AI 问数 Demo 最容易让人兴奋。
会议室里,产品同学打开一个聊天框,输入:
“看一下上周各渠道新客转化率。”
十几秒后,SQL 出来,表出来,图也出来。
屏幕前的人会点头。
老板说:“这不挺好吗?业务以后自己问就行了。”
可是到了上线评审,气氛通常会变。
数据负责人开始问:这个“新客”按注册算,还是按首单算?权限怎么控?模型能不能看到成本表?如果 SQL 写错,谁负责?同一个问题今天和明天回答不一样怎么办?
刚才还很顺的 Demo,突然像一辆开上真实道路的样车。展厅里转向很轻,上路以后才发现刹车、盲区、保险和责任都没说清楚。
AI 问数最容易被低估的地方在这里:它不是把 SQL 写快一点,而是把数据团队原来藏着的基础问题,一口气推到业务面前。

Demo 顺,是因为问题被提前打扫过
很多 Demo 的问题都很干净。
表是选好的,字段是讲过的,问题是设计过的,权限也暂时不管。模型只需要在一个小范围里表现聪明。
真实业务不是这样。
业务会问:
- “上周活动效果怎么样?”
- “为什么华东区掉了?”
- “老客复购是不是变差了?”
- “这个渠道还要不要投?”
这些问题听起来像一句话,里面却藏着一堆判断。
“活动效果”看成交、转化、利润,还是新客?“华东区”按收货地址、销售区域,还是门店归属?“老客”按历史购买,还是最近 90 天?“要不要投”还要看预算、库存、毛利和渠道周期。
模型如果不知道这些约定,就只能猜。
猜对了,大家觉得 AI 很强。
猜错了,业务会觉得数据不可信。
更麻烦的是,Demo 里的“顺”经常会被误读成“可以上线”。
这就像在空会议室里试一把伞。伞撑开了,颜色也好看,但外面有没有风,雨从哪个方向来,地铁口会不会挤,没人知道。真实上线以后,业务问题会带着脾气进来:时间模糊、口径含糊、权限交叉、老板要导出明细。那时候,AI 不只是写 SQL,它是在替公司暴露数据秩序。
第一处翻车:权限不是登录按钮
AI 问数上线前,最容易被轻描淡写的是权限。
很多团队会说:“我们接公司单点登录,按账号控制就行。”
这还不够。
数据权限不是能不能登录,而是能不能看到某些表、某些字段、某些行,以及能不能把这些信息组合起来。
一个销售经理可以看自己区域的客户,但未必能看全公司成本。一个运营同学可以看渠道转化,但未必能看用户手机号。模型生成 SQL 时,如果没有权限约束,就可能把本来不该组合的数据拼到一起。
所以 AI 问数的权限至少要回答 3 个问题:
- 模型能访问哪些数据资产;
- 用户能看到哪些查询结果;
- 生成 SQL 之前,权限过滤在哪里生效。
权限不是上线后再补的小功能。
它是 AI 问数能不能进公司的门槛。
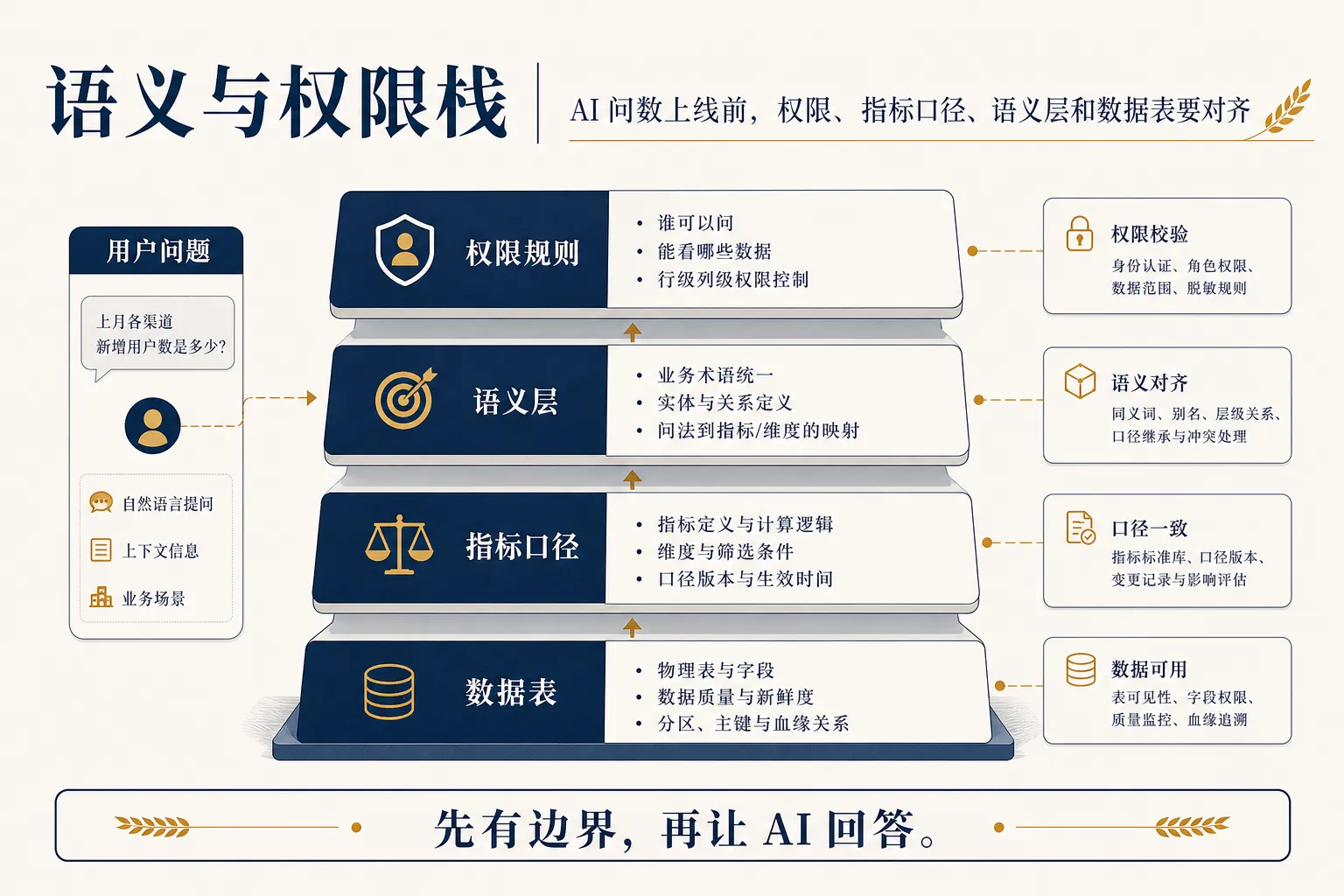
第二处翻车:口径没有变成机器能懂的东西
过去做 BI,口径很多时候写在文档里。
人可以看文档,也可以问数据同学。虽然麻烦,但还能转。
AI 问数不一样。
如果口径只停在文档里,没有进入指标层、语义层或可检索的元数据,模型很可能不知道该用哪个字段、哪张表、哪段过滤条件。
比如“有效订单”。
文档里写得很清楚:排除测试订单、取消订单、退款订单,按支付时间统计。
可是模型如果只看到 orders 表和字段名,它可能会写出一个看起来很顺的 SQL,却漏掉退款过滤。
这不是模型笨。
是公司没有把业务约定变成机器可使用的知识。
AI 问数要上线,至少要先整理一批高频指标:
- 指标名称;
- 指标定义;
- 推荐使用表;
- 必要过滤条件;
- 常见误用;
- 负责人。
不用一口气做完全公司,先做 20 个高频问题就够了。
这 20 个问题不要坐在会议室里凭空想。
去翻真实记录。经营会里老板反复问的,业务群里每周都有人追的,数据同学临时取数最多的,才是第一批应该整理的对象。AI 问数最怕从“我们觉得业务会问什么”开始,因为这句话本身就很像一个没跑过生产的 Demo。
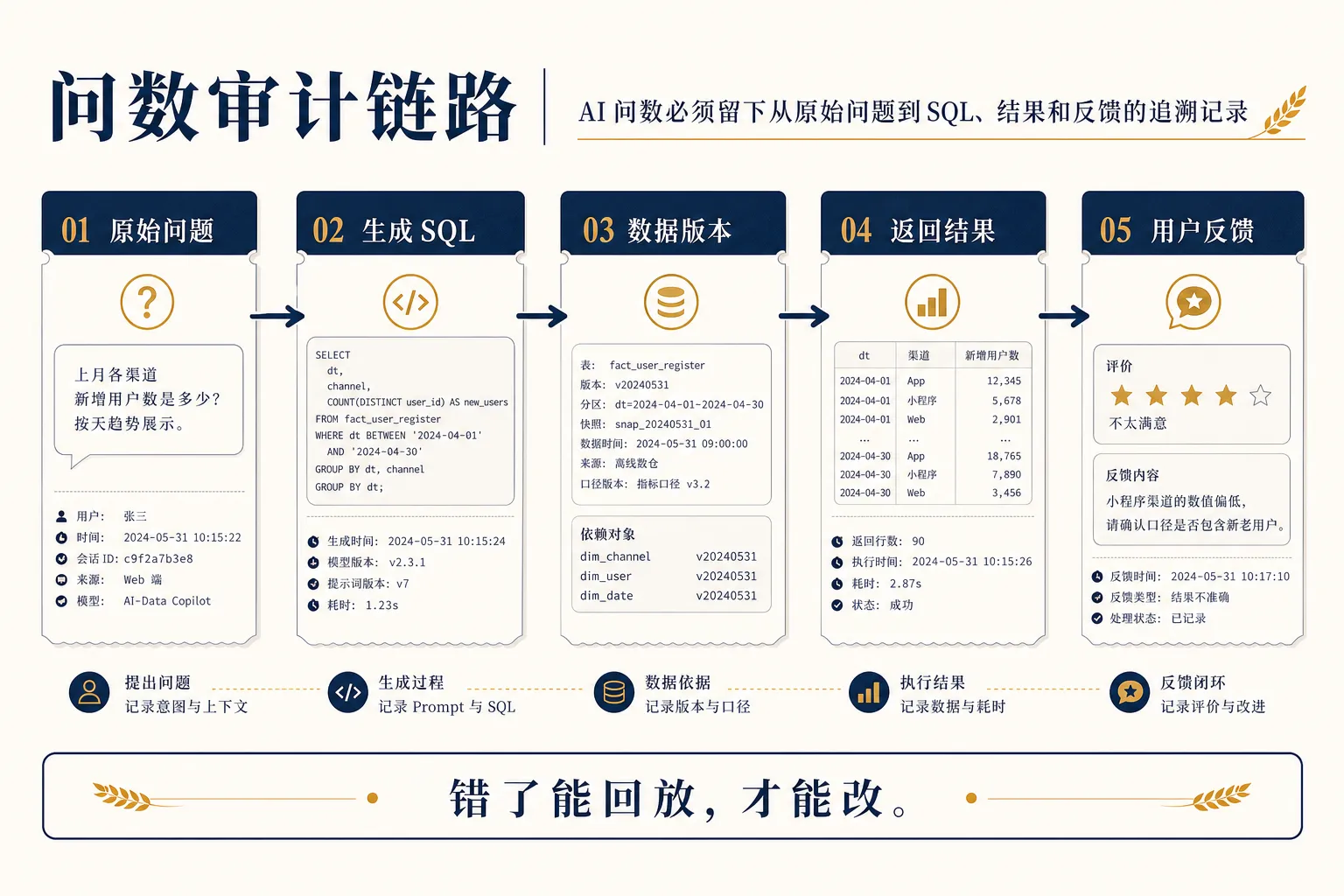
第三处翻车:模型会回答,但不会承担责任
公司里最怕一种 AI 答案:语气很确定,结果不可追溯。
业务问了一个问题,系统给了一个图。
图错了。
接下来大家开始问:当时用户问了什么?模型生成了哪段 SQL?用了哪些表?数据版本是什么?有没有人工审核?谁点击了导出?
如果这些都没有记录,这个系统就不是问数工具,而是一台责任雾化器。
它把错误分散到空气里,最后还是数据团队来吸。
AI 问数上线前,必须保留链路:
- 原始问题;
- 改写后的意图;
- 生成 SQL;
- 使用的数据表和字段;
- 执行时间和数据版本;
- 返回结果;
- 用户反馈。
这些记录不只是为了审计,也是为了让系统变好。没有记录,就没有复盘。
第四处翻车:只看成功样例,不看失败样例
Demo 喜欢展示成功。
上线要准备失败。
你需要收集一批业务真的会问、模型容易答错的问题。
比如:
- 模糊时间:“最近表现怎么样?”
- 模糊对象:“重点客户有哪些?”
- 口径冲突:“新客转化为什么和看板不一样?”
- 权限边界:“把所有客户明细导出来。”
- 业务归因:“为什么销售掉了?”
这些问题不能只靠 prompt 解决。
它们需要产品交互、权限规则、指标解释、拒答机制和人工兜底。
一个成熟的 AI 问数系统,应该敢于说:
“这个问题需要先选择统计口径。”
“你没有权限查看该字段。”
“这个指标存在两个定义,请选择经营口径或运营口径。”
拒绝乱答,比流畅胡答更重要。
这句话很不好听,但很实用。
很多系统上线后最先翻车,不是因为它不会回答,而是因为它太爱回答。业务问了一个不完整的问题,它不追问;用户没有权限,它绕过去;指标有两个定义,它挑一个看起来最顺的。表面上体验很丝滑,实际上把风险滑进了结果里。
上线前,先补 5 件小事
如果你的团队正在做 AI 问数,不用一上来就建一个宏大的平台。
先补 5 件小事:
第一,整理 20 个真实高频问题。
不要自己编,去看群聊、工单、经营会和临时取数记录。
第二,为每个问题标注推荐指标和表。
让模型知道该走哪条路。
第三,给核心指标写机器可用的定义。
不是长文档,而是能被检索、能被引用的短定义。
第四,保留问题到 SQL 到结果的链路。
错了能回放,才能改。
第五,设计拒答和澄清。
不知道就问,不该答就拒绝。

AI 问数的价值不是让数据团队消失。
它真正好的方向,是把数据团队从反复取数里解放出来,去维护口径、边界和信任。
这活不轻,但比天天救火值得。
我叫石头,在数据行业里摸爬滚打了十几年,这一轮 AI,我也是边看边想。这里写的,就是这些教训——我觉得值得说出来的那部分。


