
有一类需求,数据团队听到之后会本能地紧张。
领导在会上说:“今年公司要重视数据资产,你们先把数据资产盘一下。”
这句话听起来不复杂。甚至很像一个标准数据治理动作:拉表清单,补字段说明,填负责人,做一个目录。
但做过的人都知道,如果第一步就从“盘表”开始,这件事很容易走偏。
最后你会得到一个很大的 Excel:几千张表,几十个字段,若干责任人,一堆“待确认”。表格越填越厚,业务越看越困,领导问“这些资产到底有什么用”时,会议室会短暂安静。
数据资产不是表名清单。
一张表能不能叫资产,不取决于它有没有被登记,而取决于它能不能在某个真实场景里被持续使用,有没有人负责,质量是否可信,出了问题能不能追得回,能不能给业务、AI 或管理动作带来结果。
所以公司开始提“数据资产”时,数据团队第一件事不是盘全量表,而是先找真实场景。
先把“资产”从口号里拿出来
“资产”这个词很容易让人误会。
一旦叫资产,大家就会想到盘点、估值、入表、目录、权属、责任人。于是项目还没开始,就已经变成一个庞大的管理动作。
管理动作不是不重要,但如果没有使用场景托底,它会变得很空。
我更愿意把数据资产先理解成一句朴素的话:
一份能被反复使用、能解决具体问题、有人维护、可以被信任的数据供给。
这句话里有四个关键词。
第一,反复使用。一次性临时取数不一定是资产,但如果同类需求反复出现,就有资产化的可能。
第二,具体问题。没有问题的数据只是存量,不是资产。
第三,有人维护。没人负责的数据,迟早会变成没人敢用的数据。
第四,可以信任。质量、口径、权限、血缘不清楚,再有价值也很难规模化使用。
所以不要一上来问“我们有多少张表”。
先问:公司现在有哪些问题,值得用数据长期解决?
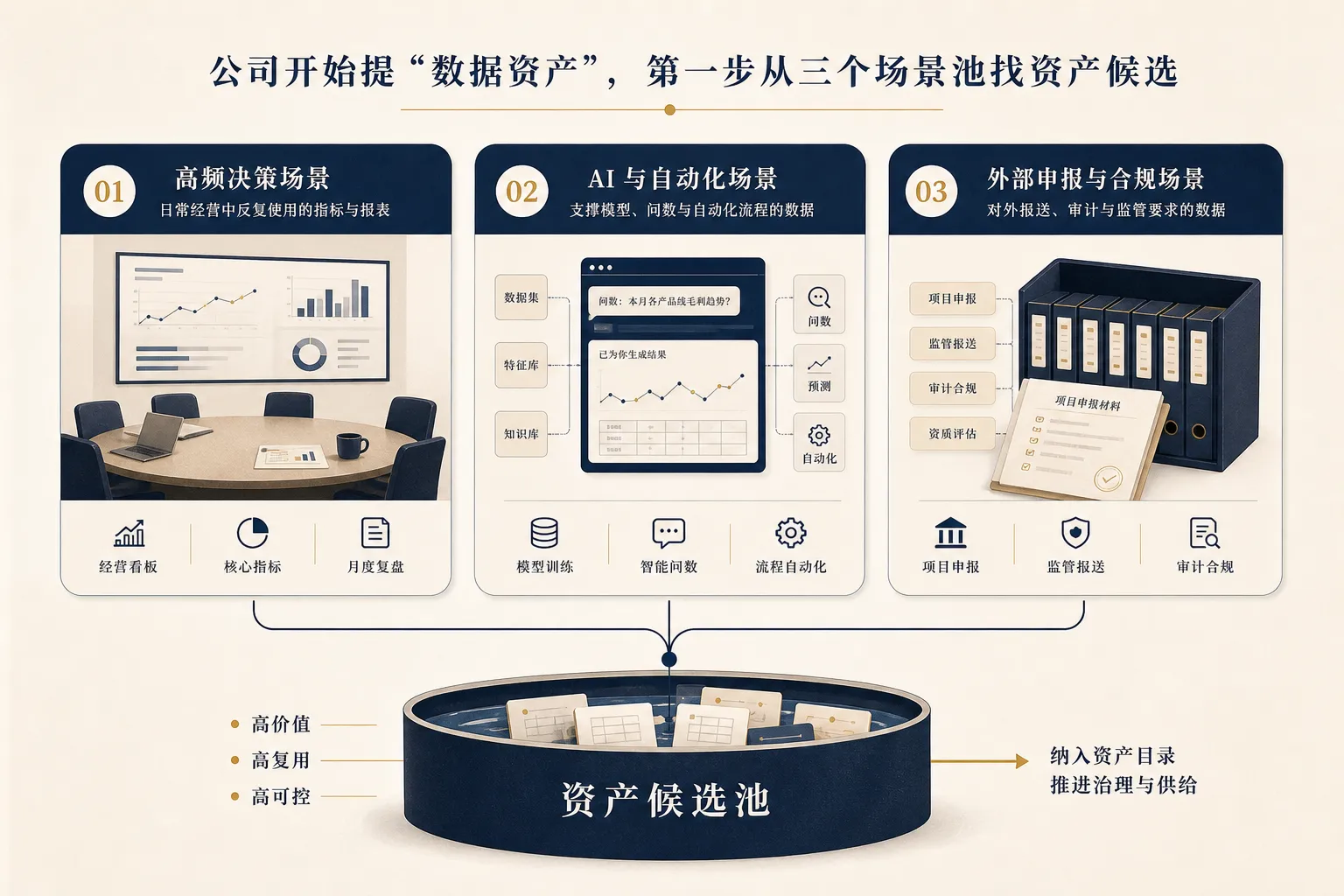
第一步:从三个场景池里找资产候选
数据资产盘点最怕全量铺开。
全量铺开的好处是看起来完整,坏处是很快没人关心。因为大多数表在当前阶段并不值得被当成资产管理。它们可能只是中间过程、历史包袱、一次性任务、废弃模型,或者没人再用的实验残留。
更好的做法,是先建立三个场景池。
1. 高频决策场景
这是最容易产生价值的地方。
比如经营会、销售复盘、渠道投放、库存预警、客户分层、履约监控、风控审核、活动复盘。只要某个场景每周、每天甚至每小时都在使用数据,它背后的核心表、核心指标、核心维度就值得优先盘。
判断标准很简单:这个数据如果错了,会不会影响会议判断?如果晚了,会不会影响当天动作?如果没人维护,业务会不会回到 Excel?
答案是“会”的,就进入候选池。
2. AI 与自动化场景
第二类是 AI 场景。
比如 AI 问数、智能客服、知识库问答、异常归因、自动报告、行业模型训练。这类场景对数据资产的要求更高,因为 AI 会把数据问题放大。
过去一个字段解释不清,可能只是分析师多问一句。现在如果模型直接拿它生成答案,错误会传播得更快。
所以凡是要被 AI 调用的数据,都要优先检查:来源、口径、权限、更新、质量、责任人。
3. 外部申报与合规场景
第三类是外部场景。
比如数据要素项目、行业试点、审计、合规检查、数据资产入表、对外合作。它们不一定每天发生,但一旦发生,就会要求你证明数据可控、可用、可追溯。
这类场景需要的不是“我们有很多数据”,而是“这份数据从哪里来,怎么治理,谁负责,用出了什么效果”。
如果公司近期正在做这类事情,相关数据也应优先进入资产候选池。
第二步:用四个问题筛掉低价值资产
有了候选池之后,不要急着登记。
先筛。
很多数据看起来重要,但短期内并不值得资产化。数据团队的精力有限,如果把所有东西都纳入管理,最后一定管不过来。
我建议用四个问题筛选。
1. 有没有明确使用者?
一份数据如果没人说得清谁会用,通常不该优先做资产。
“以后可能会用”不是使用者。
真正的使用者应该是某个角色、某个团队、某个流程。比如销售主管每周看客户转化,风控团队每天用企业风险标签,运营同学复盘活动效果,AI 问数系统要回答经营指标。
使用者越具体,资产价值越容易成立。
2. 是否解决稳定问题?
如果问题只出现一次,临时处理即可。
如果问题反复出现,就值得沉淀。
比如业务每周都问同一批指标,说明这里可能需要指标资产。每次活动都要重新拉人群包,说明这里可能需要人群资产。每次模型训练都要重新整理样本,说明这里可能需要数据集资产。
资产化的本质,是把重复问题变成稳定供给。


