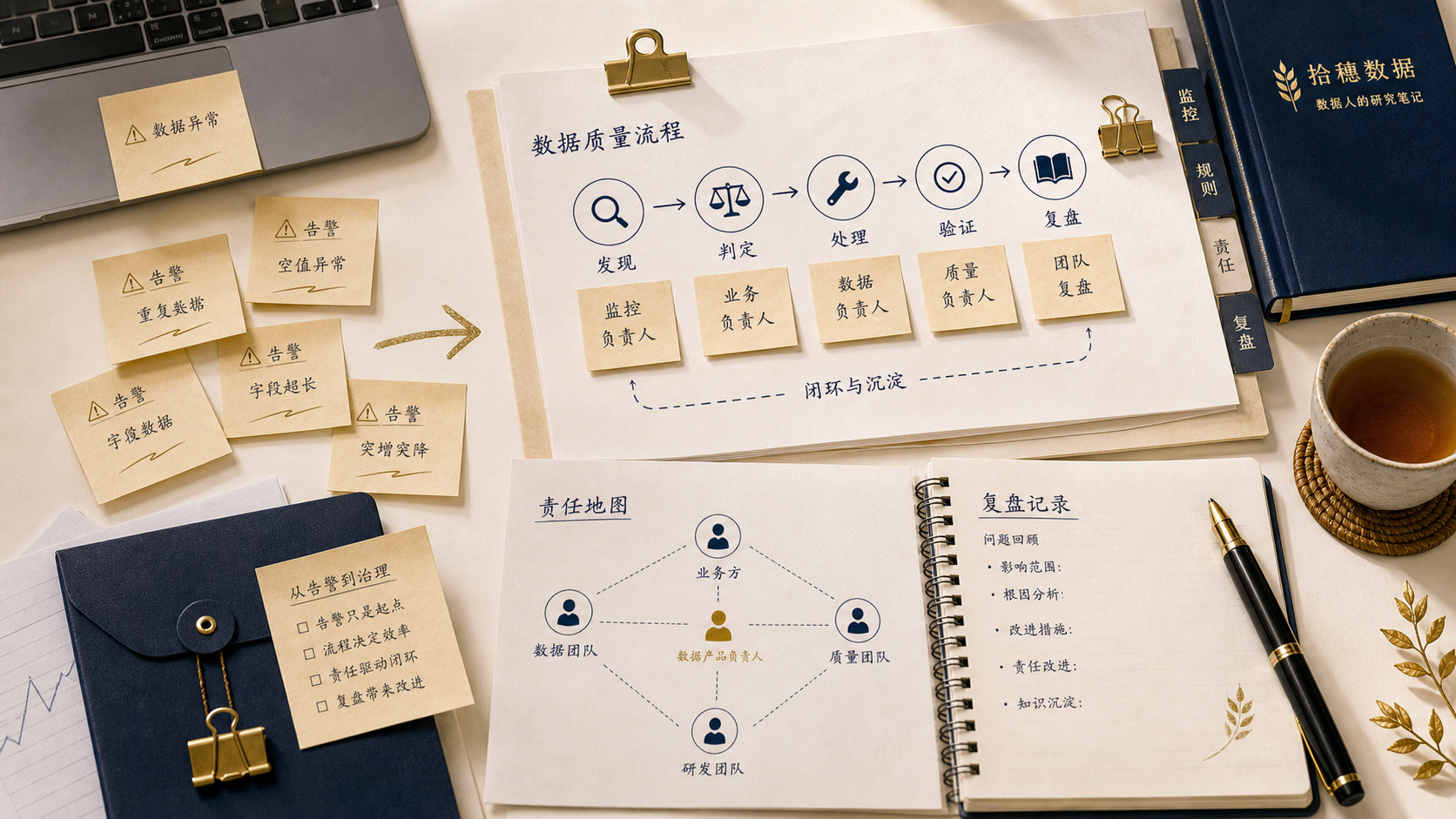
数据质量问题出现时,很多团队的第一反应是加告警。
空值多了,加一个空值率告警。行数波动了,加一个同比环比告警。任务延迟了,加一个 SLA 告警。指标口径变了,加一个异常监控。告警越来越多,群消息越来越吵,最后大家开始静音。
告警不是没用。没有监控,数据问题只能等业务投诉。
但如果数据质量只靠告警,治理一定会变成救火。
因为告警只能告诉你“出事了”,不能自动回答“为什么会出事、谁负责、下次怎么避免”。真正有效的数据质量治理,不是把更多规则塞进监控系统,而是把责任放进流程里。
告警多,不代表质量好
很多团队会用告警数量衡量质量建设:我们有多少条规则,覆盖多少张表,监控多少指标。
这些数字有价值,但不能说明质量真的好。
如果告警经常误报,大家会忽略。如果告警没人响应,规则再多也只是摆设。如果告警只告诉你任务失败,却没人知道影响哪些看板和会议,它就很难进入优先级。如果告警修完之后没有复盘,下次还会以类似方式发生。

数据质量治理最怕“看起来有系统,实际上没责任”。
系统能发现问题,但组织要解决问题。
质量问题要按影响分级
不是所有数据质量问题都一样。
一张实验表延迟半小时,和经营会核心指标延迟半小时,不是同一级别。一个低频字段空值率上升,和支付金额字段异常,也不是同一级别。
如果所有告警都用同样方式推送,团队迟早会麻木。
质量分级应该至少考虑三件事:下游影响、业务时效、指标重要性。
下游影响是看这张表或字段被哪些任务、看板、报告使用。业务时效是看问题是否会影响当天决策。指标重要性是看它是否属于核心经营口径。
高影响、高时效、核心指标的问题,需要立即响应。低影响、低时效、非核心字段,可以进入排期治理。
分级的目的,不是忽略小问题,而是让团队把注意力放在真正会伤害业务信任的地方。


