这一周的数据平台新闻,不像“又多了几个按钮”这么简单。
它更像一个信号:企业数据平台正在把 AI 问数、BI 看板、语义层、权限审计和开放表格式重新缝在一起。
以前我们说 AI 进数据团队,常常停在 Demo:业务输入一句话,模型返回一张图,领导觉得很神奇。
可是到了生产环境,问题马上变得朴素:谁能问?问到的数据从哪里来?模型用了哪套口径?回答错了能不能追溯?嵌到业务系统里以后,成本和权限怎么管?
这周几条消息放在一起看,答案正在浮出来。
AI/BI 不再只是“会聊天的报表”。它开始变成一套需要治理的数据产品。
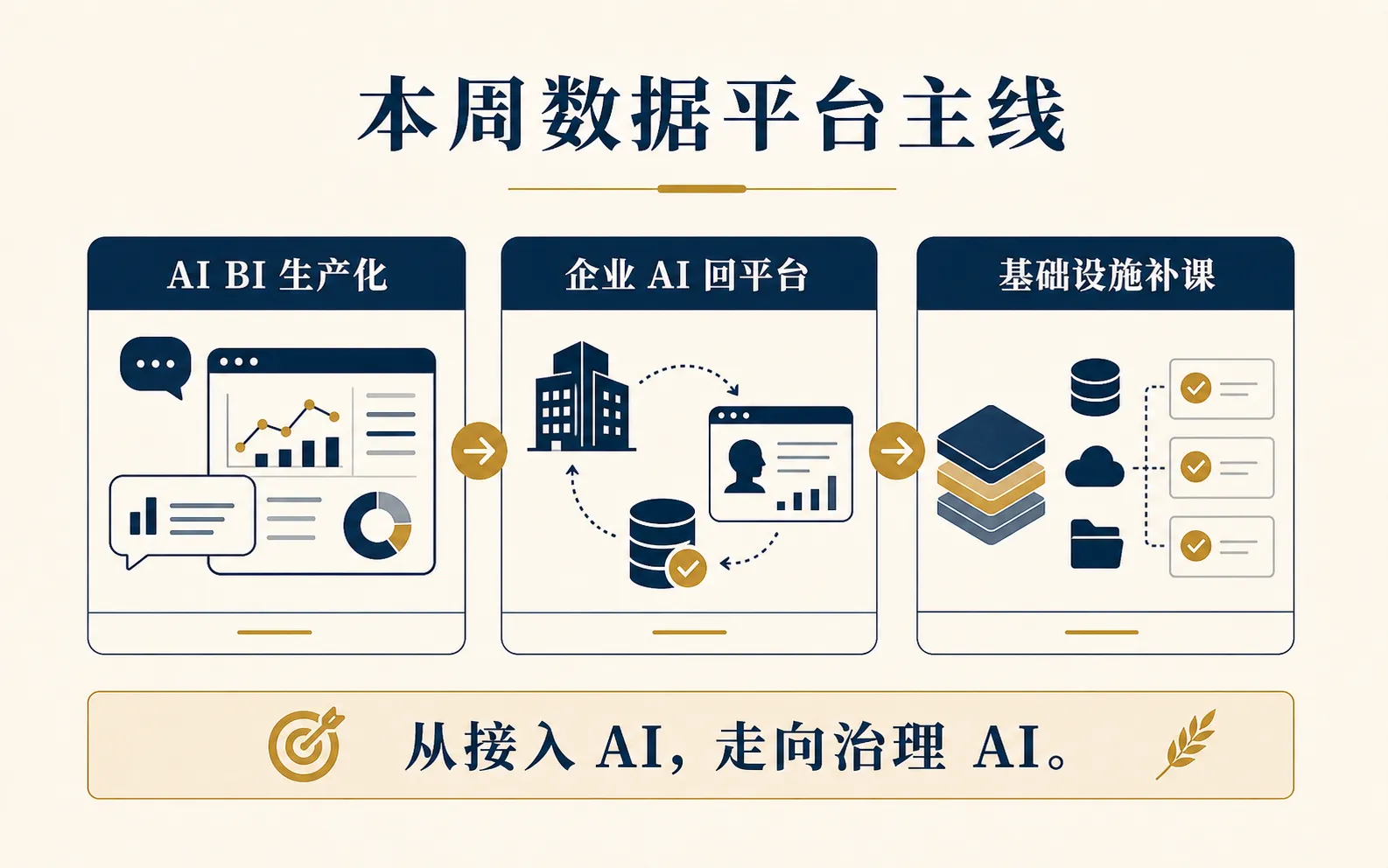
Databricks:Genie 正在从问数 Demo 走向生产治理
Databricks 在 2026 年 6 月 4 日的 AI/BI 和 Genie 更新里,放出了几类很值得关注的变化。
第一类是看板能力继续补齐:Dashboard 支持保存共享筛选书签,透视表列可以展开折叠,主题样式可以更细地定制,还支持 Dashboard variables,让浏览者在可视化里切换字段。
这类功能看起来很传统,但它说明 AI/BI 不是要把 BI 干掉,而是在把传统 BI 的交互体验继续补上。
第二类更关键:Genie Space 开始强化监控和嵌入。
更新里提到,Genie Chat 的 prompt 和 response 在开启共享 Beta 后可以进入 Genie Spaces monitoring;Genie Space 作为 iframe 嵌入外部应用已经 GA;Workspace 管理员还能在工作区层面对 Genie 做品牌和欢迎内容定制。
这几件事放在一起,就不是一个“问数助手”的小更新了。
它意味着自然语言问数正在进入业务系统、进入监控面板、进入企业自己的界面,而不是只停在数据平台里的一个聊天框。
对数据团队来说,这件事真正麻烦的地方在于:一旦 AI 问数被嵌进业务系统,它就会变成生产链路的一部分。
过去一个看板错了,大家还能说“这个报表口径有点问题”。
现在一个 AI 回答错了,业务同事可能不会觉得是模型问题。他会觉得“数据平台告诉我就是这样”。
所以 Genie 这类产品越走向生产,数据团队越要补三件事。
第一,语义层要清楚。
指标定义、维度含义、默认过滤条件、哪些表可以被问、哪些字段应该隐藏,都不能只靠数据同学脑子里的经验。
第二,监控要能看见。
用户问了什么,模型答了什么,哪些问题高频,哪些回答被追问,哪些空间被嵌到业务系统里,都应该有记录。
第三,权限和成本要提前设计。
AI 问数一旦开放给更多业务用户,就不再是几个分析师的试验。它会带来权限扩散、计算成本、模型调用成本和责任归属问题。
这周 Databricks 的更新,对普通数据从业者的提醒很直接:AI/BI 的下一步不是“更会聊天”,而是“更像一个要被运维的数据产品”。
Snowflake:企业 AI 不再绕开 SQL,而是回到数据平台里
Snowflake Summit 2026 在 6 月 1 日到 4 日举行。Snowflake 官方 Summit 页面把这次发布概括为一批产品创新,包括 Snowflake Openflow、Adaptive Compute、Marketplace 上的 agentic products、Cortex AISQL 和 Snowflake Intelligence。
这些名字很多,普通数据同学不需要都背下来。
真正值得注意的是它们指向的方向:企业 AI 正在回到数据平台内部。
过去很多 AI 项目喜欢绕开数仓和 BI 系统,单独拉一套向量库、单独做一套应用、单独跑一套脚本。这样做 Demo 很快,但上线以后会遇到老问题:数据来源不清,权限另起一套,业务口径不一致,成本不可控,结果难审计。
Snowflake 这类平台现在强调 AI SQL、上下文层、智能体产品和自适应计算,本质上是在说:不要把企业 AI 做成漂在数据平台旁边的一团云。
它要回到数据、计算、治理和应用分发这些老地基上。
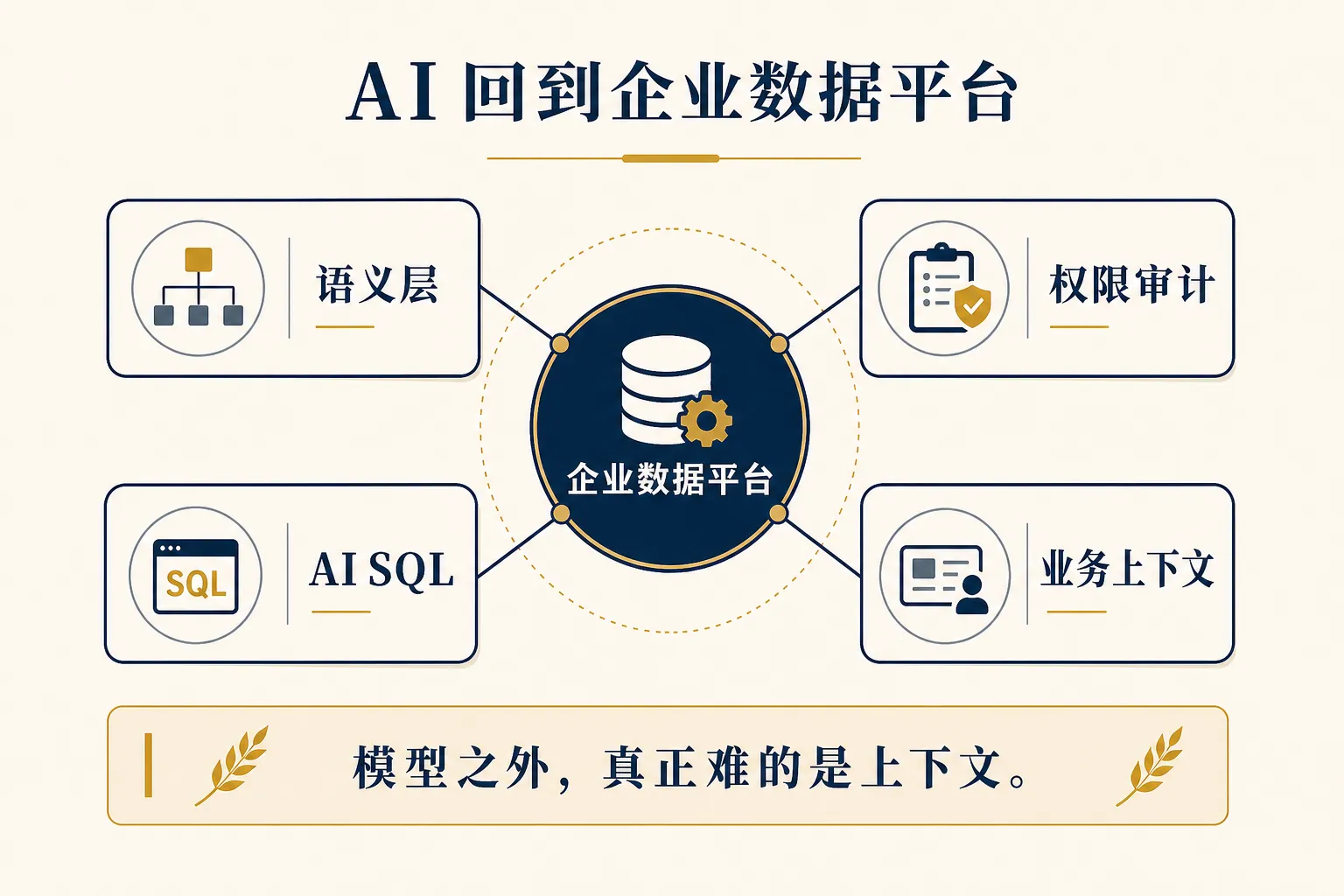
这对数据团队有两个具体影响。
第一个影响,SQL 的边界会继续扩大。
以前 SQL 主要处理结构化数据,聚合、过滤、关联、窗口函数。现在越来越多平台希望把文本分类、摘要、提取、语义判断这些 AI 动作也放进 SQL 或类 SQL 工作流里。
这不是说每个分析师都要变成算法工程师。
它更像是:数据团队以后会被要求用熟悉的数据工程方式,管理非结构化数据和 AI 推理过程。
第二个影响,企业内部会更需要“上下文工程”。
所谓上下文,不只是把几段文档塞给模型。它包括业务定义、指标口径、数据血缘、权限边界、历史决策、异常说明和领域知识。
如果这些东西不在数据平台里被管理,智能体就只能靠猜。
所以 Snowflake 这周的信号,和 Databricks 很像:AI 数据平台的竞争,不只是模型能力,而是谁能把企业上下文管理得更可信。
对普通数据从业者来说,这不是远处的大厂竞争。
它会落到你手里的工作上:指标字典要不要补,血缘能不能查,字段说明是否可信,知识文档能不能被 AI 使用,权限策略是否能覆盖 AI 查询。
这些活不时髦,但会越来越贵。
Iceberg 与 Airflow:底层基础设施进入“少出错”的阶段
除了 AI 平台的热闹,这周我也会看一些不那么吸睛的基础设施更新。
Apache Iceberg 1.11.0 在 5 月底发布,Google Open Source Blog 提到,这个版本增加了对 Apache Spark 4.1 和 Apache Flink 2.1 的支持,并把它们作为默认构建目标。Iceberg 官方 releases 页面也显示,5 月 18 日发布的 1.10.2 主要是 bug fix 和 security fix,覆盖核心、Flink 等部分。
Apache Airflow 方面,官方 release notes 显示 Airflow 3.2.2 在 2026 年 5 月 29 日发布。
这些更新不如 AI 问数容易传播,但对数据工程团队非常现实。
开放表格式、调度系统、流批引擎这些东西,进入公司以后不是用一周,而是用很多年。它们真正影响生产的地方,往往不是“新功能多酷”,而是兼容性、升级路径、安全修复和多引擎一致性。
Iceberg 支持更新版本的 Spark 和 Flink,意味着开放表格式继续在多引擎环境里补课。
Airflow 继续滚动发布 3.2.x,说明调度编排也进入了 3.x 之后的稳定维护期。
对数据团队来说,这些新闻可以翻译成几个朴素问题。
你的湖仓表格式是不是只被一个引擎使用?
Spark、Flink、Trino、Python 任务读写同一批表时,是否真的一致?
调度系统升级时,DAG、数据资产触发、权限、插件和历史任务有没有验证?
你们有没有一套“平台升级前后怎么验收”的清单?
这类问题平时没人爱聊,出事故时每个人都会想起它。
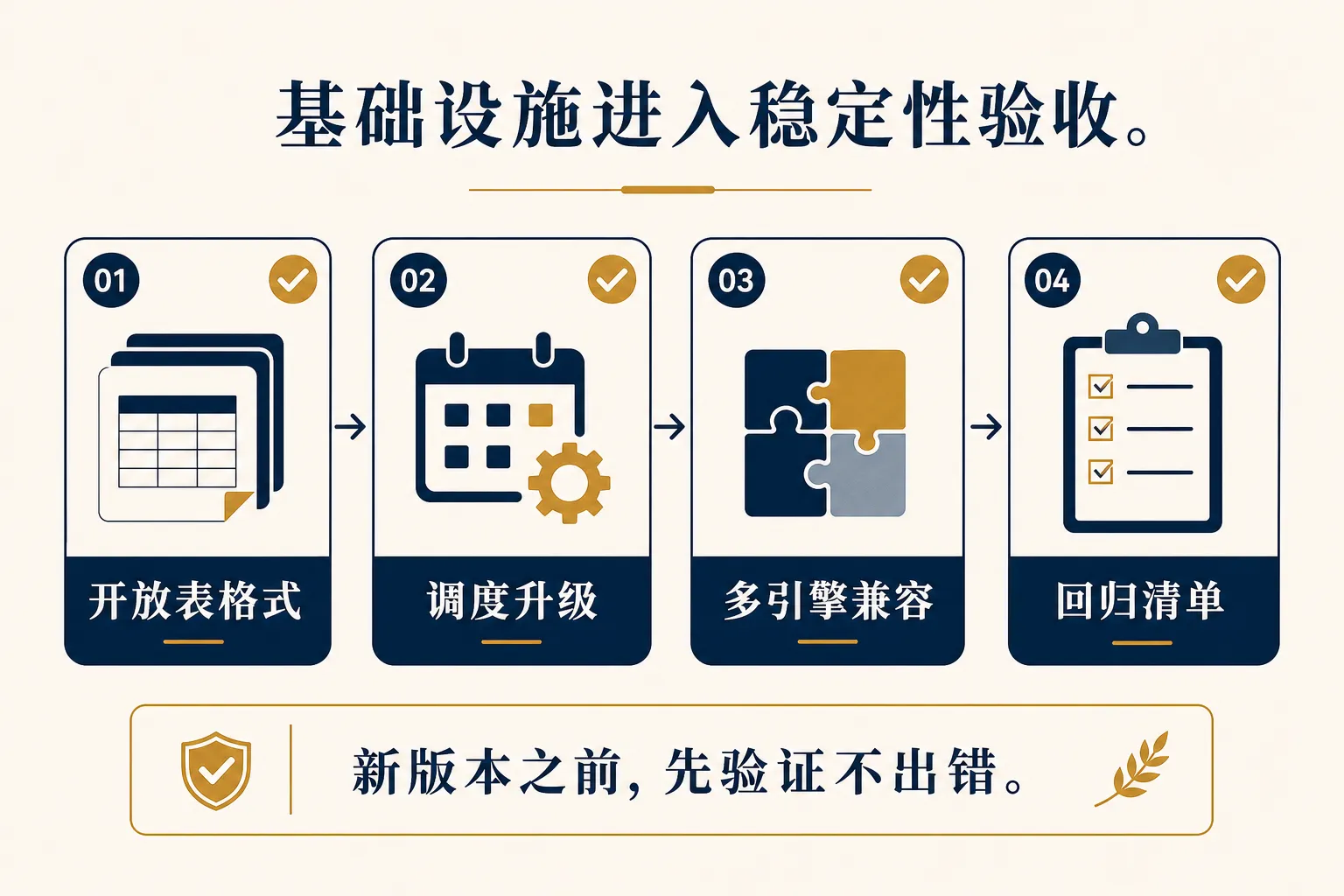
这一周给数据团队的三个提醒
第一,AI/BI 要按数据产品来管。
只要它开始被业务用户反复使用,或者被嵌到业务系统里,就不能只按 Demo 看。你需要语义层、权限、监控、成本和责任机制。
第二,企业 AI 的关键不只是模型,而是上下文。
字段说明、指标口径、数据血缘、业务规则和异常解释,都会变成 AI 能不能答对的底层材料。以前没人维护的文档,以后可能会变成模型回答的依据。
第三,底层基础设施不要只追新版本,要做升级验收。
Iceberg、Airflow、Flink、Spark 这些东西影响的是数据平台的地基。升级之前,最好先有一套回归清单:核心表能不能读写,调度能不能恢复,权限有没有变化,历史任务是否兼容。
这周最值得记住的,不是某个功能名。
而是一个方向:数据平台正在从“把 AI 接上来”,走向“让 AI 在可治理的数据系统里运行”。
这句话听起来没那么热闹。
但公司里真正能落地的 AI 数据项目,大概率都要经过这一步。

如果你想系统补齐数据治理、AI 应用、指标体系和职业成长这些能力,可以继续看数据从业者全栈知识库。这些主题我会继续拆成公司里能真正用上的方法。
我叫石头,在数据行业里摸爬滚打了十几年。每周看这些发布,我更关心的不是“谁又发了一个 AI 功能”,而是它会不会变成普通数据团队下周要补的语义层、权限表、监控项和升级清单。
参考资料
- Databricks Docs:AI/BI and Genie release notes 2026,June 2026 更新 https://docs.databricks.com/aws/en/ai-bi/release-notes/2026
- Snowflake:Summit 2026 官方页面,June 1-4, 2026 https://www.snowflake.com/en/summit/save-the-date/
- Google Open Source Blog:Announcing Apache Iceberg 1.11.0 https://opensource.googleblog.com/2026/05/announcing-apache-iceberg-1110.html
- Apache Iceberg:Releases https://iceberg.apache.org/releases/
- Apache Airflow:Release Notes https://airflow.apache.org/docs/apache-airflow/stable/release_notes.html