 再后是 Cost Engineering(决定项目跑不跑得起)
- 最后是判断力(决定你做出来的项目有没有价值)
注意这是”投入顺序”,不是”重要性顺序”。重要性反过来——判断力 > 成本意识 > 上下文 > eval > prompt。但学习时入门门槛最低的是 prompt,所以从 prompt 开始最有正反馈。
这 5 种能力放在一起,本质是一个数据从业者从”会调 API”到”能做出真东西”的进阶路线。它们和具体模型无关——你今天用 Claude,明天换 V4,后年用我们还没听过的模型,这 5 种能力都跟着你走。
收束
如果让我给这件事做一句话的收束:模型在变商品,“会用”是越来越稀缺的护城河——而”会用”是这 5 种能力的复合。
说到这里我自己一直在琢磨一件事——这 5 种能力之间到底是什么关系?哪些是底层能力、哪些是衍生?如果让我画一张能力进阶图给数据从业者看,会是什么样? 这是我最近一直在梳理的,有想法的朋友可以加我微信(shisuidata)一起聊。
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些观察——我觉得值得说出来的那部分。
拾穗数据|https://ss-data.cc


