
两年前我跟人吹牛说”我用的是 Claude”,去年我跟人吹牛说”我自己跑模型”,到了今年——再说自己用什么模型,已经变成一件容易翻车的事。
因为 4 月 24 号,DeepSeek 把 V4 扔出来了。
它到底干了什么
简单说三件事。
第一,价格打到了 Claude 的 1/7 量级。据多家分析媒体报道(Office Chai 等),DeepSeek V4-Pro 每百万 output token 收 $3.48 量级,对标 Claude Opus 4.6 的 $25——这不是促销,是定价。下面这张是 DeepSeek 官方公布的价格表:
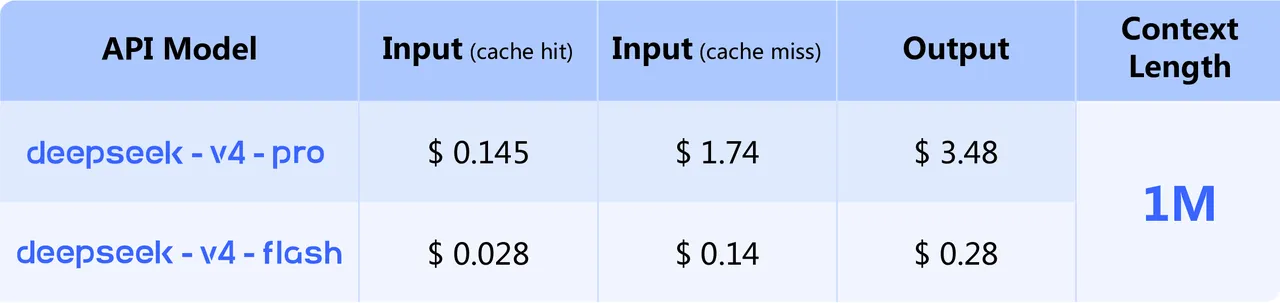
第二,benchmark 把闭源拉到了同一条起跑线。Hugging Face 上 V4-Pro 模型卡公布的核心成绩:LiveCodeBench 93.5、Terminal Bench 2.0 67.9、SWE-bench Verified 80.6、GSM8K 92.6、MMLU-Pro 87.5、GPQA Diamond 90.1(来源)。在编码和数学这两个最受关注的方向,已经压到 Claude Opus 4.6、GPT-5.4 这一档。
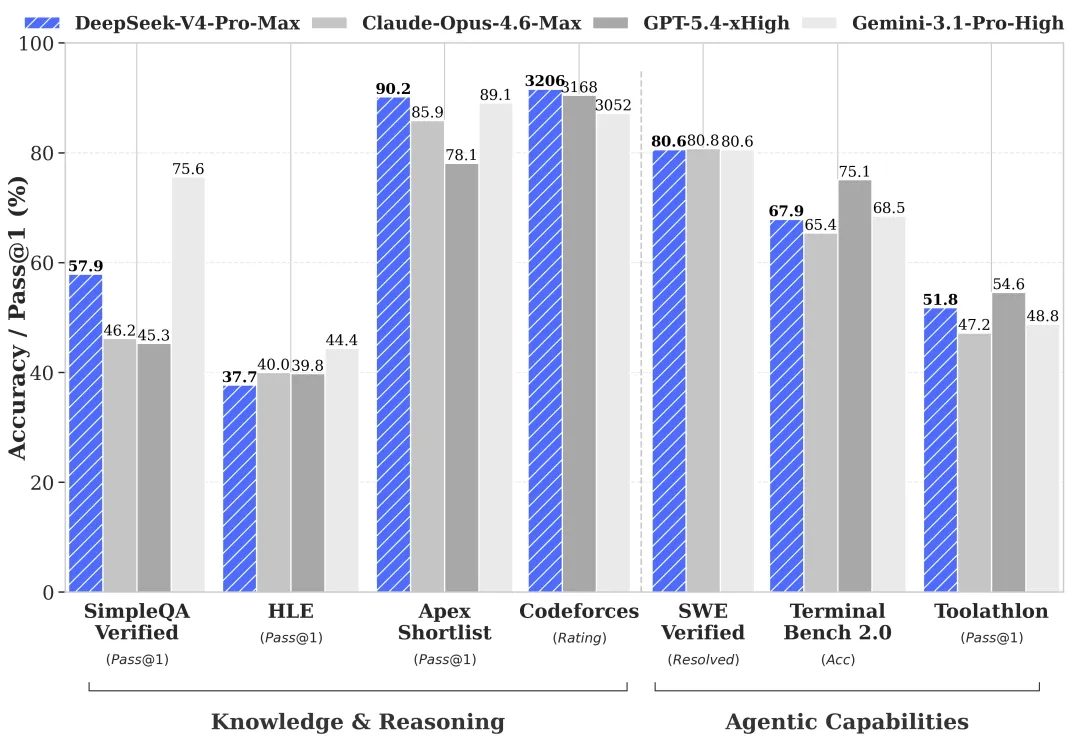
第三,1M 上下文成默认 + MoE 架构带来效率优势。V4-Pro 是一个 1.6T 总参数、49B 激活参数的混合专家(MoE)模型,FP4 + FP8 混合精度训练。DeepSeek 官方公告里特别强调:“1M context is now the default across all official DeepSeek services”——长上下文不是付费选项,是默认设置(来源)。
外加一件事:MIT License 开源,权重可以从 Hugging Face 直接拉——发布一个月,下载量 7.8 万,超过 2.6k Likes。
如果你不在 AI 圈,可能感受不到这事的分量。我打个比方——这就像你正在订一年期 $25 一杯的咖啡套餐,喝得也挺香,突然路口开了一家 $3.5 的店,咖啡豆是同一个产地、烘焙师还略好。你下一步会怎么做?
按理说会切。但实际上很多人不会立刻切。
不会立刻切的人有几种
第一种,已经有上线产品的人。Prompt 调了三个月、客户合同里写了”使用 Claude 系列”、内部审计已经过了,这种情况下你说”换个模型省 80% 成本”,没人敢拍板。每个生产系统都积累了模型特异性的隐性资产——同一段 prompt 在 Claude 上稳跑,换到 V4 上结果可能漂移 5%;这 5% 在测试集上看不出来,在真实流量里就是客户投诉。
第二种,重度依赖 Claude / GPT 工具链的人。比如你深度用了 Claude 的 Artifacts、Computer Use,或者 OpenAI 的 Assistants API、Realtime Voice。这些不是模型本身,是模型公司搭的产品工具。开源模型至今没有完全对齐的产品形态——你换到 V4,理论上模型够用,但整个开发体验会回退几个月。
第三种,给客户做 to B 项目的人。客户的 IT 部门在乎”我们用的是 Anthropic”或者”我们用的是 OpenAI”——这是品牌信任度的问题,不是技术问题。你跟他们说”换 DeepSeek 能省 80%“,对方可能还觉得这是合规风险(中国公司、数据出境、监管不确定)。这个心理门槛不是性能能解决的。
第四种,懒得动的人。这才是真正的多数派。工具链一旦稳定,切换的痛苦就会被高估——明明换一下也就半天的事,但你就是不想动。这是人性,不是技术问题。
那哪些人会立刻切
个人开发者会切。一个人在做 side project,每月 OpenAI 账单 $200,切到 V4 变成 $30——这种节省直接进自己腰包,决策成本为零。
预算紧的小团队会切。融资还没到、用户量已经在涨的初创,本来就在用各种降本招数——切模型这种”决策只要一个人点头”的事,是他们最容易做的。
做内部工具的工程师会切。比如你给公司内部搭了一个”问数据”的 Agent,老板每月看到 $8000 的 API 账单皱一次眉,你切到 V4 立刻变成 $1100——皱眉变成微笑。这种场景没有客户合同、没有品牌焦虑、没有合规审查。
做 prototype 验证的人会切。早期试错阶段,模型差异 5% 根本不重要,速度和成本才重要。
我自己的观察:这一波切换,会让”个人 / 小团队 / 内部工具”和”大公司 / to B / 长期产品”之间的差距继续拉大——前者享受到了完整红利,后者在惯性里继续付溢价。
切的”隐性成本”到底有哪些
如果你打算切,下面这些坑要提前想到。
Prompt 不通用。我自己测过——同一段在 Claude 上稳定输出 JSON 的 prompt,换到 DeepSeek 上有时候会多输出几个解释段落。不是模型不会,是它的”对齐口味”不一样。所有 prompt 都要重新调,预估时间是项目工期的 10%-20%。
评估集要重跑。你之前在 Claude 上验证过的回归测试集,必须在新模型上完整跑一遍——而且不只是看 accuracy,要看输出格式、长度、措辞稳定性、边界 case 处理。这一步省不掉,不然上线就是赌博。
生态工具的差距。Claude / GPT 这一年沉淀了大量周边——LangChain 集成、observability 工具、prompt 管理平台、各家 IDE 插件——多数都对 DeepSeek 不一定原生支持,要么自己 patch,要么等社区。
可用性 SLA。商用 API 看的是 99.99% 这种数字。DeepSeek 作为新晋商用 API,过去几次大流量事件下偶有不稳。如果你跑的是关键路径,至少配一个 fallback——主用 V4,备用 Claude,账单会比纯 Claude 低很多,可用性比纯 V4 高一截。
数据出境合规。这个是中国市场特有的关注点。DeepSeek 是国内公司,数据流向、法务条款都和 Anthropic / OpenAI 不一样。to B 客户、金融医疗类应用,要走自己的合规审查。
把这些算进来,“切到 V4”不是免费的——但对很多场景,付一次性的迁移成本,换长期 80% 的运营节省,账还是划算的。
一个简单的决策框架
我自己最近在用的判断框架是这样——把场景按两个维度拆:用户量 / 上线压力(纵轴)和 客户敏感度 / 合规要求(横轴)。四个象限分别有不同的处置策略:
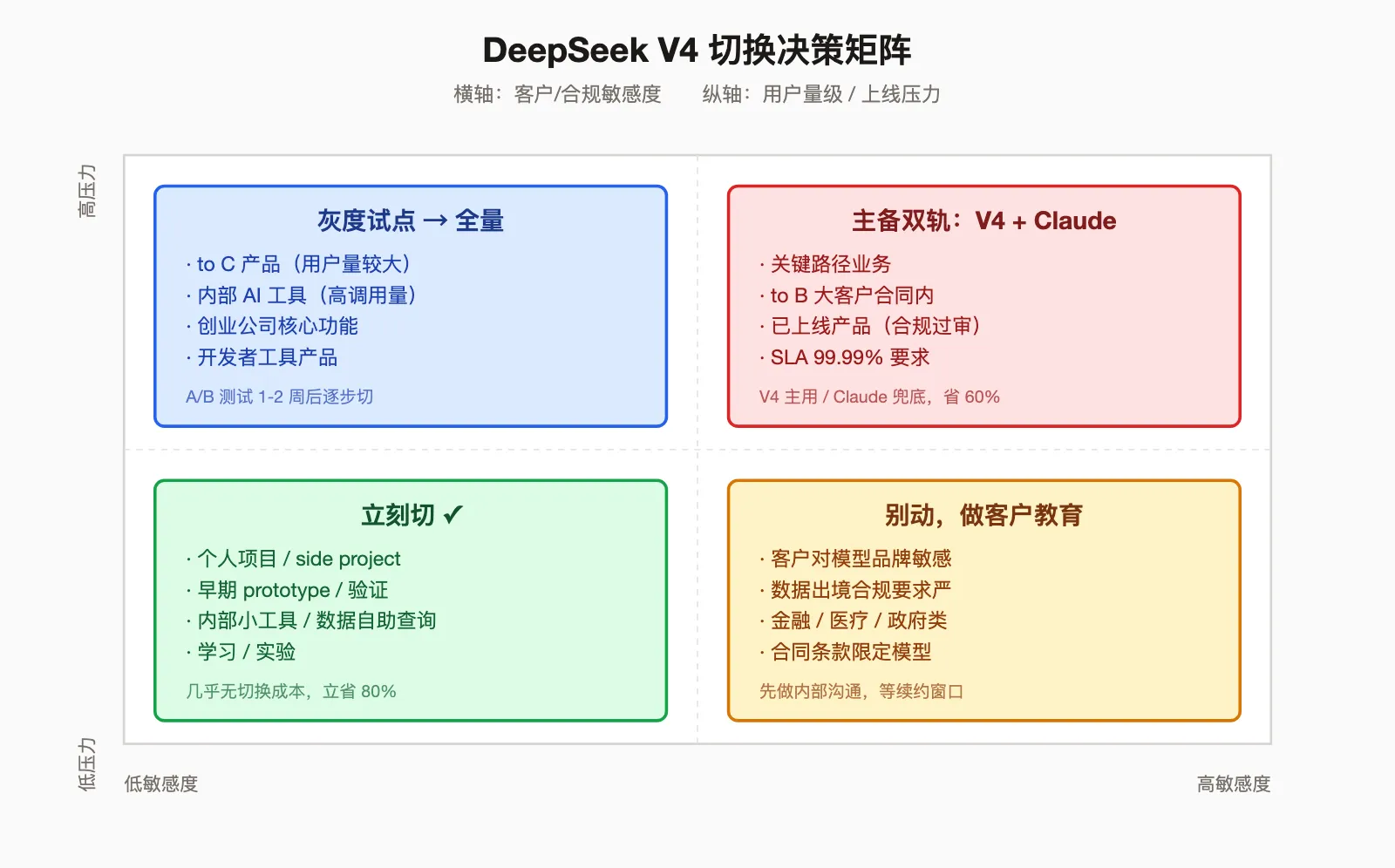
具体到几种典型场景:
| 你的场景 | 建议 |
|---|---|
| 个人项目 / side project | 立刻切,没什么好犹豫的 |
| 小团队内部工具 / 数据自助查询 | 优先切,几天 ROI |
| 早期 prototype / 验证 | 直接用 V4,闭源版本试都不用试 |
| 已上线 to C 产品(用户量 < 10 万) | A/B 测试一段时间再决定 |
| 已上线 to B 产品(有合同条款) | 保持现状,但开始评估为下次合同续约时切换做准备 |
| 关键路径 / 金融医疗 | 配 fallback,主备不要押在同一家 |
| 客户对模型品牌敏感 | 别动,先做客户教育 |
这个表不严谨,但它的核心逻辑是——切换决策不是看谁的 benchmark 高,而是看你这个场景能不能承受切换的隐性成本。
一点更长远的判断
V4 这件事让我想起一件更早的事——2010 年前后 MySQL 把商用数据库的市场啃下来一大半的过程。当年 Oracle 不是技术不行,是定价模型出了问题——一边是免费、社区活跃、性能不差的 MySQL,一边是单实例授权费十几万的 Oracle。技术决策被价格决策碾过了。
LLM 圈可能正在重演这个剧本。闭源模型的护城河,本来是”性能 + 工具链 + 品牌”三件套。前两年护城河看起来很深——开源模型 benchmark 落后 6-12 个月,工具链根本不能比。但 V4 这一手,把 benchmark 差距压缩到了 0-3 个月,把价格差距拉开到了 5-7 倍。
这不是单点的发布,是供给侧的格局变化。
闭源模型公司接下来必须做选择:要么跟着降价(毛利掉一截),要么拼工具链护城河(但工具链开源也在追),要么走更高端市场(GPT-5.4 / Opus 4.6 这种,但市场会缩)。这是一个典型的”低端市场被颠覆,高端市场被挤压”的场景。
对数据从业者个人来说,这意味着两件事。
第一,学习投入要重新分配。过去你可能花大量时间研究 Claude 的工具用法、OpenAI 的 Assistants 怎么调——这些”模型特异性技巧”的保质期在变短。真正保值的是”模型无关”的能力:怎么写好 prompt、怎么搭 RAG、怎么做 eval、怎么管上下文。换哪家都用得上。
第二,对工具的态度要更松。两年前我们说”绑定 Claude 全家桶”是技术选型,现在看可能是个负担。模型层正在变成商品,下面的真正壁垒是你的数据、流程、判断力——这些和模型无关,但决定你能不能做出独特的产品。
如果让我给这件事做一句话的收束:模型在变便宜,能力的护城河会从”用什么模型”挪到”怎么用模型”。
说到这里我自己一直在琢磨一件事——如果模型本身越来越便宜,那么”会用模型”这件事的具体能力清单到底是什么? prompt 工程?eval 设计?上下文管理?还是更上层的判断力?这是我最近想画一张图的事,有想法的朋友可以加我微信(shisuidata)一起聊。
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些观察——我觉得值得说出来的那部分。
数据来源:
- DeepSeek V4 官方发布公告(api-docs.deepseek.com)
- DeepSeek-V4-Pro 模型卡(Hugging Face)
- Benchmark 综合分析(Analytics India Magazine、Build Fast With AI)
- 价格对比信息(Office Chai)
拾穗数据|https://ss-data.cc


