
很多数据同学听到 AI 合规,第一反应是:“这不是法务的事吗?”
以前这么想,也许问题不大。
但企业 AI 应用真要进入生产以后,最先被追问的往往不是一条抽象法条,而是一些非常具体的问题:数据从哪里来?谁授权?能不能给模型用?模型输出要不要标识?日志留不留?出了问题怎么追?
这些问题,法务当然要参与。
但数据团队躲不开。
因为模型能看到什么数据、能调用哪些表、能回答哪些指标、输出结果基于什么上下文,很多时候都掌握在数据链路、权限系统、指标平台和日志系统里。
这篇不是法律意见,也不能替代专业合规审查。它只是从数据从业者的工作视角,讲清楚普通数据人最应该提前知道的几条边界。
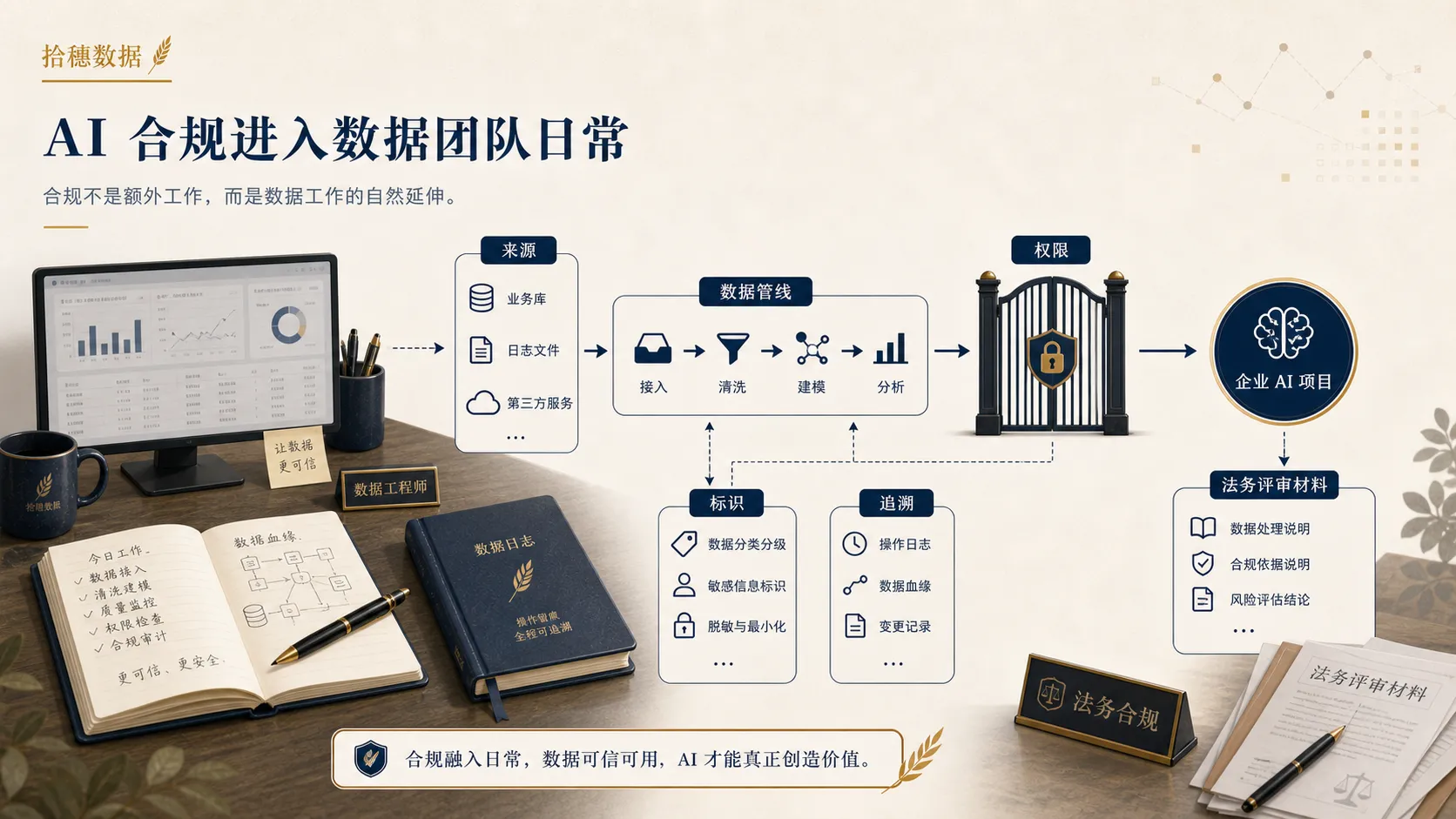
合规会从“法务文件”变成“数据工作问题”
AI 合规听起来很远,但落到项目里会很近。
业务想把客户对话接进智能客服,你要判断里面有没有个人信息、敏感信息、投诉内容、合同信息,原始采集目的是否允许继续用于模型问答。
产品想让模型读取用户行为数据,你要判断字段粒度、权限范围、最小必要、日志留存和脱敏方式。
老板想上线 AI 问数,你要判断哪些指标可以开放给所有人,哪些明细只能给特定角色,哪些问题必须返回“无权限”或“需要人工确认”。
运营想把 AI 生成的内容自动推给用户,你要判断是否需要标识、是否可能造成误导、是否有人工复核机制。
这些都不是单纯的法务问题。
它们同时是数据来源问题、权限问题、治理问题、产品问题和责任问题。
普通数据从业者不需要把自己变成律师,但必须知道:哪些地方不能再用“先接上试试”糊过去。
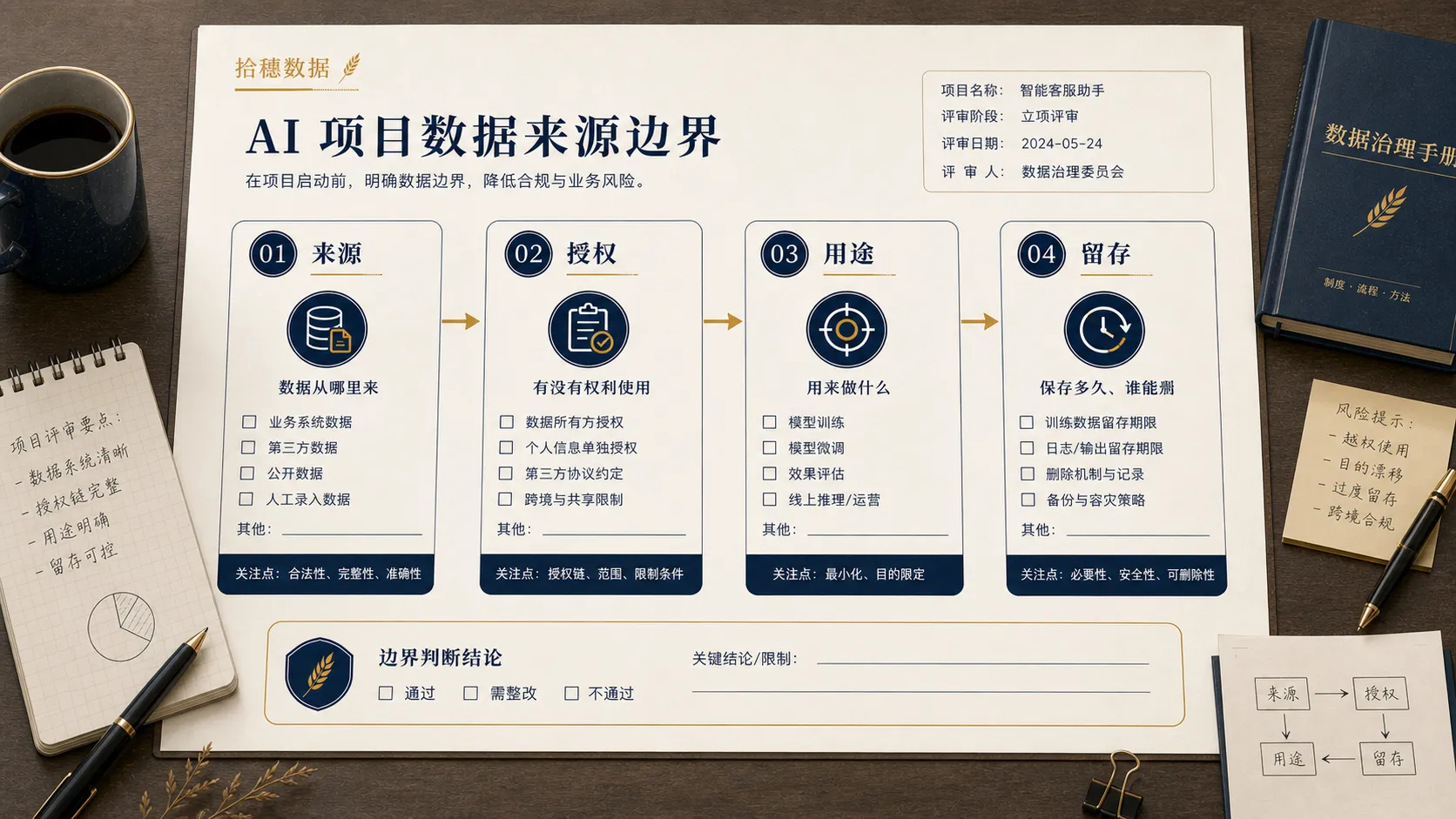
第一件事:数据来源不能含糊
AI 项目里,最危险的一句话是:“我们先拿一些数据喂进去试试。”
问题是,这些数据从哪里来?
来自用户主动提交,还是从日志里采集?来自内部业务系统,还是第三方合作方?来自公开网页,还是员工自己整理的资料?不同来源,对使用范围、留存方式、共享边界和授权要求都不一样。
数据团队至少要追问三件事。
第一,原始采集目的是什么。
数据最初是为了完成交易、提供服务、做风控、做营销,还是做内部分析?现在拿去做 AI 训练、检索增强或自动决策,是否已经超出原始目的?
第二,授权范围有没有覆盖当前场景。
“可以用于业务分析”不等于“可以用于模型训练”,“可以内部查看”不等于“可以接入外部模型服务”。
第三,数据链路是否能说清楚。
一批数据从源系统到特征表、向量库、提示词上下文、模型调用日志,中间经过哪些环节,是否有人负责,是否能追溯。
如果这三件事答不上来,项目就不应该急着上线。
第二件事:敏感信息不是脱敏一次就完了
很多团队会说:“我们已经脱敏了。”
但 AI 场景里的敏感信息问题,不是脱敏一次就结束。
因为 AI 系统常常不是只读一张表。
它可能同时读取用户画像、行为日志、订单记录、客服对话、知识库文档、权限表和历史工单。单独看每个字段都不敏感,组合起来可能就能识别一个人、推断一个状态、暴露一个商业秘密。
所以数据团队要从“字段脱敏”升级到“场景隔离”。
比如:
- 哪些字段永远不能进入提示词上下文;
- 哪些字段只能在特定角色下可见;
- 哪些明细只能返回聚合结果;
- 哪些文本进入向量库前必须清洗;
- 哪些输出需要拦截或人工复核;
- 哪些模型调用必须记录访问人、时间、输入、输出和数据来源。
在传统报表系统里,权限通常围绕“谁能看哪张表、哪个指标”。
在 AI 系统里,权限还要管“模型能不能代替用户看”“模型能不能把多个来源拼起来回答”“模型能不能把回答继续发给第三方”。
这就是数据团队必须参与的原因。
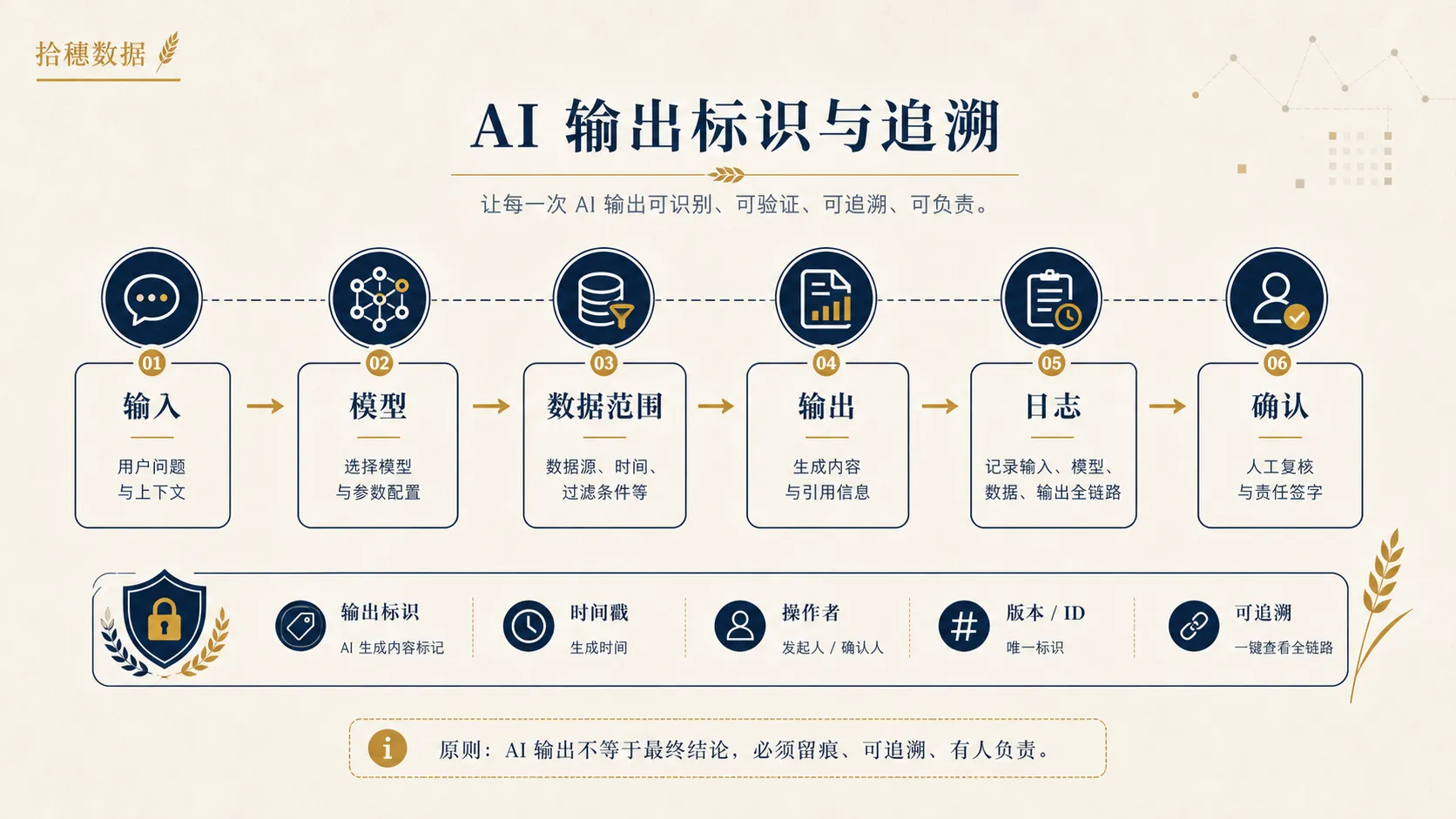
第三件事:AI 输出要能被识别、被追溯
监管对 AI 生成内容的标识要求正在变得更明确。
对数据团队来说,不需要背全部条文,但要理解一个工作原则:AI 生成、AI 合成、AI 修改过的内容,不能让使用者误以为它一定是人工原始内容。
这会影响很多内部系统设计。
比如,AI 自动生成的经营分析摘要,要不要在页面上标注“由 AI 生成,仅供参考”;AI 自动生成的客服回复,是否需要记录模型版本和知识库版本;AI 生成的数据解释,是否需要同时展示引用的指标口径和数据时间范围。
如果企业把 AI 结果直接写回业务系统,还要追问:
- 谁触发了这次生成;
- 使用了哪些数据;
- 调用了哪个模型或服务;
- 输出是否经过人工确认;
- 后续业务动作是否基于这次输出;
- 发生争议时能不能还原当时的上下文。
没有这些记录,AI 系统就会变成黑箱。
黑箱在演示阶段很酷,在生产环境里很危险。
第四件事:AI 问数要先划权限边界
很多数据团队都会遇到 AI 问数需求。
老板希望直接问:“上周销售额为什么下降?”
业务希望继续问:“是哪个区域、哪个客户、哪个销售的问题?”
这类场景很有价值,但也最容易越界。
因为自然语言会让权限边界变模糊。
在传统 BI 里,用户能看到哪些报表、哪些字段、哪些行级数据,通常比较清楚。但在 AI 问数里,用户问一句话,模型可能自动调用多个指标、多个维度、多个明细表,然后组合出一个答案。
所以 AI 问数不能只做“能不能回答”。
还要先做“允许回答到什么粒度”。
例如:
- 普通员工只能看团队级汇总,不能看个人客户明细;
- 区域经理可以看本区域数据,不能跨区域追问;
- 财务口径和运营口径要分开标注,不能混在一个答案里;
- 涉及个人信息、薪酬、合同、敏感客户时,默认拒答或转人工审批;
- 模型必须说明数据时间范围、指标口径和置信边界。
AI 问数的能力边界,本质上是数据权限、指标治理和组织责任的综合题。
如果基础治理没做好,AI 问数会把原来的口径混乱、权限混乱、数据质量问题放大。
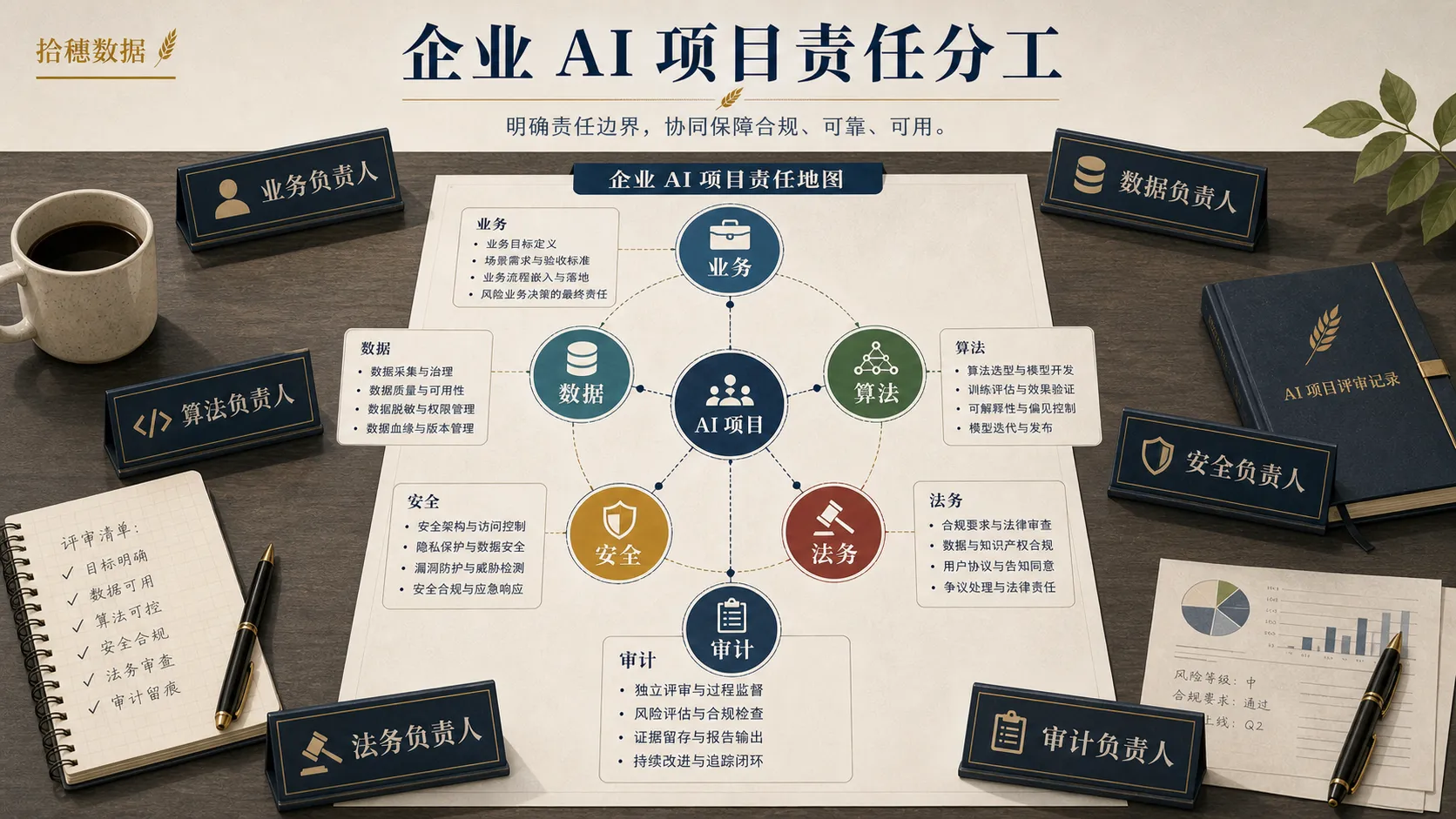
第五件事:责任分工要提前写清楚
AI 项目最怕责任悬空。
业务说这是技术工具,技术说这是业务需求,法务说上线前要评估,数据说我们只是接数据,最后谁都觉得自己只是配合。
这种状态下,项目越快上线,风险越大。
数据团队应该推动至少四类责任被写清楚。
第一,数据责任。
谁确认数据来源、使用范围、数据质量、字段含义和权限边界。
第二,模型责任。
谁确认模型服务、调用方式、版本变化、输出限制和异常处理。
第三,业务责任。
谁确认这个 AI 功能用于什么业务动作,哪些结果可以自动执行,哪些必须人工复核。
第四,审计责任。
谁负责保存调用日志、变更记录、权限记录和问题追溯材料。
这不是为了把流程做重,而是为了避免项目出问题时大家才开始补文档。
普通数据人现在可以做什么
如果你不是负责人,只是一个数据分析师、数据开发、BI 工程师或数据产品经理,也可以从几件小事开始。
第一,给 AI 项目补一张数据清单。
写清楚数据来源、字段范围、使用目的、权限角色、是否包含个人信息或敏感信息、是否进入模型上下文或向量库。
第二,给 AI 输出补一层说明。
至少说明数据时间范围、指标口径、生成方式、是否由 AI 生成、是否需要人工复核。
第三,把高风险问题列成拒答规则。
不是所有问题都应该回答。涉及个人隐私、敏感客户、薪酬、合同、未公开经营数据、跨权限明细时,要有明确拦截或审批逻辑。
第四,保留日志。
AI 系统一旦进入生产,日志不是可有可无。没有日志,就很难解释为什么模型当时给了那个答案。
第五,推动指标口径治理。
AI 问数越强,指标口径越不能含糊。否则模型只是把混乱包装成更流畅的回答。
结尾:AI 合规不是让数据人背锅,而是让边界提前变清楚
我不建议数据从业者把自己吓成半个律师。
但也不能把 AI 合规完全丢给法务。
真正落地的企业 AI 项目,一定会经过数据团队的手:接哪些数据、开放哪些权限、返回哪些指标、记录哪些日志、标识哪些输出、保留哪些证据。
这些工作如果提前做,合规就是边界管理。
如果上线后再补,合规就会变成事故处理。
未来的数据团队,不只是把数据接给模型,还要让模型在可解释、可追溯、可控的边界内使用数据。


