视频面试进行到第 37 分钟,面试官把简历往下翻了一页。
前面聊得都还顺。数仓分层、SQL 优化、项目里做过哪些指标,候选人都答得出来。直到面试官问:
“你们当时怎么保证数据质量?”
他答得很快:
“主要看空值、重复值、异常波动。”
这句话不能算错。
屏幕那边的人点了点头,没有接着往下夸,只是又问了一句:
“那如果 GMV 昨天少了 8%,你怎么判断是质量问题,还是业务真的下滑?”
这时候他停了一下。
不是完全不会,而是脑子里那几个词突然不够用了。空值、重复、波动,像三把常用扳手。可是面试官现在问的不是“工具箱里有什么”,而是“这台机器到底哪里响”。
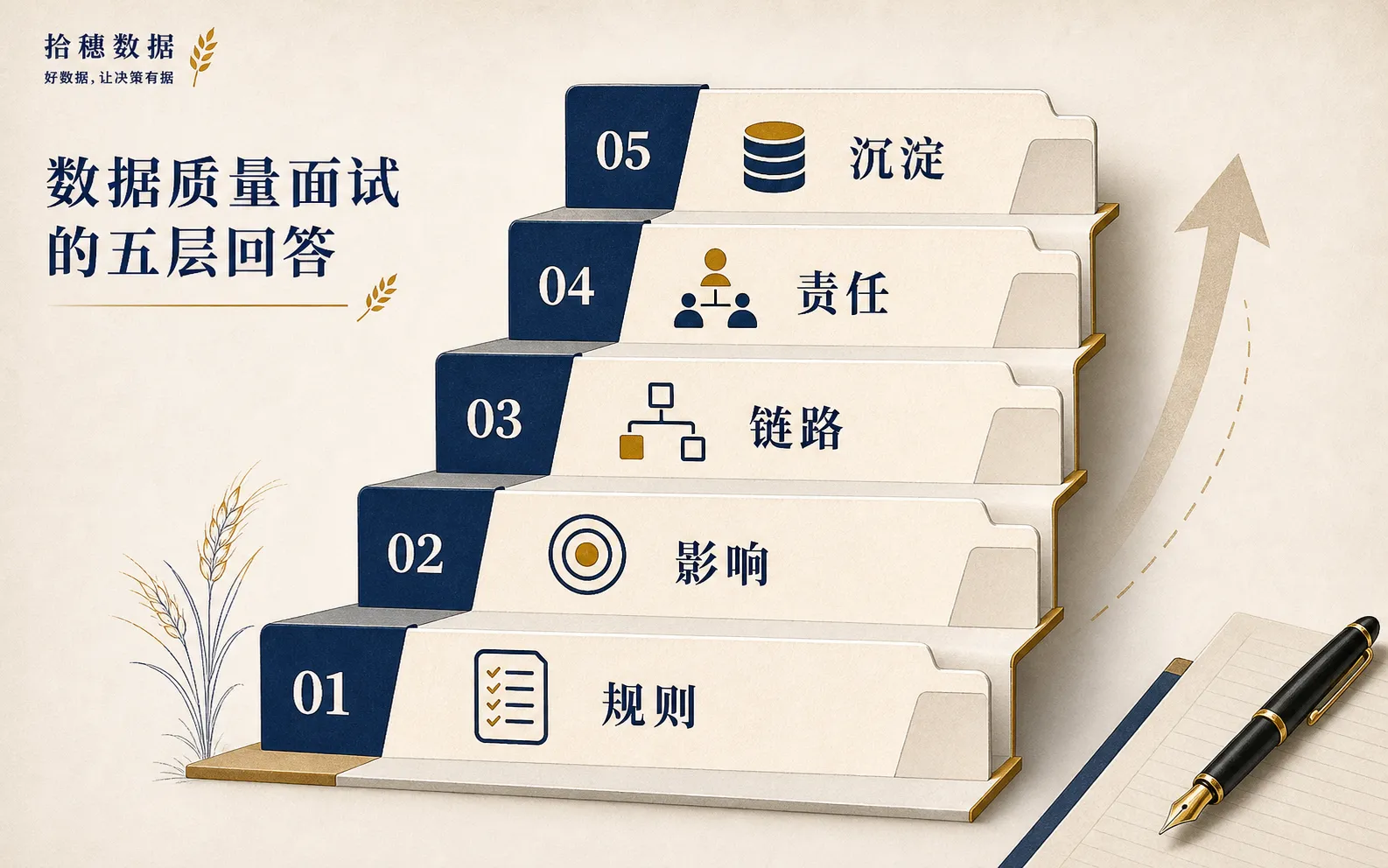
这就是数据质量面试里最常见的分水岭。很多人把它当成规则清单来背,面试官却在听你有没有处理过真实问题。
空值、重复、波动,是入门答案。
但真正的数据质量,不止是检查表脏不脏。
它要回答一个更现实的问题:这个数错了,会影响谁,谁来解释,怎么避免再次发生。
第一层:先别急着背规则
数据质量当然需要规则。
空值检查、唯一性检查、枚举值检查、范围检查、环比波动检查,这些都是基础。
如果一个候选人连这些都说不出来,那确实不合格。
但只会说这些,也很难让人眼前一亮。
因为规则本身不难。难的是你知道该给什么数据配什么规则。
一张用户维表,可能更关注主键唯一、手机号格式、注册时间合法。
一张订单事实表,可能更关注订单状态、支付金额、退款逻辑、分区完整性。
一个经营指标,可能更关注口径一致、同比环比、异常波动和上游延迟。
所以面试里更好的说法不是“我会检查空值、重复、波动”,而是:
“我会先看这张表或这个指标的业务用途,再决定质量规则。核心链路上的事实表和只做临时分析的中间表,规则级别不应该一样。”
这句话一出来,面试官会知道,你不是在背题。你知道规则不是贴纸,不能见表就贴一张。
第二层:先把“数据不对”拆开
数据质量问题最怕一句话:
“数据不对。”
这句话信息量太低。
真正处理问题时,第一步不是马上改 SQL,而是判断影响面。
你要知道:
- 哪个指标不对?
- 影响哪个时间段?
- 影响全量还是部分渠道?
- 错误方向是偏高还是偏低?
- 下游哪些看板、报告、接口使用了它?
回到刚才那个 GMV 少了 8% 的问题。
你不能一上来就说是质量问题。
可能是支付系统延迟,可能是渠道流量下降,可能是退款规则变化,可能是活动结束,也可能是上游同步少了一批订单。
面试官问这类问题,其实是在看你会不会把“现象”拆成“可验证路径”。
你可以这样回答:
“我会先和业务确认是否有活动、渠道、商品或系统变更,再从数据链路上看采集、同步、清洗、汇总和展示层是否有异常。先判断是真实业务波动,还是数据链路问题。”
这比直接说“加波动告警”要稳很多。
这里的关键,不是你有没有说出“排查链路”这四个字。
而是你有没有先承认一种可能:数据没错,业务真的变了。
很多候选人一听到“数据质量”,马上把所有问题都往数据链路上拉。可是业务世界不是专门为了让数据同学排查而存在的。活动结束、渠道停投、退款规则调整、商品缺货、节假日变化,都会让指标变动。
如果你能先把真实业务波动和数据链路异常分开,面试官会更容易相信你处理过生产问题,而不是只做过练习题。
第三层:质量规则要放在链路里
很多候选人会说:“我会给表加数据质量规则。”
这句话还不够。
规则放在哪里,很重要。
有些规则适合放在源数据接入后,比如主键、时间戳、枚举值。因为越早发现,越少污染下游。
有些规则适合放在汇总层,比如核心指标的波动、分母分子关系、业务总量校验。
还有些规则适合放在看板或服务层,比如展示口径、权限过滤、缓存刷新时间。
同一条规则,放错位置,效果会差很多。
比如你只在最终看板层发现订单缺失,已经太晚了。下游可能已经有多个报表用了这个中间结果。你看到的是一个红灯,背后是一串已经被污染的链路。
这就像厨房里发现菜已经咸了。你当然可以在端上桌前尝一口,但更好的办法,是知道盐到底是在备菜、腌制、还是出锅前放多了。数据链路也是一样,只在最后看板上报警,往往已经错过了最便宜的修复时间。
所以面试里可以补一句:
“我不会只在最后看板上做检查,而会按链路分层放规则。接入层防脏数据,明细层防主键和状态异常,汇总层防指标口径和波动异常,展示层防使用误解。”
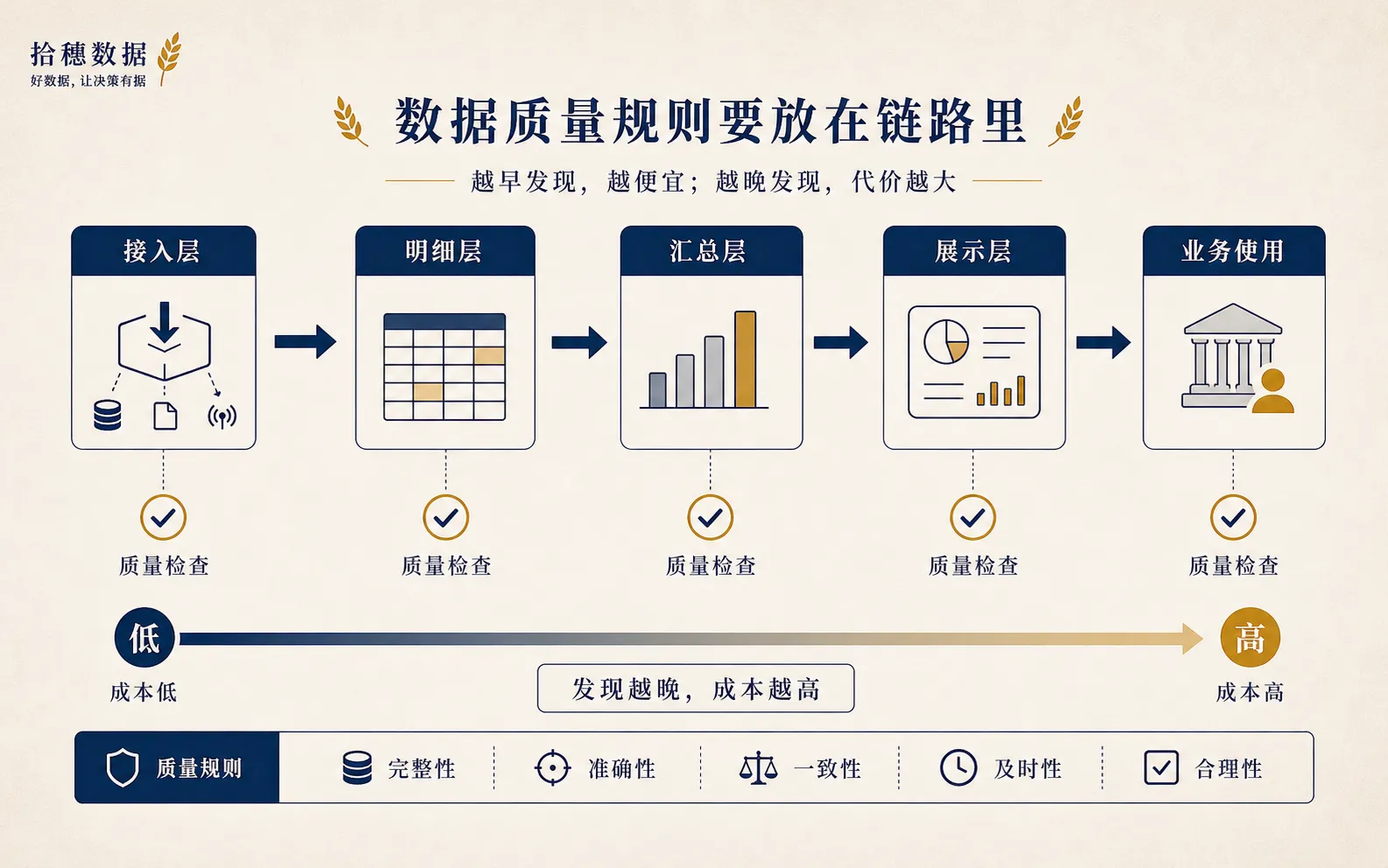
这句话说明你理解质量不是一个脚本,而是一套链路管理。面试官通常能听出来,这个人到底只是写过检查 SQL,还是见过生产链路怎么坏。
第四层:质量问题背后有人和责任
数据质量最容易被说成纯技术问题。
其实不是。
很多质量问题不是因为没人会写规则,而是因为没人负责解释规则。
比如一个字段突然多了新枚举。上游研发觉得只是业务新增状态,数据开发不知道要适配,业务看板第二天就错了。
这类事情在公司里不稀奇。字段没有恶意,系统也没有情绪,但人会互相误会。研发觉得“我已经发版了”,数据同学觉得“你没告诉我”,业务同学觉得“为什么又是我先发现”。
这时候你不能只说“我们应该加枚举检查”。
还要问:
- 上游变更有没有通知机制?
- 数据团队有没有字段负责人?
- 业务指标有没有解释人?
- 事故发生后谁通知下游?
- 修复完成后谁确认结果?
面试官喜欢听这些,因为真实公司里数据质量从来不是一个人能管完的。
你能说清责任边界,说明你见过生产环境。
第五层:把规则沉淀成可复用动作
说到这里,回答已经比“空值、重复、波动”完整很多。
但如果面试官还在听,你可以再往前走一步:沉淀。
真实工作里,最怕的不是遇到一次质量问题。谁都遇得到。更怕的是,每次遇到都像第一次。
一个成熟一点的数据团队,应该逐渐形成自己的规则模板:
- 事实表基础规则
- 维表基础规则
- 核心指标波动规则
- 调度延迟规则
- 上游变更影响规则
- 看板发布前检查规则
这些模板不需要一开始很复杂。哪怕只是一个清单,也比每次靠经验强。
我在 ss-data-skills 里放了“数据质量规则生成”“血缘影响分析”“数据事故复盘”等技能,也是为了把这些高频动作拆出来。不是让人面试时背工具名,而是让日常工作里那些容易漏的问题,有地方可以反复检查:https://github.com/shisuidata/ss-data-skills
面试时你不需要说“我用了某个工具”。你真正要表达的是:我不是只知道几类规则,我知道质量问题会发生在链路里,也知道它会影响业务判断。
真到面试现场,可以这样说
下次面试官再问你“怎么做数据质量”,不要急着把五条背出来。
你可以像讲一次真实排查那样回答:
“我不会先判断它一定是质量问题。比如 GMV 昨天少了 8%,我会先确认业务侧有没有活动结束、渠道流量变化、退款规则调整,再看数据链路有没有采集延迟、同步失败、清洗过滤或汇总口径变化。”
这句话先把“业务真的变了”和“数据链路坏了”分开。
然后接着说:
“如果确认是数据问题,我会先判断影响面:影响哪个时间段、哪些渠道、哪些看板和报告。修复时不只看任务成功,还会和源表、历史趋势、业务口径做交叉校验。最后把规则补到合适的位置,比如接入层防脏数据,汇总层防指标波动,展示层防口径误解。”
这时候,面试官听到的就不只是“我会写质量规则”。
他会听到你知道先后顺序、影响范围、验证方式和责任边界。
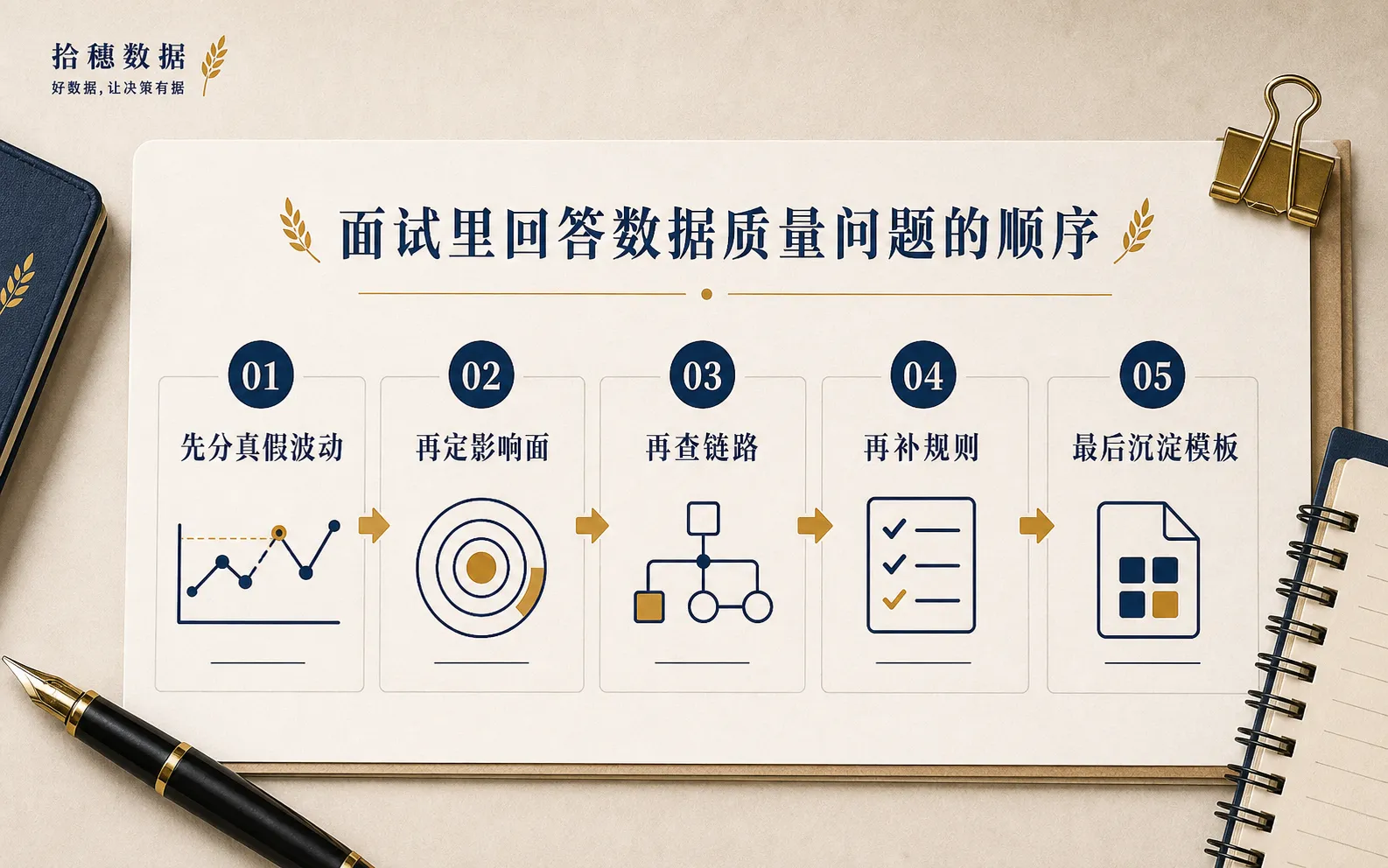
最后再补一句:
“这类问题处理完以后,我会把规则、影响面和复盘动作沉淀成模板。下次不是重新想一遍,而是按链路检查一遍。”
这套回答不花哨,但它更像一个做过事的人。
面试很多时候就是这样。
你背的是知识点。
对方想听的是,你有没有在真实世界里被数据坑过,又有没有从坑里长出一点方法。
如果你没有特别大的生产事故经历,也不用硬编。
可以从小问题讲起。比如一次字段枚举变更、一次分区延迟、一次口径争议、一次看板数和业务手工表对不上。面试官并不一定期待你处理过多么惊天动地的事故,他更想看你有没有把小问题讲成完整链路。
真实的小问题,比虚构的大项目有说服力。
你可以把它讲成四步:先看到什么现象,再怎么判断影响面,接着怎么验证原因,最后补了什么规则或流程。只要这四步成立,故事就站得住。
数据质量不是背答案。
它是你遇到“数不对”三个字时,能不能把混乱拆成可验证动作。
我叫石头,在数据行业里摸爬滚打了十几年,也面过不少把规则背得很熟、但没讲出现场的人。这里写的,就是这些教训——我觉得值得说出来的那部分。