
过去一年,很多团队都在讨论 AI 怎么进入数据工作。
有人用它写 SQL,有人用它解释报表,有人让它生成指标口径说明,有人试着把数据查询、分析摘要、异常归因连成 Agent 工作流。演示时效果经常不错:输入一句自然语言,模型给出查询;上传一份数据,模型生成洞察;接入元数据,模型还能解释字段。
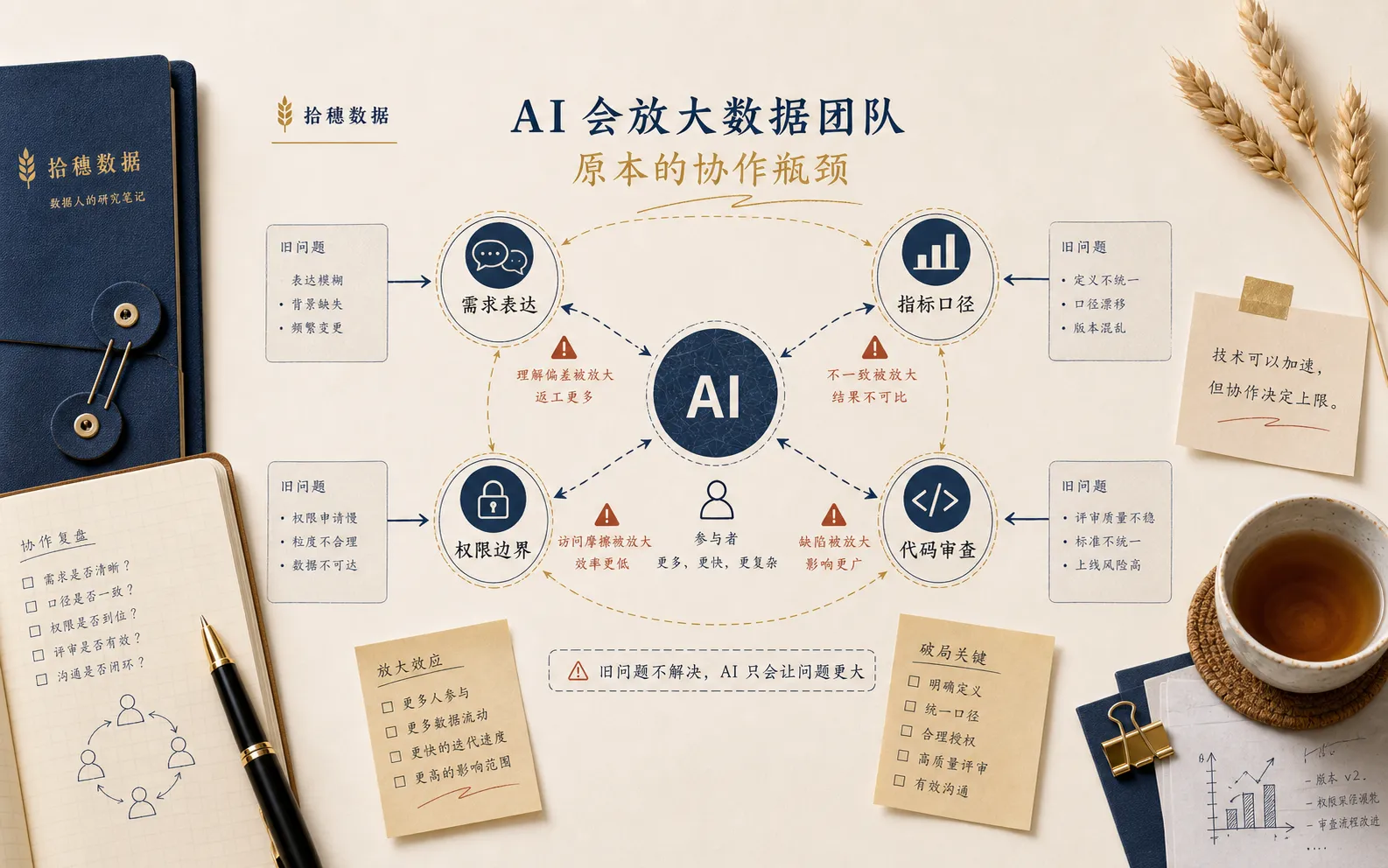
但真正放进团队之后,第一批被放大的,往往不是效率,而是协作问题。
这听起来有点反直觉。AI 不是来提高效率的吗?为什么先看到的是协作问题?
因为数据团队里的很多低效,本来就不是工具慢造成的。
它们来自需求没说清楚,指标口径不统一,字段没人维护,权限边界模糊,代码缺少审查,业务问题和数据问题之间缺少翻译。AI 进入之后,并不会自动消除这些问题。相反,它会更快地触碰它们。
AI 不是只多了一个工具,而是多了一个参与者
如果只是把 AI 当成一个更聪明的搜索框,问题还不明显。你问它一个 SQL 写法,它给你一段参考;你让它解释一个错误,它给你几个方向。这种场景下,AI 只是个人效率工具。
但一旦它进入团队流程,性质就变了。
比如业务同事通过自然语言问数,AI 直接生成查询。分析师让 AI 根据指标变化写日报。数据开发让 AI 根据上游表结构生成模型代码。主管让 AI 总结异常原因并推送到群里。
这时 AI 不再只是工具,它变成了协作链条里的一个参与者。
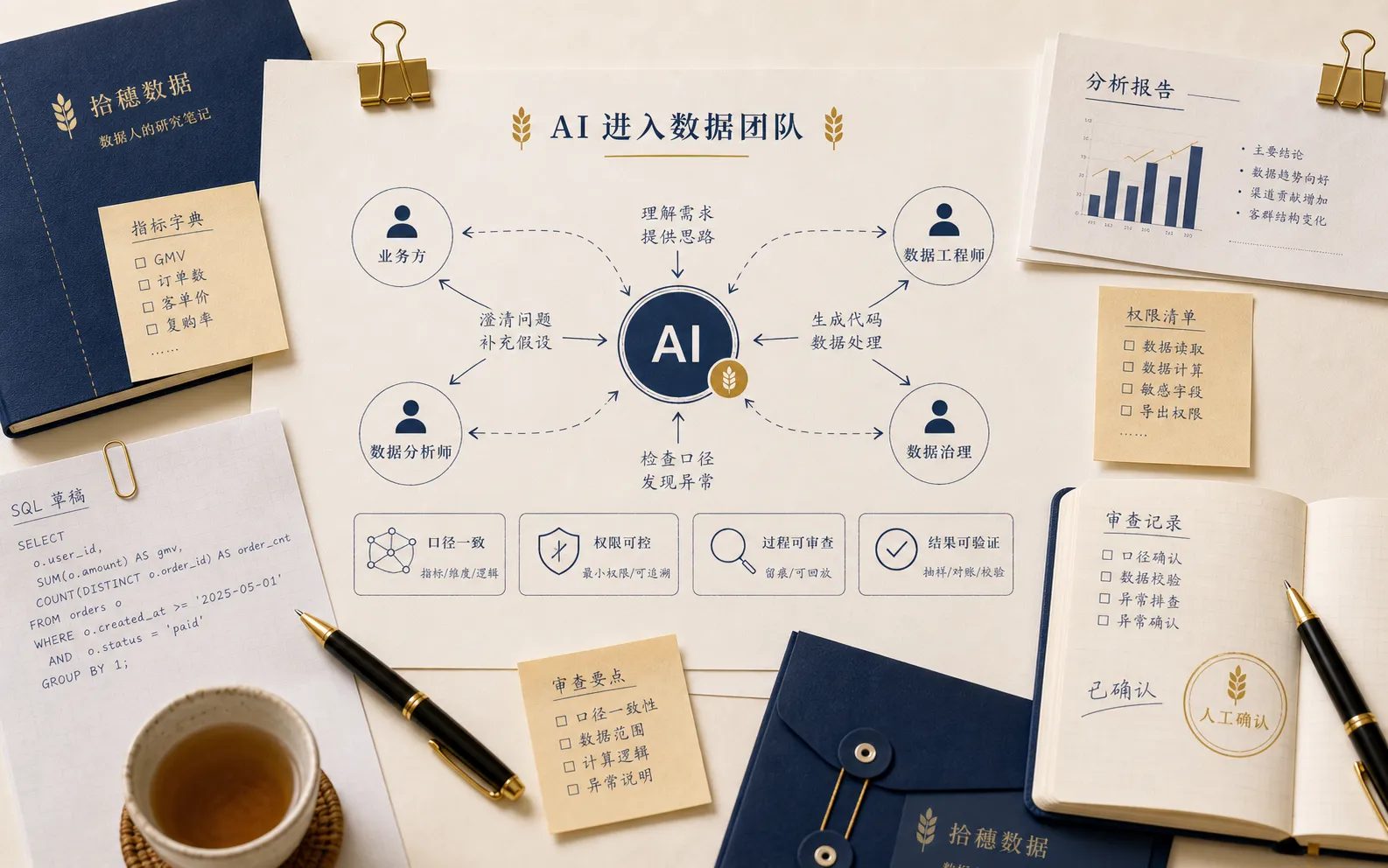
参与者意味着它会接收上下文、做出判断、产生中间结果,并影响其他人的工作。
问题也从“它会不会写 SQL”变成了“它基于什么口径写 SQL”“它有没有权限看到这些字段”“它生成的结论由谁负责”“它错了以后谁来发现”。
这些都不是模型能力本身能单独解决的。
需求越模糊,AI 越容易显得自信
人和人协作时,模糊需求有时会被追问。业务说“帮我看一下转化为什么下降”,分析师可能会问:哪个转化?哪段时间?哪个渠道?和什么比?
AI 很容易跳过这个过程。
用户问:“最近用户转化为什么下降?”它可能直接去查数据,生成一个看似完整的分析。内容里有图表、有原因、有建议,看起来很像那么回事。但如果转化定义错了,分析对象错了,比较基准错了,后面的所有漂亮表达都没有意义。
这就是 AI 在数据场景里的一个危险点:它会把不确定的问题包装成确定的答案。
团队原本需求澄清弱,AI 不会自动变强。它只会让“没澄清就开做”的速度更快。
口径治理差,AI 会把混乱扩散得更快
数据团队最常见的旧问题之一,是指标口径分裂。
同一个 GMV,财务一个口径,运营一个口径,增长一个口径;同一个活跃用户,不同看板算法不同;同一个新客,注册、下单、支付各有版本。过去这些问题已经麻烦,但传播速度有限。一个分析师用错口径,影响一份报告;一个看板口径不一致,影响一个会议。
AI 接入之后,传播速度会变快。
如果它能被很多人调用,又能自动生成 SQL、看板解释和文字结论,那么一个错误口径可能会被复制到更多场景里。
所以 AI 问数真正依赖的,不只是大模型,而是指标字典、血缘、元数据、权限、审计和口径责任人。
没有这些底座,AI 看起来越聪明,风险可能越大。
代码生成不是终点,审查机制才是关键
很多数据开发同学已经在用 AI 写 SQL、写 dbt model、写 Airflow DAG、写测试脚本。这个方向当然有价值。
但在团队里,代码生成只是第一步。
更关键的是:生成的代码怎么审查?谁确认业务口径?谁确认性能影响?谁确认不会把上游字段误用?谁确认不会扫全表、不会造成成本飙升、不会破坏已有任务?
如果原本团队就没有清楚的 review 机制,AI 只会让更多代码更快地产生。
更多代码不等于更多产出。有时只是更多需要维护的东西。
这和低代码平台曾经遇到的问题很像。低代码降低了创建门槛,但如果没有治理,最后会出现大量没人维护的流程、表单和报表。AI 也是一样。生成门槛下降后,治理的重要性会上升,而不是下降。
权限问题会从后台走到前台
还有一个容易被低估的问题,是权限。
过去数据权限通常藏在后台。谁能查哪张表,谁能看哪些字段,谁能导出明细,主要由平台、数仓、BI 系统控制。
AI 进入之后,权限会变得更复杂。
用户可能不是直接查表,而是问 AI:“帮我分析一下高价值客户流失原因。”AI 需要决定要不要访问客户标签、交易记录、客服工单、地区信息、甚至敏感字段。它可能生成中间摘要,也可能把字段含义暴露在回答里。
这时权限不再只是“能不能 select 某张表”,还包括“能不能推断某类信息”“能不能在摘要里出现某些字段”“能不能跨域组合数据”。
如果团队没有提前设计边界,AI 会把权限问题从后台带到前台。
真正的 AI 数据工作流,要重新画责任图
我不悲观。AI 进入数据团队是大方向,而且会带来实实在在的效率提升。
但前提是,我们不能只画工具链路图,还要画责任图。
谁提出问题?谁定义指标?谁授权数据?谁审查 SQL?谁确认结论?谁对发布出去的分析负责?AI 在其中负责生成、检索、解释、提醒,还是可以自动执行?哪些步骤必须有人确认?哪些步骤可以自动化?
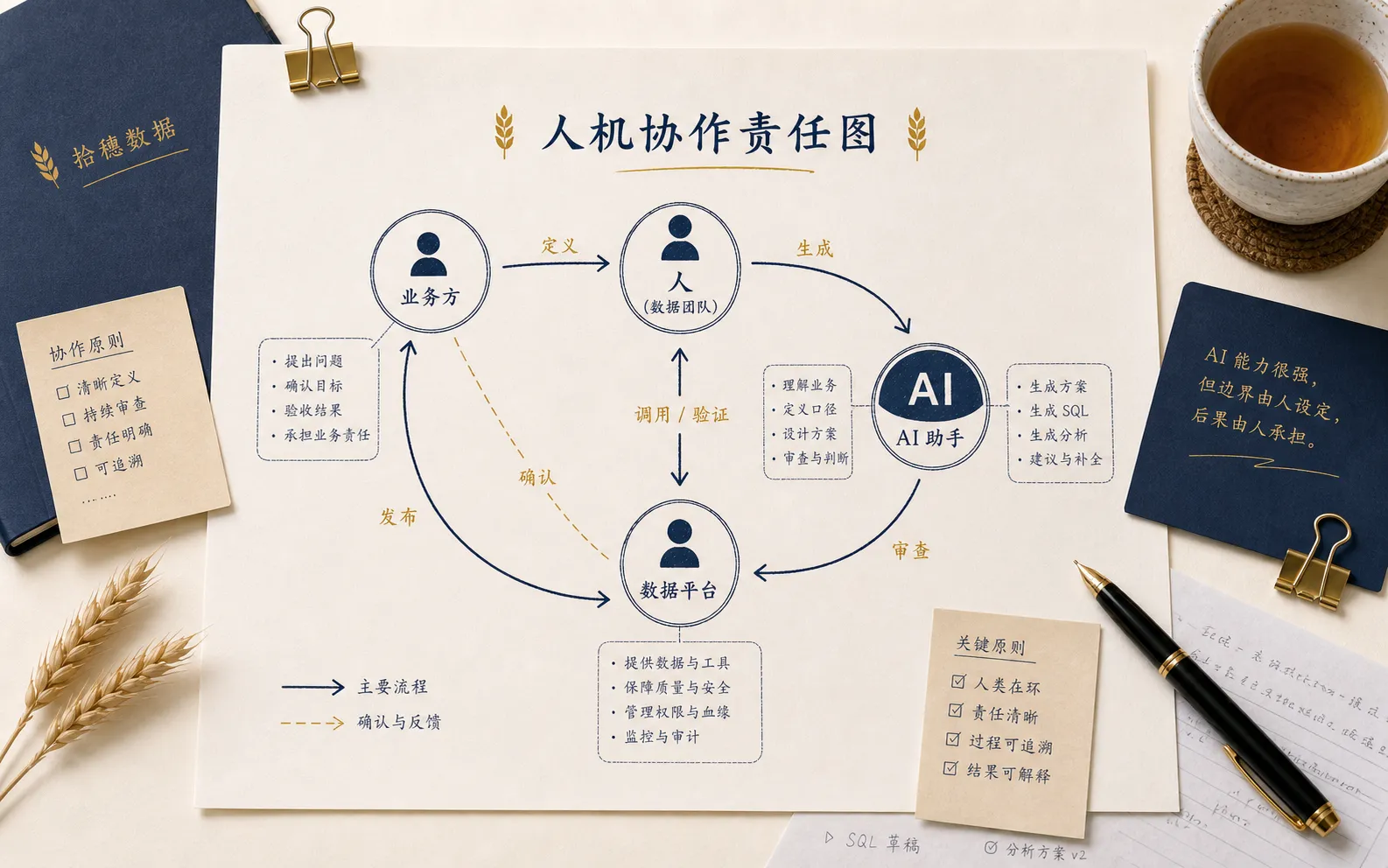
这张图画清楚,AI 才能安全地提高效率。
否则,团队只是把一个很会说话、很会生成内容的系统,接进了一堆原本就不清楚的流程里。
数据团队要补的,不只是 prompt 能力
现在很多人谈 AI 能力,会强调 prompt。会不会提问,会不会拆任务,会不会让模型按格式输出。
这些当然有用,但对数据团队来说还不够。
更重要的是四类能力。
第一,问题定义能力。能不能把业务问题变成清楚的数据问题。
第二,口径治理能力。能不能让指标、字段、模型有稳定解释。
第三,审查能力。能不能判断 AI 生成的 SQL、结论、代码是否可靠。
第四,协作设计能力。能不能把人、AI、平台、业务角色的责任边界画清楚。
这些能力过去就重要。AI 来了以后,只是让它们更重要。
效率会来,但不会自动来
AI 进入数据团队,最终一定会改变工作方式。
一些重复查询会被自动化,一些日报周报会被自动生成,一些异常分析会更快触发,一些代码和测试会由模型辅助完成。
但在那之前,团队会先遇到旧问题的新形态。
需求没说清,AI 会更快地产生错误答案。口径没治理,AI 会更快地复制混乱。权限没设计,AI 会更容易越过边界。审查机制没有建立,AI 会让不可维护的代码变多。
所以,别只问“AI 能不能提高数据团队效率”。
更应该问的是:我们现在的协作方式,配得上一个会自动生成答案的参与者吗?
如果答案还不确定,那第一步不是接更多工具,而是把需求、口径、权限、审查和责任重新梳理一遍。
AI 会放大效率,也会放大混乱。它放大哪一个,取决于团队原来是什么样子。

如果你想系统理解 AI 时代数据团队需要补哪些工程、治理和协作能力,可以继续看数据从业者全栈知识库。我会把 Agent、语义层、指标治理和数据工程实践逐步整理成更完整的学习路径。


