有一个同行,在一家中型互联网公司做了六年数据工程师。
他最熟悉的事情,是一个人扛着一套数仓从无到有建起来——选型、建模、写 DDL、配调度、搭监控。他把每一张表的注释都写得清清楚楚,把每一个分区的逻辑都记在脑子里。公司里没有任何一个人,比他更懂那套系统。
前几天我们聊起 Databricks 的一组数据,他沉默了很久,说了一句话:
“我练了六年的东西,现在 Agent 两秒钟就建好了。“
先说清楚这个数字
Databricks 在 2026 年的《企业 AI Agent 现状报告》里披露了一组数字:
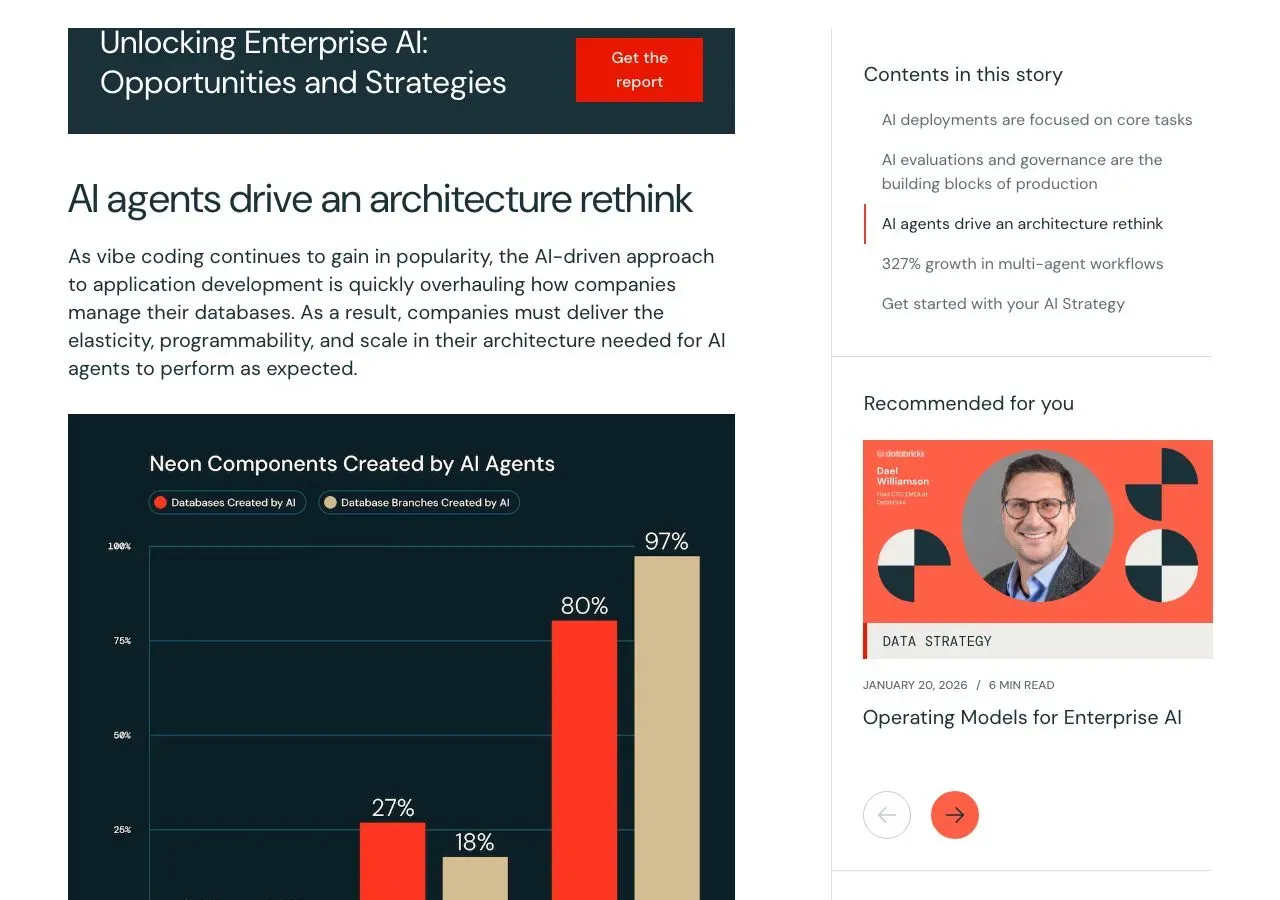
- 平台上超过 80% 的数据库,现在是由 AI Agent 创建的
- 97% 的测试和开发环境,也是由 Agent 自动构建的
- 两年前,这两个数字几乎都是零
在解读这组数字之前,有必要说清楚 Databricks 是什么规模的平台。它是全球最大的数据湖仓平台之一,付费客户超过一万家,覆盖摩根大通、康卡斯特、壳牌、Shell、Regeneron 等金融、能源、医疗、零售各行业的头部企业。他们披露的数据,不是某个内部实验或 beta 项目,而是真实客户在真实生产环境里的操作统计。
“两年前几乎为零,现在是 80%“——这个加速曲线,才是最值得认真对待的部分。
不是渐进,是跃迁。
它是怎么发生的这么快
要理解为什么短短两年能从 0% 到 80%,得先想清楚 AI Agent 到底在这件事上赢在哪里。
不是因为 Agent 比人聪明,而是因为 Agent 比人快,而且不累。
一个数据工程师新建一套开发环境,哪怕流程已经很规范,也需要申请资源、等待审批、配置参数、验证连通性——快的话两三个小时,慢的话一两天。Agent 做同样的事,可以在几秒内完成,而且可以同时启动几十个并行环境,测完即销毁,成本趋近于零。
这在 AI 应用开发场景里尤其关键。一个 AI 团队在做模型评测时,可能需要同时跑几十组不同的数据配置来对比效果。如果每次都要等人工建环境,整个实验迭代周期会被拉长十倍。Agent 接管这个环节之后,工程师的时间从”建环境”解放出来,专门用来设计实验和解读结果。
Databricks 首席架构师 Reynold Xin 在报告中说了一句话,我觉得很能说明问题:
“四十年来,数据库的设计假设人类管理员始终在回路中。当 AI Agent 成为主要操作者,这个假设立刻就崩了。”
这不只是说 Agent 可以做人的工作,而是说现有的数据库架构本身就不是为 Agent 设计的。传统数据库需要人工审批资源、需要手动复制数据、需要运维团队在旁边值守——这些假设在 Agent 操作速度下全部失效。
于是 Databricks 今年推出了 Lakebase,专门针对 Agent 重新设计了数据库架构。核心思路是把计算和存储彻底分离:Agent 可以瞬间启动无状态的计算实例,多个实例共享同一份底层数据,不需要跨环境搬运数据,也不需要人工审批资源配额。
工具在为 Agent 重新设计,不再假设有人在旁边。
这件事有多大
为了校准这个变化的量级,我找了一些配套数据。
Databricks 的报告里还提到:企业多 Agent 系统的采用率,在过去四个月内增长了 327%。78% 的企业现在同时在用多个不同的大模型家族。
IDC 的预测是:到 2026 年底,50% 的中国 500 强数据团队将使用 AI Agent 来执行数据准备和分析工作。
这不是”可能会发生”的事,而是”正在发生”的事。
有意思的是,使用数据治理工具的企业,AI 项目的成功部署量是不用的 12 倍。这个数字说明了一件事:Agent 能不能跑起来不是问题,能不能管好才是问题。
但速度背后有一个危险
速度是 Agent 的优势,也是它最大的风险来源。
没有人在看这些库是怎么建的。
Liquibase 的 VP Ryan McCurdy 把这个转变描述为:数据层正在变成”高频软件事件”(a high frequency software event)。Agent 每秒钟在创建、修改、销毁数据库结构,传统的人工审查根本来不及跟上。原来需要一个工程师审查一周的变更,现在可能在一秒内就完成了,没有任何人看过一眼。
安全公司 Averlon 的 CEO Sunil Gottumukkala 说得更具体:
“Agent 建库优先考虑速度,不考虑安全默认配置。当不安全的配置以机器速度扩散,整个基础设施的攻击面会在你不知道的情况下急剧扩大。”
还有一个更深层的问题。顾问 John Carberry 提出了”治理债”(governance debt)这个概念——AI 生成的代码极少经过人工审查,技术债和合规风险在积累,但没有人记账。
他有一句话让我印象很深:
“当 80% 的数据基础设施由 AI 建造,‘人在回路中’就成了一个神话。”

这不是在批评 Agent,而是在说一件事:Agent 带来了建造能力,但它没有带来判断能力。 它知道怎么建一个库,但它不知道这个库应不应该建、建了之后谁来负责、出了问题怎么追溯。
这个缺口,就是接下来的机会所在。
数据工程师的角色在往哪里移
先说一个容易犯的错误:把”建库的工作消失了”等同于”数据工程师消失了”。
历史上这种混淆出现过很多次。
1970 年,关系型数据库出现,DBA 不需要再手写磁盘 I/O 代码了,但 DBA 这个职业并没有消失,他们开始做索引优化、查询调优、备份恢复设计。1990 年代,SQL 普及,开发者不需要懂底层存储原理也能写查询了,但数据库工程师没有消失,他们去做了性能调优和分布式架构。2010 年代,云计算兴起,运维工程师不需要再扛服务器进机房了,但他们没有消失,他们变成了 DevOps 和 SRE。
每一次”机器替代了某种操作”,人都没有消失,只是换了一种稀缺性。
现在发生的事,本质上是同一件事的新一轮。
从建造者,变成审计者。
这不是降级,是另一种技能成为稀缺。以前稀缺的是”会建”,现在稀缺的是”会判断”。具体来说,是三种判断力:
一、架构判断力
Agent 能建库,但它建的库对不对,只有懂业务的人才能判断。
一个 Agent 可能会为你生成一个在技术上完全合法的 schema,但如果你的业务三年后要支持多租户,这个 schema 的设计就是错的。如果你的数据量级会从百万增长到百亿,Agent 没有考虑分区策略的话,这个库早晚要重建。
这类判断,需要同时理解业务走向和技术约束,Agent 目前做不了。做这件事的人,会越来越值钱。
怎么练:参与真实的数据架构评审,不只是看自己负责的那一块,而是看全局。读别人的 schema 设计,想想它三年后会遇到什么问题。
二、治理能力
“治理债”是真实存在的威胁,但治理不只是审查代码。
真正的治理是:在 Agent 大量自动建库的情况下,依然能回答这几个问题——这份数据从哪来?经过了哪些变换?谁可以访问?如果出了错,从哪里开始查?
这需要建立数据血缘追踪机制、权限管理框架、自动化合规检查流水线。不是一次性的工作,而是持续运行的体系。
根据前面提到的数据,用了数据治理工具的企业,AI 项目成功率是不用的 12 倍。治理不是”合规部门的事”,它直接决定 AI 能不能在你的数据上真正跑起来。
怎么练:主动参与数据质量和合规相关的项目,哪怕只是从搞清楚现有数据血缘关系开始。
三、业务理解力
这是最难被自动化的一层。
Agent 建的库,字段名是 user_id,它不知道这个 user_id 在你们公司有三套不同的定义,分别来自 CRM、电商系统和 APP,而且它们不能直接关联。Agent 不知道某些字段是敏感数据,不能出现在分析报表里。Agent 不知道某个指标的口径在上个季度刚改过,历史数据需要重新处理。
这类知识,存在于业务会议记录、产品文档、口头约定和历史 bug 里,没有办法被系统化地喂给 Agent。
懂业务逻辑的数据工程师,是 Agent 和真实业务之间的翻译器。这个角色没有人能替代。
我们正在经历的是哪种变化
有一个框架我觉得可以帮助理解这件事。
每次技术浪潮替代人的工作,替代的都是”执行层”,留下来的是”判断层”。蒸汽机替代了体力劳动的执行,但工程师的设计判断没有被替代。自动化流水线替代了装配的执行,但质检工程师的质量判断没有被替代。ERP 系统替代了财务数据的手工录入,但财务分析师的商业判断没有被替代。
AI Agent 现在在替代数据工程的执行层——建库、配环境、写初始 DDL。留下来的,是架构决策、治理设计、业务理解这些判断层的工作。
问题在于,很多数据工程师花了大量时间在执行层上,对判断层的投资相对不足。不是因为他们懒,而是因为执行层的工作本来就足够把时间塞满了。
Agent 接管执行层,客观上给了数据工程师一个强迫升级的机会。
当然,也是一个强迫淘汰的威胁。取决于你怎么用这个空出来的时间。
最后说一件具体的事
我认识一个数据工程师,她在一家零售公司工作,主要负责数仓建设。
去年她们团队引入了 AI Agent 辅助建库,她本以为自己的工作会被压缩。结果发现,Agent 建的库有 30% 在三个月内出现了数据质量问题——字段定义歧义、口径不一致、血缘断掉了。清查、修复这些问题,反而比原来更忙了。
她现在做的事情变了:不再花大量时间写 DDL,而是花时间建数据质量规则库,和业务方对齐每一个核心指标的定义,设计 Agent 建库时必须遵循的模板和约束。
她说:“以前我是建筑工,现在我是建筑法规的制定者。”
这句话我觉得比任何分析都准。
回到开头那位做了六年数据工程师的同行。
他说 Agent 两秒钟就建好了他练了六年的东西。
我的回应是:他练的从来不只是怎么建。他练的是知道应该建什么、怎么建才能支撑未来三年、建完之后谁负责、出了问题从哪里查。
这些东西,Agent 还没有。
这不是安慰,是一个还有效的事实。但它有效的时间,也许没有那么长了。
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些教训——我觉得值得说出来的那部分。
来源:Databricks 2026 State of AI Agents · Fanatical Futurist, 2025-12 · IT Nerd, 2026-02 · Databricks Enterprise AI Agent Trends Blog