
周一早上,群里突然安静了一下。
领导转来一条新闻,说 2026 年“数据要素×”大赛启动了,又补了一句:“我们今年也要看看数据资产和数据要素这块,有没有能做的项目。”
做数据的人看到这种话,心里通常会有两种声音。
一种声音说,这是机会。公司终于开始重视数据了,数据团队也许能从“取数支持”变成“价值部门”。另一种声音更诚实:这事最后不会又变成盘表、填材料、赶汇报吧?
我觉得这两个声音都对。
数据要素这几个字,放在政策文件里很大。放到普通公司里,最后往往会变成一张需求单、一场项目会、一个台账模板,或者一个被临时拉起来的专项群。
所以普通数据从业者真正要关心的,不是把每个政策名都背下来,而是看懂一个变化:当公司开始讨论数据要素时,数据工作会从“能不能把数取出来”,慢慢转向“这些数据能不能被持续使用、能不能产生价值、能不能被安全地交付出去”。
这不是一句口号。它会改变数据人在公司里的位置。
宏观词汇,最后都会落到一张需求单
很多数据同学对政策类热点天然有点距离。
这也正常。平时工作已经够忙了:今天业务催一个临时分析,明天看板有数对不上,后天上游字段又改了。你让他再去理解“数据要素价值释放”“数据基础设施”“可信数据空间”,他很容易觉得这是另一拨人在开会用的词。
可是这些词并不会一直停在会议室里。
它们会慢慢变成公司内部的动作。
比如,领导开始问:我们有哪些数据可以沉淀成资产?
比如,业务开始问:这些客户、订单、设备、工单、内容数据,能不能和 AI 应用结合起来?
比如,数据团队被要求梳理核心表、核心指标、数据质量、权限范围、共享边界。
再比如,某个部门要参加外部项目申报,突然需要你证明:这份数据从哪里来,谁维护,用在什么场景,产生了什么效果,有没有安全风险。
这时你会发现,宏观词汇一点也不远。
它只是换了一身衣服,站到了你的工位旁边。

我不建议普通数据人把自己变成政策解读专家。那不是我们的主要工作。但我建议你至少能把这些词翻译成公司里的问题。
“数据要素”翻译成人话,大概就是:公司手里的数据,不再只是系统运行留下的副产品,而是可能被管理、被使用、被交易、被计量、被投入到业务和 AI 里的生产资料。
这么一翻译,事情就近了。
你真正要看的是场景,而不是口号
判断一个数据要素项目值不值得做,第一件事不是看它名字大不大,而是看它有没有真实场景。
没有场景的数据资产,很容易变成仓库里的纸箱。
箱子上贴了标签,写着“客户数据”“交易数据”“设备数据”“经营数据”。看起来很整齐,但没人知道什么时候用、谁来用、用来解决什么问题。过一段时间,纸箱上落了灰,台账也没人更新。
真正有价值的数据,通常都贴着一个具体问题。
金融机构想更准确识别小微企业风险。制造企业想提前发现设备异常。医保部门想识别异常结算。物流企业想优化运输路径。零售公司想判断哪些门店库存不合理。AI 问数产品想让业务在不写 SQL 的情况下拿到可信答案。
这些场景不一定都很炫,但它们有一个共同点:有人真的要用数据改变一个动作。
普通数据从业者应该训练自己看这个点。
领导说要做数据资产,你可以先不急着盘全量表,而是问:这些资产准备服务哪个业务动作?
业务说要上 AI,你可以先不急着接模型,而是问:它要回答哪些问题?这些问题背后的指标口径稳定吗?答案错了谁负责?
公司说要参加数据要素项目,你可以先不急着填材料,而是问:这个项目有没有清楚的使用者、数据来源、交付物和成果出口?
只要这些问题答不上来,项目就容易滑向填表。
而做数据的人最怕的,不是项目难,是项目没有真实使用场景。没有场景,你做再多,也像在雾里搬砖。
数据能不能供得出来,是第二个分水岭
很多公司不是没有数据。
恰恰相反,数据太多了。
数据库里有表,数仓里有模型,BI 里有看板,Excel 里有人工维护的字段,业务系统里有备注,客服系统里有工单,飞书文档里还有一堆口径说明。每个地方都有一点数据,每个地方也都有一点不放心。
所以数据要素真正考验的,不是“有没有数据”,而是“数据能不能供得出来”。
供得出来,至少包括几层意思。
第一,找得到。别人知道这份数据存在,知道它大概解决什么问题。
第二,看得懂。字段含义、指标口径、统计范围、更新时间不能全靠问某个老员工。
第三,用得稳。今天能用,明天也能用;这个月的口径和下个月的口径不能悄悄变。
第四,管得住。哪些人能用,能用到什么程度,能不能导出,能不能给模型调用,要有边界。
第五,追得回。出了问题,能知道数据从哪里来,经过哪些加工,影响哪些下游。
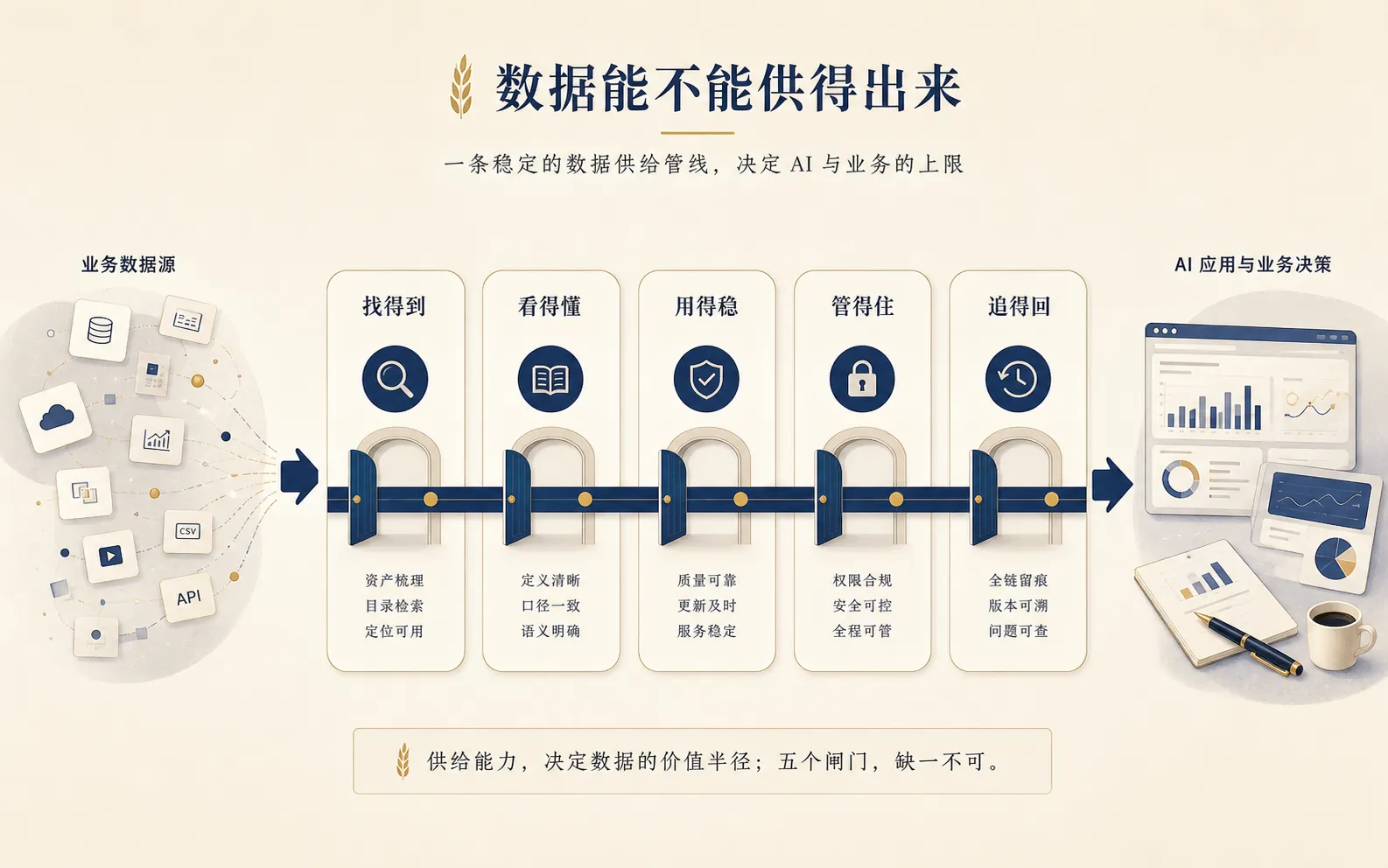
你看,这些事情听起来一点也不“新”。它们就是数据治理、指标管理、血缘、权限、质量、文档、责任人。
区别在于,过去这些工作经常被看成成本中心:麻烦、琐碎、不出成绩。
但到了数据要素和 AI 应用的语境下,它们会变成价值释放的前置条件。
没有这些底座,公司就算喊得再响,也很难把数据变成可用资产。
AI 会让“高质量数据”变得更贵
这两年很多公司谈 AI,最容易先谈模型。
用哪个大模型?要不要私有化?能不能接企业知识库?能不能自动生成分析结论?
这些问题当然重要。但真正落地时,大家很快会遇到另一个更朴素的问题:喂给 AI 的数据到底靠不靠谱?
过去数据质量差,影响的是一张报表、一场会议、一个分析结论。现在如果 AI 应用把错误口径自动扩散出去,影响会更大。
比如,一个 AI 问数工具把“成交金额”和“支付金额”混在一起。一个智能客服使用了过期政策。一个行业模型训练时混入了错误标注。一个管理驾驶舱把未审核的数据当成经营结论。
这些问题不是模型聪明一点就能自动解决。
模型越强,对数据供给的要求越高。因为它会更快调用数据、更自然地包装答案,也更容易让使用者相信它说得对。
这也是为什么高质量数据集会被反复提起。
高质量数据集不是一个漂亮文件夹,也不是一批标注样本。它更像一个能持续供给的业务资产:知道服务什么场景,知道样本边界,知道字段含义,知道质量规则,知道更新频率,知道谁负责。

这对普通数据人意味着什么?
意味着只会“把数据取出来”的价值会下降,而能“把数据变成可信供给”的价值会上升。
普通数据人要学会做翻译
我一直觉得,数据人在公司里最容易被低估的一项能力,是翻译。
不是中英文翻译,而是把不同角色的话翻译成彼此听得懂的东西。
把政策语言翻译成公司项目。
把业务愿望翻译成数据需求。
把数据问题翻译成风险边界。
把技术限制翻译成管理决策。
把一次临时取数翻译成可复用资产。
这项能力过去就重要,现在会更重要。
因为数据要素、AI、数据资产、合规这些话题,本质上都跨角色。它们不属于某一个部门。业务想要价值,技术负责实现,法务关心风险,财务关心确认,管理层关心结果,数据团队夹在中间。
如果你只会说技术语言,很容易被当成执行人员。
如果你能把这些复杂问题翻译成“我们现在应该先做哪三件事”,你在组织里的位置就会变。
举个很小的例子。
当领导说“我们要盘数据资产”,你可以只回答:“好的,我去拉表清单。”
也可以多问三句:
第一,这次盘点主要服务哪个场景?是 AI、经营分析、外部申报,还是内部治理?
第二,哪些数据即使盘出来也暂时不会用?要不要先排除?
第三,盘点结果希望形成什么交付物?目录、责任人、质量评估、使用记录,还是项目材料?
这三句话不会显得你在顶撞,反而会让项目从一开始就少走弯路。
机会不在热词里,在能留下证据的项目里
我不建议数据从业者追每一个热点。
热点太多,精力太少。今天数据要素,明天 AI Agent,后天高质量数据集,再过几天又是数据资产入表。每个都看起来重要,每个都可能让人焦虑。
更现实的判断是:这个热点能不能变成你的项目证据?
如果它能让你参与一个真实场景,梳理一批核心数据,建立一套质量规则,推动一次口径统一,做出一个可复用数据集,或者让 AI 应用更安全地上线,那么它就是机会。
如果它只是让你填表、凑材料、写汇报,最后没有人使用,也没有沉淀,那它可能只是热闹。
职业成长很多时候不是靠“参与过大项目”四个字,而是靠你能不能讲清楚:当时的问题是什么,你做了什么判断,推动了哪些动作,留下了什么结果。

数据要素这一轮变化,对普通数据人最大的价值,也许不是让每个人都去做数据交易、做数据资产入表、做大模型训练。
而是提醒我们:数据工作正在从“交付一次结果”,走向“建设可持续供给”。
这个变化很慢,也很实在。
它会出现在一张表的责任人里,出现在一次指标口径争议里,出现在一个 AI 问数上线评审里,出现在一份数据资产目录里,出现在你下一次写简历时能不能讲清楚的项目证据里。
所以,普通数据人到底该关心什么?
我觉得不是关心每个热词,而是关心四个问题:
这件事有没有真实场景?
数据能不能稳定供给?
责任和风险有没有边界?
做完以后,能不能留下可复用的结果?
这四个问题,比背概念有用。
下一次领导在群里转来一条数据要素新闻,你不必马上兴奋,也不必马上抗拒。你可以先把它翻译成一张很朴素的工作纸:谁要用,解决什么问题,用哪些数据,谁负责,怎么证明有价值。
数据这行,很多大词最后都要回到小事上。
小事做扎实了,大词才不会飘在天上。

如果你想系统补齐数据治理、数据资产、AI 应用和职业成长这些能力,可以继续看数据从业者全栈知识库。这些主题后面我会尽量拆成公司里能真正用上的方法,而不是停留在概念解释。
我叫石头,在数据行业里摸爬滚打了十几年,这一轮数据要素的热闹,我更关心它落到普通工位上会变成什么。这里写的,就是这些教训——我觉得值得说出来的那部分。
参考资料
- 国家数据局:《刘烈宏出席数据安全发展大会开幕式并启动2026年“数据要素×”大赛》 https://www.nda.gov.cn/sjj/jgsz/jld/llh/llhldhd/0523/20260523220615539632976_pc.html
- 国家数据局:《全国数据资源调查报告(2025年)》正式发布 https://www.nda.gov.cn/sjj/ywpd/sjzy/0429/20260429164803571173880_pc.html
- 国家网信办:《人工智能拟人化互动服务管理暂行办法》 https://www.cac.gov.cn/2026-04/10/c_1777558395078289.htm


