
业务说要上 AI 问数时,数据开发最危险的反应,是马上去接库。
“先连一下数据库试试。”
“先让模型跑起来看看。”
“先做个 Demo 给老板演示。”
这些话听起来很有行动力。会议室里也确实需要一点行动力。问题是,AI 问数一旦连上真实数据,就不只是一个技术原型。它会变成一个新的数据入口:业务不用看报表,不用提取数需求,不用等分析师,直接问一句,公司数据就开始回答。
这件事如果做得好,确实能省掉很多重复沟通。
如果做得不好,它也会把公司里原来藏在报表、口径、权限和人工解释里的问题,用更快的速度暴露出来。
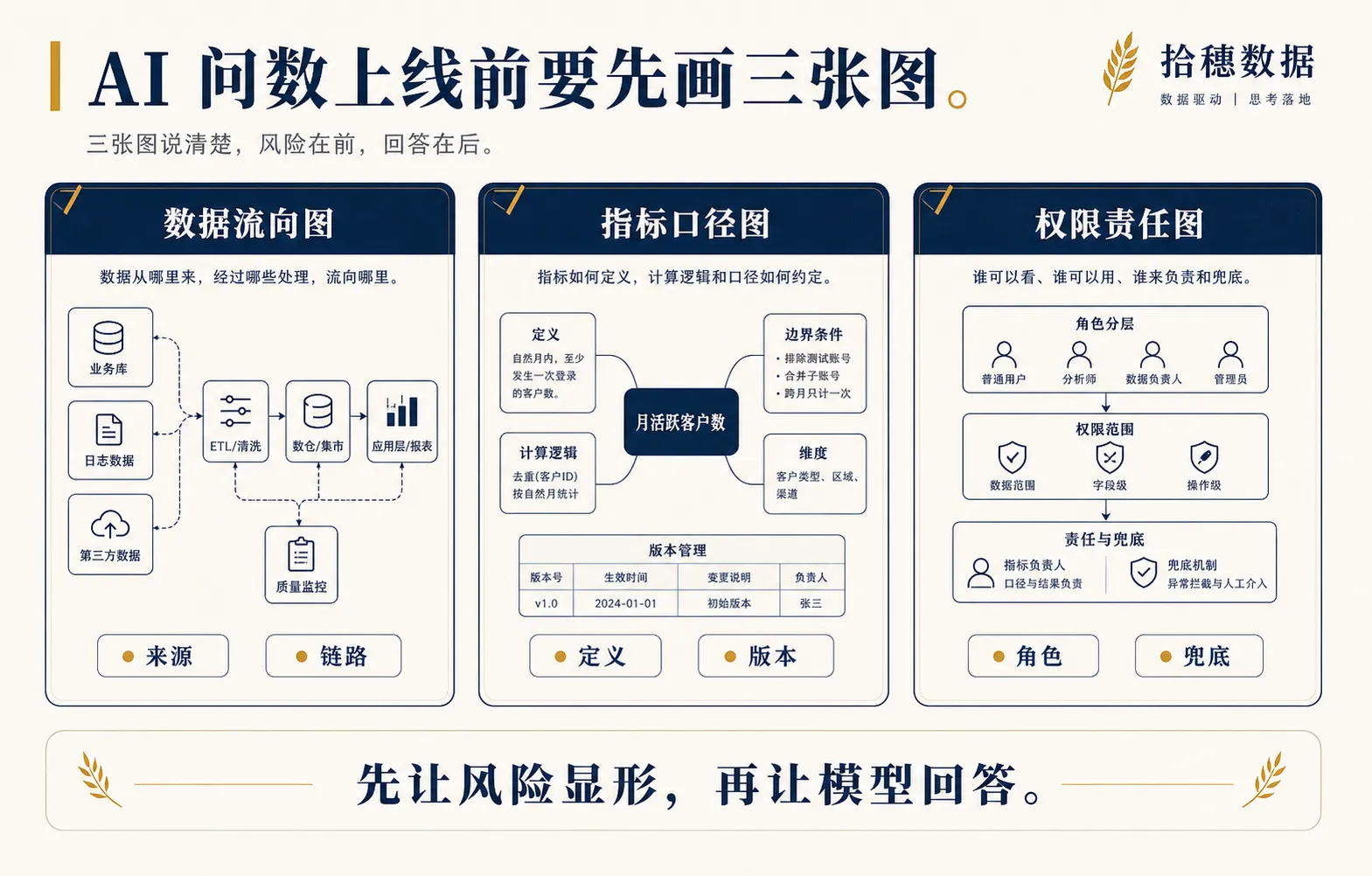
所以我给数据开发一个很朴素的建议:在接库之前,先画三张图。
第一张,数据流向图。
第二张,指标口径图。
第三张,权限责任图。
这三张图不是为了写文档好看。它们是上线前的风险显影工具。你把图画出来,很多原本靠一句“后面再优化”糊过去的问题,就会被迫摆到桌面上。
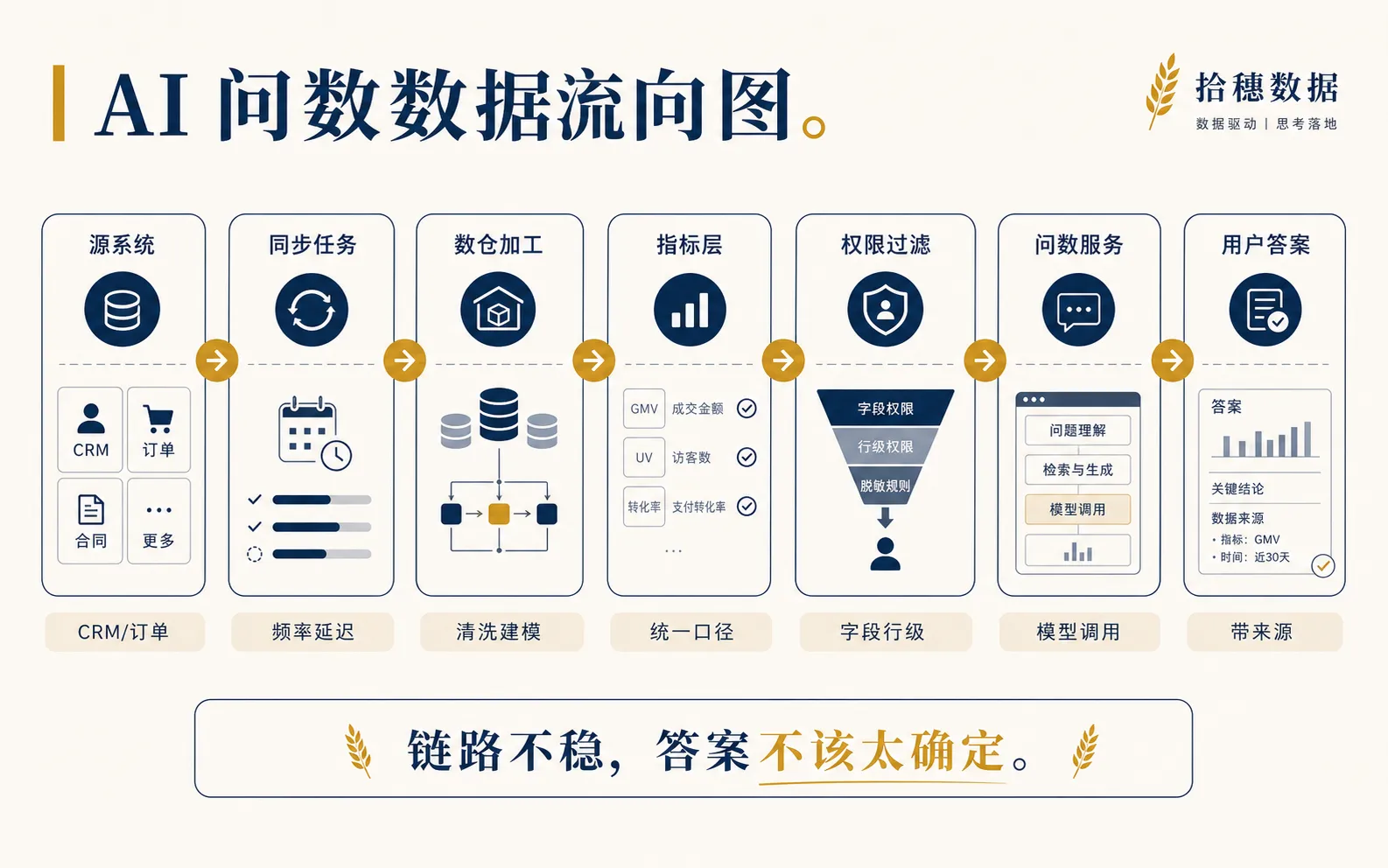
第一张图:数据流向图,先证明答案从哪里来
数据流向图要回答一个问题:AI 问数的答案,到底从哪里来?
很多团队一开始只画一条线:用户提问,模型生成 SQL,数据库返回结果,模型生成回答。
这条线太干净了。
真实的数据链路一般没这么干净。源系统可能有 CRM、订单、财务、客服、活动平台;中间有同步任务、ODS、DWD、DWS、ADS、指标平台、权限层;再往上才是问数服务、模型和前端入口。
你要画的不是“模型连数据库”。
你要画的是:从源头到回答,中间每一步经过了什么。
至少要包含 7 个节点:
- 源系统:数据最初来自哪里;
- 同步任务:通过什么任务进入数仓,频率和延迟是多少;
- 加工层级:经过哪些表、模型、宽表或指标层;
- 数据质量:哪些节点有校验,哪些只是裸奔;
- 权限过滤:哪些字段、行、指标会被过滤;
- 问数服务:模型到底能调用哪些数据产品;
- 用户答案:最终返回的是汇总、明细、解释,还是建议。
这张图画完后,你要在评审会上追问几个问题。
哪些表是手工维护的?哪些任务经常延迟?哪些字段来源不稳定?哪些指标表没有质量规则?哪些明细不应该进入问数范围?哪些数据在周末、月末、活动期间会有特殊口径?
如果这些问题答不上来,不要急着让模型背锅。
很多时候,AI 问数答错不是因为模型笨,而是输入链路本来就不稳。模型只是把不稳的链路包装成了一段很像人的话。
数据流向图的目标,是让团队承认:问数系统拿到的不是“公司真实数据”,而是一条经过加工、授权和解释的数据供给链路。
链路不稳,答案就不该显得太确定。
第二张图:指标口径图,先阻止一场未来的对数会
AI 问数最容易翻车的地方,不一定是复杂算法。
常常是简单指标。
销售额、订单数、活跃用户、转化率、毛利、新客、复购、ROI,这些词太常见,常见到大家误以为它们天然清楚。
可做过数据的人都知道,每个词下面都有坑。
销售额按下单算,还是按支付算?退款扣不扣?优惠券算不算?预售尾款归哪天?跨境订单是否单独处理?
活跃用户按登录算,还是按关键行为算?新客按注册算,还是首次支付算?毛利按财务口径,还是经营口径?


