
企业 AI 项目会上,最容易被轻描淡写的一句话是:
“先接一些数据试试。”
这句话在 demo 阶段听起来很正常,在生产环境里却可能埋下很多问题。
数据从哪里来?有没有授权?是否包含个人信息或敏感信息?能不能进入模型上下文?模型输出是否需要标识?用户追问时能不能返回明细?出了争议以后,能不能还原当时用了哪批数据、哪个模型版本、哪条提示词?
这些问题听起来像法务问题。
但真正上线时,数据团队一定会被问到。
因为企业 AI 应用的很多风险,不是在“模型”这个词上发生的,而是在数据接入、权限开放、知识库构建、日志留存、结果展示这些具体工作里发生的。
这篇文章不是法律意见,也不替代专业合规审查。它给数据开发、数据治理负责人、BI / AI 产品经理一套可以在项目评审会上使用的四条边界检查法。
为什么数据团队不能只做接口提供方
在传统数据项目里,数据团队经常扮演“提供数据”的角色。
业务要报表,数据团队建模型;产品要接口,数据团队出 API;管理层要指标,数据团队统一口径。
但 AI 项目会改变这个边界。
因为 AI 不是简单展示数据,而是会读取、组合、解释、生成,甚至推动下一步业务动作。
同样是一张客户表,在普通报表里,它可能只是展示客户数、成交金额、区域分布;在 AI 系统里,它可能被放进提示词上下文,被向量化检索,被模型综合其他数据推断客户意向,被客服机器人用于生成回复。
数据的使用方式变了,风险也会变。
所以数据团队不能只问:“接口能不能接?”
还要问:“这个 AI 功能准备用这些数据做什么?”
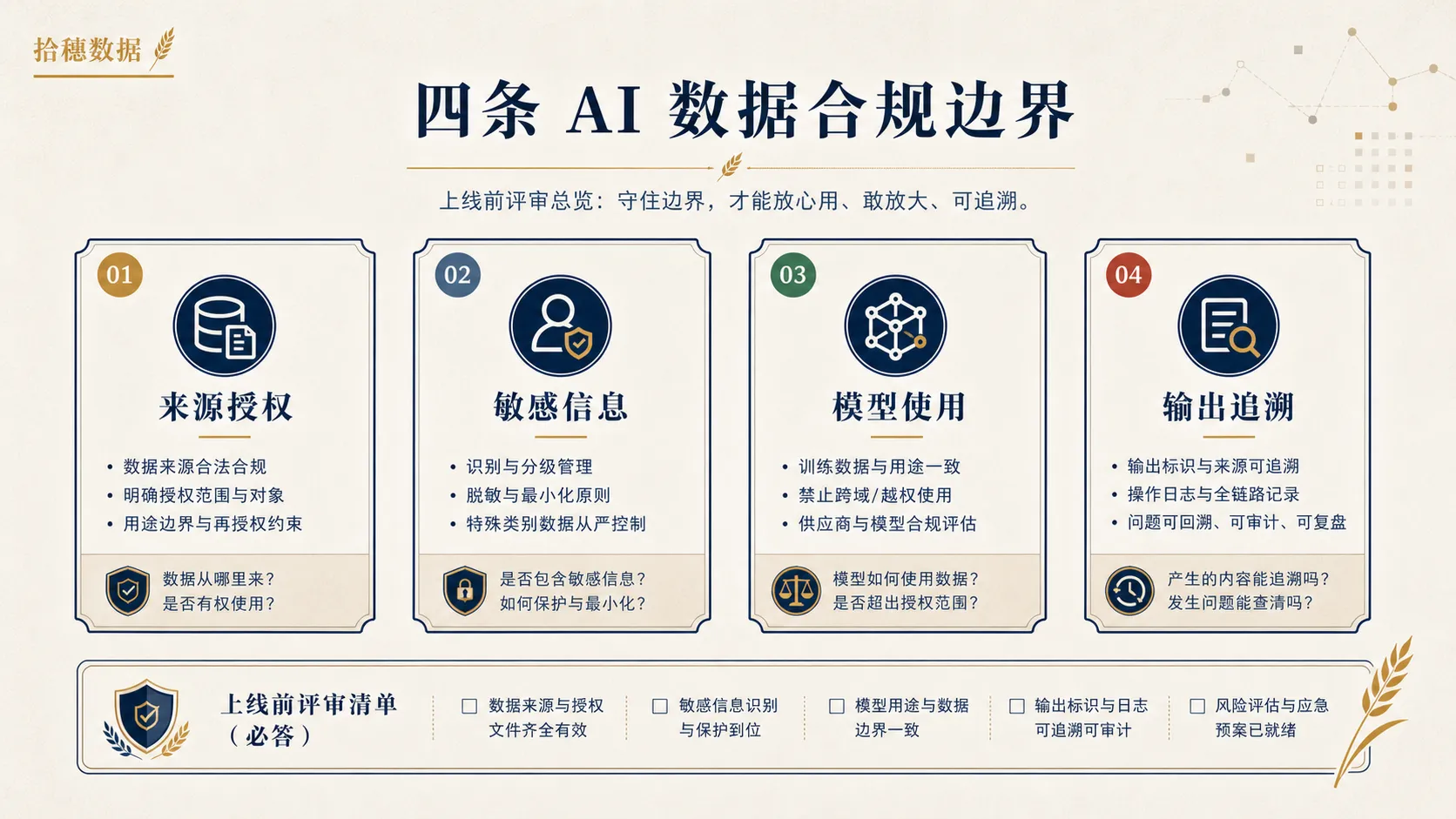
边界一:来源授权边界
第一条边界,是数据来源和使用授权。
企业内部数据并不天然都能给 AI 用。
有些数据来自用户主动提交,有些来自业务系统,有些来自第三方合作,有些来自公开网页,有些来自员工整理的知识文档。来源不同,使用范围、共享边界、留存方式和责任主体都不同。
在《生成式人工智能服务管理暂行办法》里,训练数据和基础模型的合法来源、个人信息处理、知识产权和数据质量都是明确被关注的问题。对企业内部项目来说,即使你不是对外提供大模型服务,也不能忽略这些原则。
数据团队在项目评审时,至少要追问六个问题。
| 检查项 | 要问的问题 | 应留证据 |
|---|---|---|
| 数据来源 | 数据来自哪个系统、合作方或公开渠道 | 来源清单、表名、接口说明 |
| 原始目的 | 最初采集或产生数据是为了什么 | 隐私政策、业务协议、采集说明 |
| 当前用途 | 现在用于 AI 问答、训练、检索还是摘要 | AI 场景说明、产品需求文档 |
| 授权范围 | 是否覆盖当前用途,是否需要重新告知或授权 | 授权记录、法务意见、审批记录 |
| 跨主体流转 | 是否给外部模型服务、供应商或第三方系统 | 供应商协议、数据处理协议 |
| 留存期限 | 原始数据、向量数据、日志保留多久 | 留存策略、清理任务记录 |

这里最容易被忽略的是“用途变化”。
很多数据在原系统里是合法使用的,但换到 AI 场景里,使用目的已经变了。
例如,客服对话原本用于服务质检,现在拿去训练自动客服;用户行为日志原本用于产品分析,现在进入 AI 个性化推荐;内部文档原本只给员工查阅,现在接入外部模型服务。
数据团队不需要独自判断所有法律问题,但必须把用途变化暴露出来,让业务、法务、安全和数据负责人一起确认。
边界二:敏感信息边界
第二条边界,是敏感信息和最小必要。
AI 项目最容易犯的错误,是把“能读到”当成“应该读到”。
一个智能客服不一定需要读取用户完整身份证号;一个销售助手不一定需要读取客户全部合同附件;一个经营分析助手不一定需要返回个人级薪酬、绩效或未公开客户明细。
在个人信息保护要求下,处理个人信息要有明确、合理的目的,并与处理目的直接相关,采取对个人权益影响最小的方式。敏感个人信息更要有特定目的和充分必要性。


