这半年,很多数据团队都会遇到一个问题:能不能做一个 AI 问数工具?
老板想在群里直接问:“上周华东区新客转化为什么下降?”业务希望不用等分析师,自己输入一句话就能拿到图表。技术团队看了几个 Demo,发现大模型确实能根据自然语言生成 SQL,接上数据库之后,似乎很快就能跑出结果。
于是很多项目的第一版设计都很直接:用户提问,大模型生成 SQL,系统执行查询,返回结果,再让模型总结。
这个链路在演示里很漂亮。
但在企业生产环境里,它也很危险。
因为企业问数真正难的,不是让模型写 SQL,而是让它在正确的口径、正确的权限、正确的上下文和可追责的流程里回答问题。
如果这些底座没有补齐,AI 问数上线得越快,风险扩散得越快。
第一件事:不要让自然语言直接撞数据库
自然语言的问题,天然是模糊的。
用户问“本月收入怎么样”,他可能想看 GMV,也可能想看实收,也可能想看财务确认收入。用户问“新客表现”,可能按首次注册算,也可能按首次下单算。用户问“华东区”,可能是销售大区、仓配大区,也可能是行政区域。
如果系统把这句话直接交给模型生成 SQL,模型会选择一个看似合理的解释。但这个解释未必是公司认可的解释。
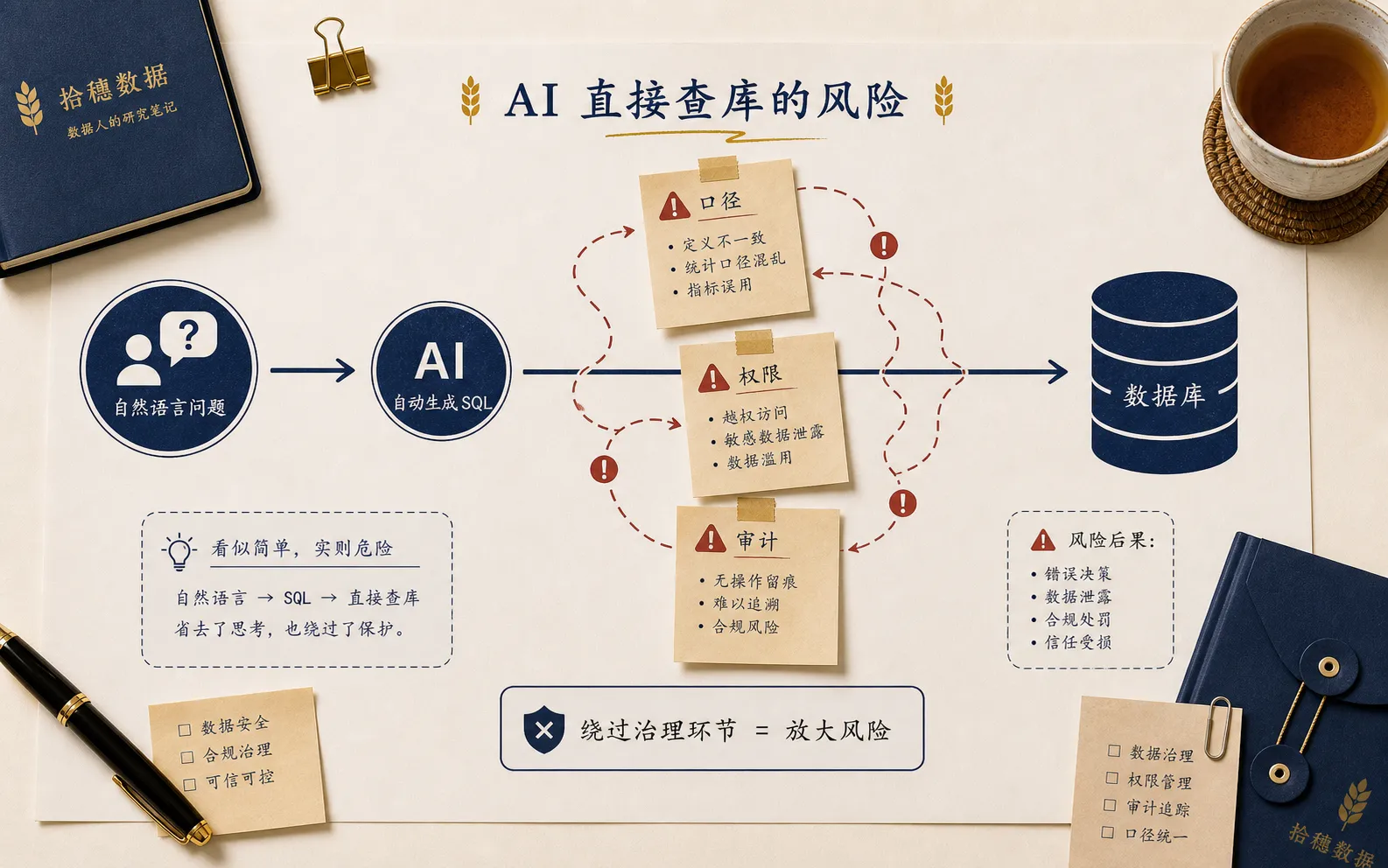
所以企业问数的第一条原则,是不要让自然语言直接撞数据库。
中间必须有语义层。
语义层不是一个时髦词,它的作用很朴素:把业务词和数据资产对应起来。收入是什么指标,新客是什么人群,华东是什么区域口径,订单表和支付表怎么关联,哪些字段可以被外部查询,哪些指标必须使用统一口径。
没有语义层,AI 只是会写 SQL 的实习生,而且是一个非常自信的实习生。
第二件事:指标口径要先有唯一入口
很多团队一上来就训练模型理解指标,其实顺序反了。
如果公司内部本来就没有统一指标入口,模型不可能凭空变出一致口径。它只会在一堆表名、字段名、历史 SQL、文档碎片里猜。
过去一个分析师猜错口径,影响一份报告。AI 问数猜错口径,可能影响几十个人的日常判断。
因此,上线问数 Agent 前,至少要先把高频指标整理出来。
不需要一开始覆盖全部指标。可以先覆盖 20 个最常用的经营指标:GMV、订单数、支付转化率、新客数、复购率、客单价、退款率、履约时长、库存周转、线索转化等。每个指标写清楚定义、计算逻辑、适用场景、时间粒度、负责人和禁用口径。